![]()
The success of neural networks thus far has been built on bigger datasets, better theoretical models, and reduced training time. Sequential models, in particular, could stand to benefit from even more from these. To this end, we created OpenSeq2Seq – an open-source, TensorFlow-based toolkit. OpenSeq2Seq supports a wide range of off-the-shelf models, featuring multi-GPU and mixed-precision training that significantly reduces training time compared to other open-source frameworks. Benchmarks on machine translation and speech recognition tasks show that models built using OpenSeq2Seq give state-of-the-art performance at 1.5-3x faster training time, depending on the model and the training hyperparameters.
OpenSeq2Seq includes a large set of conversational AI examples which have been trained with mixed FP16/FP32 precision:
- Natural Language Translation: GNMT, Transformer, ConvS2S
- Speech Recognition: Wave2Letter, DeepSpeech2
- Speech Synthesis: Tacotron 2
- Language Modeling and transfer learning for NLP tasks
Overview of OpenSeq2Seq
Ever since the introduction of the sequence-to-sequence paradigm in 2014 (Cho et al., 2014[1]), its popularity continues to grow. Generally consisting of an encoder and a decoder, sequence-to-sequence models can be used for a wide variety of tasks. The canonical sequence-to-sequence model has RNNs for both encoder and decoder and works for tasks such as machine translation, text summarization, and dialog systems, as shown in figure 1. However, sequence models can be used for other tasks as well. For example, a neural network to solve a sentiment analysis task might consist of an RNN encoder and a softmax linear decoder. An image classification task might need an convolutional encoder and a softmax linear decoder. Even the number of encoders and decoders can be changed. For example, a model that translates from English to multiple languages might have one encoder with multiple decoders.

There have been a number of toolkits that use the sequence-to-sequence paradigm to construct and train models to solve various tasks. Some of the most popular include Tensor2Tensor[2], seq2seq[3], OpenNMT[4], and fairseq[5]. The first two are based on TensorFlow while the last two are based on PyTorch. These frameworks feature a modular design with many off-the-shelf modules that can be assembled into desirable models, lower the entrance barrier for people who want to use sequence-to-sequence models to solve their problems, and have helped push progress in both AI research and production.
OpenSeq2Seq builds upon the strengths of these existing frameworks with additional features to reduce the training time and make the API even easier to use. We chose to work with TensorFlow because TensorFlow has become the most widely-adopted machine learning framework and provides a great pipeline for bringing machine learning models into production. We created OpenSeq2Seq with the following goals in mind:
- Modular architecture to allows easily assembling of new models from available components
- Support for mixed-precision training[6], that utilizes Tensor Cores introduced in NVIDIA Volta GPUs
- Fast, simple-to-use, Horovod-based distributed training and data parallelism, supporting both multi-GPU and multi-node
Modular architecture
An OpenSeq2Seq model is described by a Python config file that defines the type of data reader, encoder, decoder, optimizer, loss function, regularization, hyperparameters that you want to use. For example, a config file to create an GNMT[7] model for machine translation might look like this:
base_params = { "batch_size_per_gpu": 32, "optimizer": "Adam", "lr_policy": exp_decay, "lr_policy_params": { "learning_rate": 0.0008, ... }, "encoder": GNMTLikeEncoderWithEmbedding, "encoder_params": { "core_cell": tf.nn.rnn_cell.LSTMCell, ... "encoder_layers": 7, "src_emb_size": 1024, }, "decoder": RNNDecoderWithAttention, "decoder_params": { "core_cell": tf.nn.rnn_cell.LSTMCell, ... }, "loss": BasicSequenceLoss, ... }
Currently, OpenSeq2Seq uses config files to create models for machine translation (GNMT, ConvS2S, Transformer), speech recognition (Deep Speech 2, Wav2Letter), speech synthesis (Tacotron 2), image classification (ResNets, AlexNet), language modeling, and transfer learning for sentiment analysis. These are stored in the folder example_configs. You can create a new model config using the modules available in the toolkit with basic knowledge in TensorFlow. It’s also straightforward to write a new module or to modify an existing module to meet your specific requirements.
OpenSeq2Seq also provides a variety of data layers that can process popular datasets, including WMT for machine translation, WikiText-103 for language modeling, LibriSpeech for speech recognition, SST and IMDB for sentiment analysis, LJ-Speech dataset for speech synthesis, and more.
Mixed-precision training
The speed of neural network training depends on three primary hardware factors: computational throughput, bandwidth, and GPU DRAM size. Large neural networks nowadays have tens, if not hundreds, of millions of parameters. They require massive arithmetic and memory resources to train in a reasonable timeframe. Accelerating training requires modern deep learning hardware to meet these growing resource requirements.
Tensor Cores, available on Volta and Turing GPUs, deliver the performance required to train large neural networks. It allows matrix-matrix multiplication, the operations at the core of neural network training and inferencing, to be done in both single-precision floating point (FP32) and half-precision floating point (FP16), as figure 2 shows. For training, Tensor Cores provide up to 12x higher peak TFLOPS compared to standard FP32 operations on P100. For inference, Tensor Cores provide up to 6x higher peak TFLOPS compared to standard FP16 operations on P100[8].
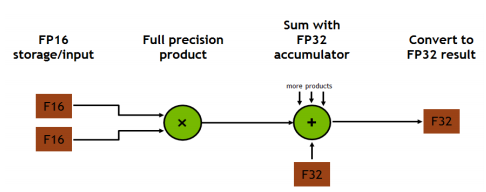
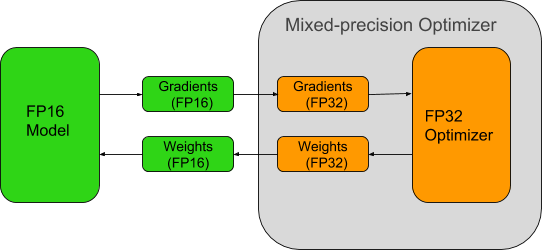
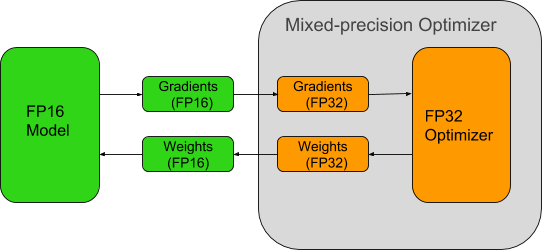
Taking advantage of the computational power available in Tensor Cores requires models to be trained using mixed-precision arithmetic. OpenSeq2Seq provides a simple interface to do so. When enabling mixed-precision training, the math is done in FP16, but the results are accumulated in FP32 as we see in figure 3. The results are converted to FP16 before being stored in memory. FP16 increases the computational throughput since current generation GPUs offer higher throughput for reduced precision math. In addition to speed improvements, mixed-precision also reduces the amount of memory required for training. This allows users to increase the size of batches or models, in turn increasing the learning capacity of the model and reduce the training time.
To prevent accuracy loss due to the reduced precision, two techniques are used:
- Automatically scale loss function to prevent gradients from underflow and overflow during back-propagation.
- Maintain a FP32 copy of weights to accumulate the gradients after each optimizer step.
Using these techniques, mixed-precision training can speed up training time significantly without losing model accuracy or having to modify hyperparameters. OpenSeq2Seq models such as Transformer, ConvS2S, and Wave2Letter see 1.5-3x speedup end-to-end when using mixed-precision on a Volta GPU compared to using only FP32.
To enable mixed-precision training in OpenSeq2Seq, simply change dtype parameter of model_params to “mixed” in your config file. You might need to enable loss scaling, either statically, by setting loss_scale parameter inside model_params to the desired number, or dynamically by setting loss_scaling parameter to “Backoff” or “LogMax”. You may need to pay attention to the types of the inputs and outputs to avoid mismatched types for certain types of computations. There’s no need to modify the architecture or hyper-parameters.
base_params = { ... "dtype": "mixed", # enabling static or dynamic loss scaling might improve model convergence # "loss_scale": 10.0, # "loss_scaling": "Backoff", ... }
Please visit our documentation for more details on how OpenSeq2Seq implements mixed-precision training.
Distributed training with Horovod
OpenSeq2Seq takes advantage of the two main approaches for distributed training:
- Parameter server-based approach (used in native TensorFlow towers)
-
- Builds a separate graph for each GPU
- Sometimes faster for 2 to 4 GPUs
-
- MPI-based approach[9] (used in Uber’s Horovod)
- Uses MPI and NVIDIA’s NCCL library to utilize NVLINK between GPUs
- Significantly faster for 8 to 16 GPUs
- Fast multi-node training
To use the first approach, you just need to update the configuration parameter num_gpus to the number of GPUs you want to use.
You need to install Horovod for GPU, MPI and NCCL to use Horovod ( detailed instructions can be found Horovod-for-GPU installation ). After that, all you need to do is set the parameter “use_horovod” to True in the config file and execute run.py script using mpirun or mpiexec. For example:
mpiexec --allow-run-as-root -np <num_gpus> python run.py --config_file=... --mode=train_eval --use_horovod=True --enable_logs
Horovod also allows you to enable multi-node execution. The only thing required from users is to define data “split” solely for evaluation and inference. Otherwise, users write exactly the same code for multi/single GPU or Horovod/Tower cases.
Horovod gives significantly better scaling for multi-GPU training comparing to Tensorflow native tower-based approach. The specific scaling depends on many factors such as data type, model size, compute amount. For example, the scaling factor for Transformer model is 0.7, while that number for ConvS2S is close to 0.875, as you can see in figure 4.
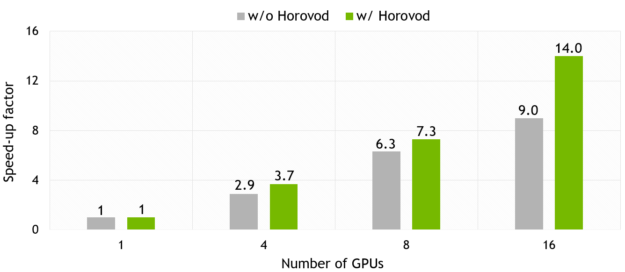
In the next part, we present the results of mixed-precision training for a number of popular models for the tasks of neural machine translation, speech recognition, and speech synthesis.
Models
Machine Translation
Currently OpenSeq2Seq has three models for machine translation:
All models have been trained on a WMT English-German dataset:
| Model | (newstest 2014) SacreBLEU |
| GNMT | 23 |
| ConvS2S | 25.0 |
| Transformer base | 26.6 |
| Transformer big | 27.5 |
The mixed precision training for these models is 1.5-2.7x[10] faster comparing to FP32.
Speech Recognition
OpenSeq2Seq has two models for the speech recognition task:
- Wave2Letter+ (fully convolutional model based on Facebook Wav2Letter)
- DeepSpeech2 (recurrent model originally proposed by Baidu)
These models were trained on LibriSpeech dataset only (~1k hours):
| Model | Greedy WER, % |
| Wave2Letter+ | 6.67 |
| DeepSpeech2 | 6.71 |
WERs (word error rates) were measured on dev-clean part of LibriSpeech dataset using a greedy decoder (that is, taking at each timestep the most probable character without any additional language model re-scoring).
Speech recognition models in OpenSeq2Seq have up to 3.6x faster training in mixed precision mode in comparison with FP32.
Speech Synthesis
OpenSeq2Seq supports Tacotron 2 with Griffin-Lim for speech synthesis. The model currently supports the LJSpeech dataset. We plan on additionally supporting the MAILABS dataset. Sample audio on both datasets can be found here.
Tacotron 2 can be trained 1.6x faster in mixed precision mode compared against FP32.
Conclusion
OpenSeq2Seq is a TensorFlow-based toolkit that builds upon the strengths of the currently available sequence-to-sequence toolkits with additional features that speed up the training of large neural networks up to 3x. It lets users switch to mixed-precision training that takes advantage of the computational power available in Tensor Cores with one single tag. It incorporates Horovod library to reduce training time for multi-GPU and multi-node systems.
It currently features a large set of state-of-the art models for speech recognition, machine translation, speech synthesis, language modeling, sentiment analysis, and more to come in the near future as our team is working hard to improve it. Its modular architecture allows quick development of new models out of existing blocks. The codebase is open-sourced. We welcome the contribution of the community to build new modules or update the existing ones. We’d also love to hear any request for new features, issues, or feedback you might have for us. Find us on GitHub: https://github.com/NVIDIA/OpenSeq2Seq.
OpenSeq2Seq is one of many open-source deep-learning projects that we’re developing at NVIDIA. If you want to work on projects like this, come join us: nvidia/careers. Interns are welcome!
[1] Cho, Kyunghyun, et al. “Learning phrase representations using RNN encoder-decoder for statistical machine translation.” arXiv preprint arXiv:1406.1078 (2014).
[2] Vaswani, Ashish, et al. “Tensor2tensor for neural machine translation.” arXiv preprint arXiv:1803.07416 (2018).
[3] Britz, Denny, et al. “Massive exploration of neural machine translation architectures.” arXiv preprint arXiv:1703.03906 (2017).
[4] Klein, Guillaume, et al. “Opennmt: Open-source toolkit for neural machine translation.” arXiv preprint arXiv:1701.02810 (2017).
[5] Gehring, Jonas, et al. “Convolutional sequence to sequence learning.” arXiv preprint arXiv:1705.03122 (2017).
[6] Micikevicius, Paulius, et al. “Mixed precision training.” arXiv preprint arXiv:1710.03740 (2017).
[7] Wu, Yonghui, et al. “Google’s neural machine translation system: Bridging the gap between human and machine translation.” arXiv preprint arXiv:1609.08144 (2016).
[8] NVIDIA, Tesla. “V100 GPU architecture. the world’s most advanced data center GPU. Version WP-08608-001_v1. 1.” NVIDIA. Aug (2017): 108.
[9] Meet Horovod: Uber’s Open Source Distributed Deep Learning Framework for TensorFlow
[10] The speed-up depends on the model parameters, batch size, host IO, etc