Cloud computing is all about making resources available on demand, and its availability, flexibility, and lower cost has helped it take commercial computing by storm. At the Microsoft Build 2015 conference in San Francisco Microsoft revealed that its AzureC cloud computing platform is averaging over 90 thousand new customers per month; contains more than 1.4 million SQL databases being used by hosted applications, and over 50 trillion storage objects; and has 425 million users in the Active Directory system. Microsoft also said that the number of registered developers for Visual Studio Online services increased from 2 to 3 million in less than half a year.
Clearly there is increasing demand for GPU cloud computing. The number of use cases for GPUs in the cloud is growing, and there are a number of ways that GPU cloud computing may be useful to you, including
- If you need GPUs but don’t have access to them locally;
- If you are a data scientist and need to scale your machine learning code with multiple GPUs;
- If you are a developer and want to benchmark your applications on a more recent GPU with the latest CUDA technology; or
- If you want to use GPUs for video-creation services, 3D visualizations or game streaming.
Cloud computing services are provided at different levels: IaaS (Infrastructure as a Service), PaaS (Platform as a Service) and SaaS (Software as a Service). In this post I will consider two GPU cloud computing use cases, and walk you through setting up and running a sample cloud application using Alea GPU. The first one uses GPUs through IaaS to acclerate .NET applications with Alea GPU on Linux or Windows. The second use case shows how to build a PaaS for GPU computing with Alea GPU and MBrace. To learn more about Alea GPU, please read my earlier Parallel Forall post.
GPU Clouds
There are several GPU cloud computing providers. A list can be found on the NVIDIA web site. Most of them provide GPUs via IaaS.
In this blog post we will use the Amazon Elastic Compute Cloud EC2. Its G2 instance class provides resizable GPU compute capacity: the smaller g2.2xlarge instance has one GRID K520 GPU and the larger g2.8xlarge comes with four GRID K520 GPUs, each having 1536 cores. The older CG1 instances are equipped with Fermi M2050 GPUs. The on-demand prices of the g2.2xlarge and g2.8xlarge instances are $0.767 USD and $2.878 USD per hour for a Windows-based AMI in the region US East. Linux based AMIs are slightly cheaper. Instances can also be bought at spot prices which vary according to supply and demand. The spot price of the smaller instance can be as low as $0.10 USD and $0.40 USD or less for the larger instance. EC2 provides a wealth of preconfigured AMIs prepared either by Amazon, the community or third party companies on the AWS market place. Several AMIs for GPU instances can be found, offering various operating systems with pre-installed CUDA drivers or GPU applications such as machine learning, bitcoin mining, GPU-accelerated databases or business intelligence.
Other GPU cloud providers include RapidSwitch, which offers all kinds of GPUs from GRID K1, GRID K2 to Tesla K10, K20X and K40M; SoftLayer with GRID K2 and Tesla K10, or Penguin Computing with Tesla K40.
Using Alea GPU on Amazon EC2 Cloud
We described how to deploy Alea GPU on EC2 instances in a past blog post. We provide two community AMIs with up-to-date CUDA drivers and pre-installed tools so that you can start using Alea GPU right away:
- win2012r2-cuda70-vsc2013 with AMI ID ami-ab1ef4c0 is a Windows Server 2012 R2 image with Visual Studio 2013 Community Edition and TightVNC server (Figure 1).

- ubuntu14.04-cuda70-mono with AMI ID ami-670ee40c is an Ubuntu Trusty Tahr 14.04 image that comes with Mono (Figure 2).

Both AMIs include the GRID GPU driver and the CUDA toolkit version 7.0 and are available in the geographic location US East (Northern Virginia).
On Windows, the GRID K520 GPUs cannot be used with a Remote Desktop connection. The simple way around this is to use a VNC server. For this reason, the AMI win2012r2-cuda70-vsc2013 has a TightVNC server pre-installed. It is launched at system boot time as a Windows service on port 5900. The password for connection and configuration is vncxyz. These settings can be changed easily after booting.
After booting one of these images, you can start exploring Alea GPU. The easiest way is to download the Alea GPU Tutorial from GitHub. First, download a zip archive as Figure 3 shows.
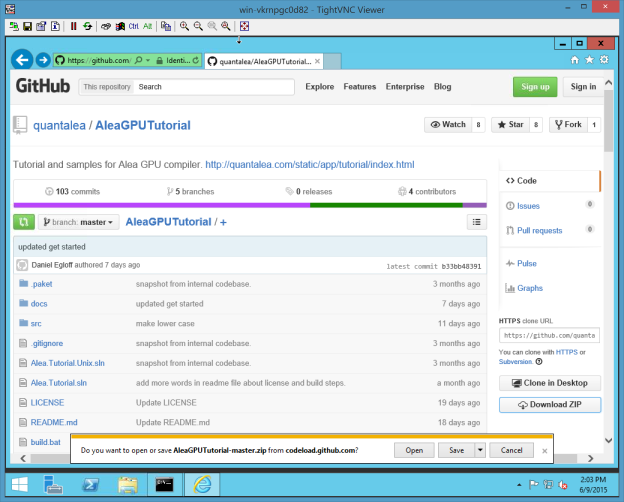
Unzip it and follow the instructions.
Note that the current version of Alea GPU is built against CUDA 6.5. You need to configure the Alea GPU tutorial project accordingly, so that the DLLs for cuBlas are found. Details are described in the user manual.
Important: the GRID K520 GPU is an enterprise GPU. To start using Alea GPU with this GPU, please first send a mail to support@quantalea.com or sales@quantalea.com to request a temporary demo license valid for Tesla and GRID GPUs and install it as described in the license manager section of the manual.
A GPU Platform as a Service with Alea GPU and MBrace
Now let’s look at how to build a GPU PaaS using Alea GPU and MBrace. MBrace is a simple programming framework for scalable cloud data scripting and programming with F# and C#. It introduces the concept of a cloud workflow which is a compositional and declarative approach to describing parallel distributed computations. Cloud workflows are deferred computations; their execution can only be performed in a distributed environment. The MBrace runtime is a scalable cluster infrastructure that handles the orchestration and execution of cloud workflows on distributed compute resources.
Alea GPU and MBrace can be integrated to facilitate the creation of GPU services. Follow the five steps in the MBrace Starter Kit README here to provision your MBrace service on Azure.
Alternatively you can also provision the MBrace service using Visual Studio as explained here.
Unfortunately at the time of writing Azure does not have GPU instances, but we can easily add Amazon EC2 GPU instances to an MBrace cluster. For this we have prepared an Amazon EC2 AMI alea-gpu-mbrace-win2012r2 with AMI ID ami-5fb94934 which is a Windows Server 2012 R2 image with Visual Studio 2013 Community Edition, TightVNC server, Alea GPU tools and MBrace local worker package (Figure 7).

This AMI is set up to be used as a GPU worker in an MBrace cluster. Create a running instance. Connect to the instance with a VNC client on port 5900 with password vncxyz. First you will need to install a valid Alea GPU license for Tesla and GRID GPUs as described previously. Send a mail to support@quantalea.com or sales@quantalea.com to request a temporary demo license. On the desktop you will find a shortcut to a command promt which starts up in the Alea GPU tools directory containing the license manager. Install the license using the following command.
LicenseManager.exe install -l
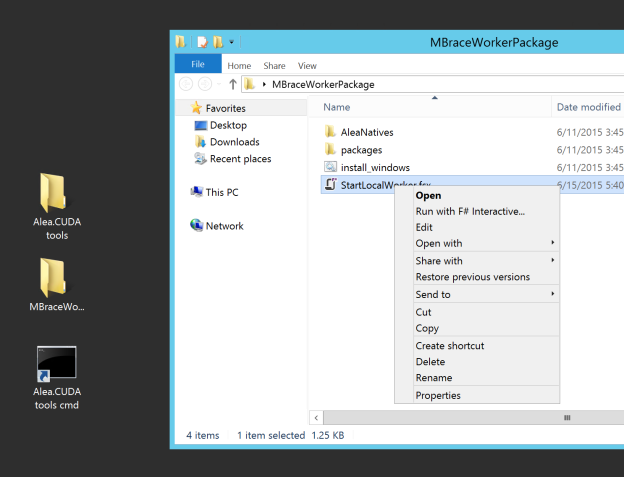
Then open the folder MBraceWorkerPackage and open the the F# script StartLocalWorker.fsx in your preferred text editor. Look for the following lines and replace the strings with those you captured from the cluster endpoints dialog before (Figure 5).
// place your connection strings here let myStorageConnectionString = "your storage connection string" let myServiceBusConnectionString = "your service bus connection string"
Save the file, then right click and choose “Run with F# Interactive…”, as Figure 8 shows.
This will start a local worker and bind it to your MBrace cloud. Repeat this process for every GPU worker you want to attach to the MBrace cloud. Note that if you connect to the instance with RDP, starting a local worker that can access the GPU will fail.
Distributed Monte Carlo in the Cloud
To test drive this GPU PaaS we created a demo application with Alea GPU in C# and F# which calculates 
The sample computes a large number of Monte Carlo samples to approximate calcPI implements the calculation for a task. After setting up the resources, it loops over multiple streams, fills the buffer of random points, launches the kernel to identify which points are inside the circle in the positive quadrant and calculates the total number of these points. Finally all the results for the streams are averaged.
let calcPI (param:CalcParam) =
if canDoGPUCalc.Value then
let worker = Worker.Default
// switch to the gpu worker thread to execute GPU kernels
worker.Eval <| fun _ ->
let seed = param.Seed
let numStreams = param.NumStreams
let numDimensions = 2
let numPoints = param.NumPoints
let numSMs = worker.Device.Attributes.MULTIPROCESSOR_COUNT
let startStreamId = param.StartStreamId
let stopStreamId = param.StopStreamId
let random = param.GetRandom seed numStreams numDimensions
use reduce = DeviceSumModuleI32.Default.Create(numPoints)
use points = random.AllocCUDAStreamBuffer(numPoints)
use numPointsInside = worker.Malloc(numPoints)
let pointsX = points.Ptr
let pointsY = points.Ptr + numPoints
let lp = LaunchParam(numSMs * 8, 256)
let pi =
[| startStreamId .. stopStreamId |]
|> Array.map (fun streamId ->
random.Fill(streamId, numPoints, points)
worker.Launch <@ kernelCountInside @> lp pointsX pointsY numPoints numPointsInside.Ptr
let numPointsInside = reduce.Reduce(numPointsInside.Ptr, numPoints)
4.0 * (float numPointsInside) / (float numPoints))
|> Array.average
printfn "Random(%s) Streams(%d-%d/%d) Points(%d) : %f" (random.GetType().Namespace) (startStreamId+1) (stopStreamId+1) numStreams numPoints pi
Some pi
// if no gpu return None
else None
The sample creates an array of task parameters and uses CloudFlow.map to lazily apply the calcPI function, and then runs it on the cloud with cluster.Run, and then chooses the valid simulation results and computes their average.
let pi =
[| 0..numTasks - 1 |]
|> Array.map (fun taskId ->
{ Seed = seed
NumStreams = numStreams
NumPoints = numPointsPerStream
StartStreamId = taskId * numStreamsPerTask
StopStreamId = (taskId + 1) * numStreamsPerTask - 1
GetRandom = rng } )
|> CloudFlow.ofArray
|> CloudFlow.map calcPI
|> CloudFlow.toArray
|> cluster.Run
|> Array.choose id
|> Array.average
Before you open the project, execute InstallWindows.bat in the project root folder. This will download the required NuGet packages and prepare everything so that your local machine can be added as a worker if it contains an NVIDIA GPU. Then open the project, select Release mode and build the solution. Details can be found in the README.
Running the Example
There are scripts to launch the computations in the directory CloudScripts. First there is a script to monitor the status of the GPU cloud service. In a command prompt execute
fsi Monitor.fsx
This displays the workers and the processes on the GPU cloud. To run the example, first boot one GPU instance and launch the calculations with one worker. Either open CalcPI_FS.fsx or CalcPI_CS.fsx in Visual Studio, select all, right click and choose Execute in Interactive or execute it on the command line with fsi CalcPI_FS.fsx. Figure 9 shows the output of the monitoring script. The jobs are posted to the cloud, and the MBrace runtime uploads all required assemblies to all the cloud nodes.

Then the process is executed, as Figure 10 shows.

After a while the job status changes to completed and the total cloud execution time is calculated, as Figure 11 shows.

Now add seven more instances to the cloud, for a total of eight. Do not forget to install a license and add your connection strings to StartLocalWorker.fsx before you execute it. Figure 12 shows the output.
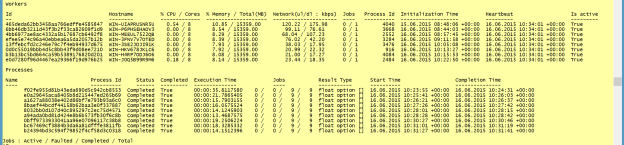
If you are running your calculation for the first time with extra nodes the runtime needs to upload all assemblies to the new nodes again. The calculation time goes down from about 35 seconds to 14 seconds. In this example scalability is not optimal because of network latencies between Azure and AWS.
Conclusion
We have shown how easy it is to leverage GPU cloud computing with Alea GPU, Azure, and AWS. The first example used IaaS to access remote GPU capacity. The second example showed how to implement a GPU PaaS with minimal effort on the .NET stack with a combination of Alea GPU and MBrace. Booting the node is straightforward, however launching the local worker is still a manual process which has to be done with a VNC connection. This can be automated further for larger installations. There are several limitations of the current setup:
- The current setup with MBrace service bus on Azure and GPU nodes on EC2 does not allow special high-speed network connections for node-to-node peer communication.
- The GRID K520 cannot be run in TCC mode and it is therefore not possible to start GPU applications as Windows services, which would simplify deployment.
- The scalability is not very good because of network latency between AWS and Azure.
We hope that Azure will offer modern GPU hardware in the near future, which would allow us to build more sophisticated and user-friendly GPU PaaS infrastructures.
If you want to learn more about Alea GPU be sure to read my earlier Parallel Forall post, Accelerate .NET Applications with Alea GPU.