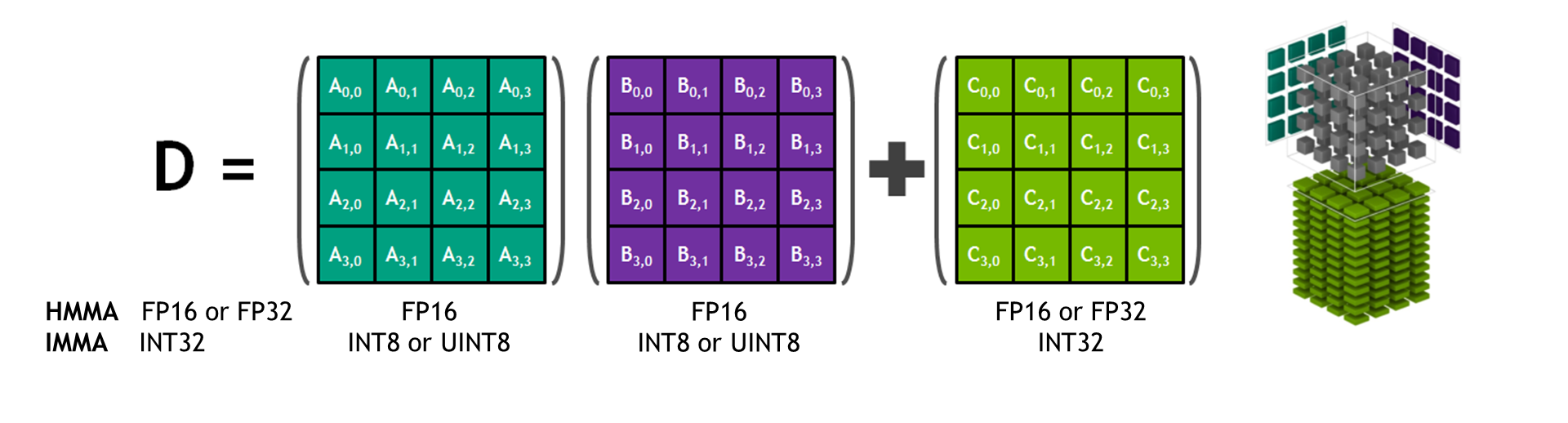
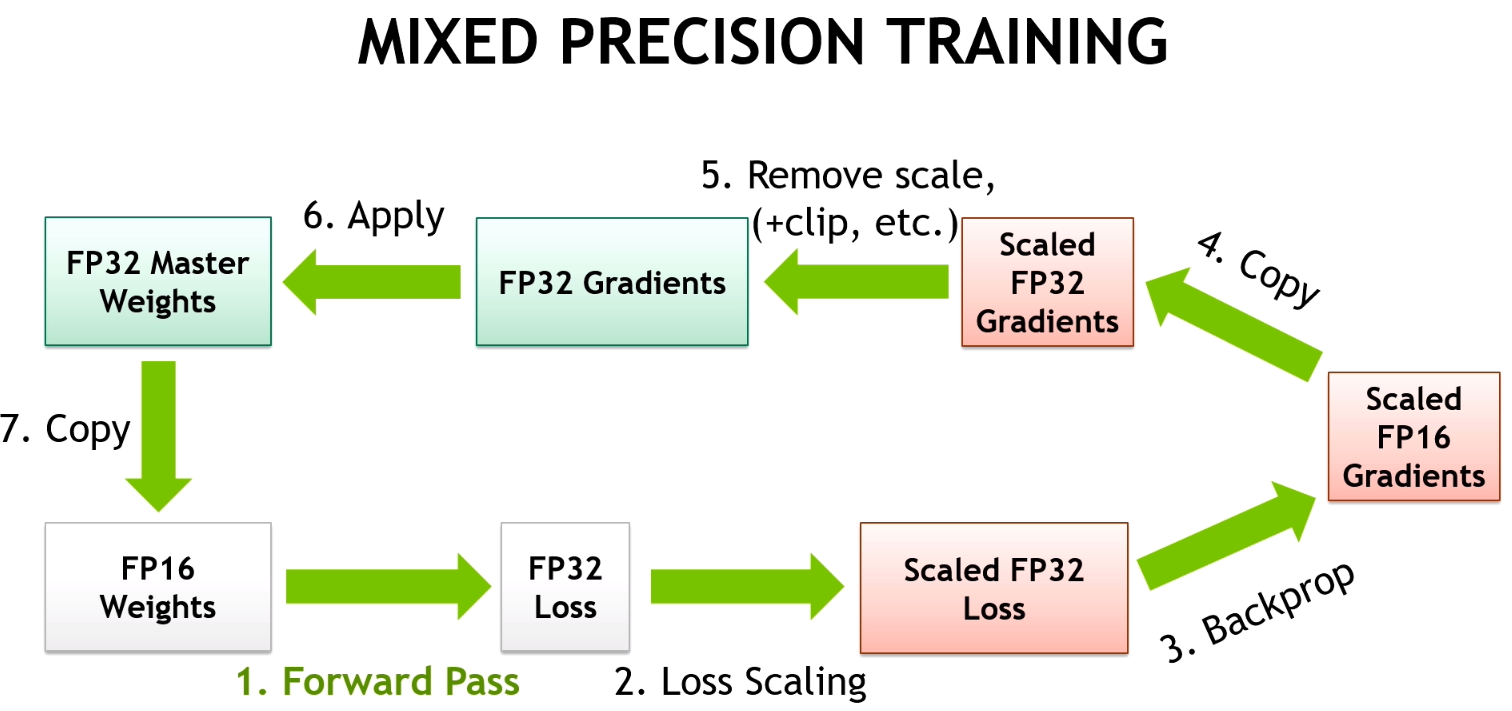
Mixed-Precision combines different numerical precisions in a computational method. Using precision lower than FP32 reduces memory usage, allowing deployment of larger neural networks. Data transfers take less time, and compute performance increases, especially on NVIDIA GPUs with Tensor Core support for that precision. Mixed-precision training of DNNs achieves two main objectives:
- Decreases the required amount of memory enabling the training of larger models or training with larger mini-batches
- Shortens the training/inference time by lowering the required resources through lower-precision arithmetic.
This video demonstrates how to train ResNet-50 with mixed-precision in TensorFlow.
Five Key Things in this Video:
- Mixed-precision training can improve compute performance and also reduce memory bandwidth while maintaining training accuracy.
- Computational operations run in FP16 to take full advantage of Tensor Cores.
- Master copy of the weights are maintained in FP32 to avoid imprecise weight updates during back propagation.
- Loss scaling is done to ensure gradients are safely represented in FP16 and loss is computed in FP32 to avoid overflow problems that arise with FP16.
- Best practice guidelines for Tensor Core acceleration: use multiples of eight for linear layer matrix dimensions and convolution channel counts.
Following Along and Getting Started
- Download NGC Tensorflow:18.06 container or newer
- Mixed-precision training documentation
- Learn how to utilize Tensor Cores with other Deep Learning Examples