The pace of AI adoption across diverse industries depends on maximizing data scientists’ productivity. NVIDIA releases optimized NGC containers every month with improved performance for deep learning frameworks and libraries, helping scientists maximize their potential. NVIDIA continuously invests in the full data science stack, including GPU architecture, systems, and software stacks. This holistic approach provides the best performance for deep learning model training as proven by NVIDIA winning all six benchmarks submitted to MLPerf, the first industry-wide AI benchmark. NVIDIA accomplished this feat by introducing several new generations of GPU architectures in recent years, culminating in the Tensor Core architecture on the Volta and Turing GPUs, which include native support for mixed-precision calculations. NVIDIA accomplished these records on MXNet and PyTorch frameworks, showcasing the versatility of our platform. Automatic mixed precision in popular deep learning frameworks provides 3x faster training performance on Tensor Cores by adding one or two line(s) of code to your application. Learn more on the automatic mixed precision page.
The NeurIPS 2018 conference proved to be an opportune time for deep learning scientists to learn about some of the significant recent performance improvements in NVIDIA’s optimized containers that accelerate a variety of deep learning models. Let’s look at improvements to the latest 18.11 release of NVIDIA GPU Cloud (NGC) deep learning framework containers and key libraries. The new release builds on earlier enhancements, which you can read about in the Volta Tensor Core GPU Achieves New AI Performance Milestones post.
Optimized Frameworks
MXNet
This latest release improves the performance of training deep learning models at large scale, where it is crucial that GPU training performance is optimized across a large range of batch sizes. As studies have shown, limits exist to how large the total training batch size can be across all processors before the final training accuracy achieved starts to degrade. Thus, when scaling to a large number of GPUs, adding more GPUs decreases the batch size processed per GPU once the total batch size limit is reached. So, we introduced several improvements to the MXNet framework in the 18.11 NGC container to optimize performance across a variety of training batch sizes, and especially smaller ones, not only large batch sizes:
- As the batch size decreases, the overhead of synchronizing each training iteration with the CPU increases. Previously, the MXNet framework was synchronizing the GPU with the CPU after each operation. The overhead of this repeated synchronization adversely affected performance when training with a small batch size per GPU. We improved MXNet to aggressively combine multiple consecutive GPU operations together before a synchronization with the CPU, reducing this overhead.
- We introduced new fused operators, such as BatchNorm-ReLU and BatchNorm-Add-ReLU, which eliminate unnecessary round trips to GPU memory. This improves performance by executing simple operations (such as elementwise Add or ReLU) essentially for free, without extra memory transfers, in the same kernel that executes the batch normalization. These are especially useful for most modern convolutional network architectures for image tasks.
- Previously, the SGD optimizer update step was calling separate kernels for updating each layer’s parameters. The new 18.11 container aggregates the SGD updates for multiple layers into a single GPU kernel to reduce overhead. The MXNet runtime automatically applies this optimization when running MXNet with Horovod for multi-GPU and multi-node training.
- NVIDIA achieved the world’s fastest time to solution, 6.3 minutes on MLPerf for ResNet50 v1.5, by employing these improvements for MXNet.
These optimizations enabled a throughput of 1060 images/sec when training ResNet-50 with a batch size of 32 using Tensor Core mixed-precision on a single Tesla V100 GPU using the 18.11 MXNet container as compared to 660 images/sec with the 18.09 MXNet container.
You can find the most up to date performance results here.
We worked closely with Amazon and the MXNet development community to integrate the popular Horovod communication library to improve performance when running on a large number of GPUs. The Horovod library uses the NVIDIA Collective Communications Library (NCCL), which incorporates the allreduce approach to handling distributed parameters. This eliminates performance bottlenecks with the native MXNet distributed kvstore approach.
We are currently merging our improvements to the upstream MXNet and Horovod repositories so that their user communities can benefit from these improvements.
TensorFlow
The 18.11 TensorFlow NGC container includes the latest version of Tensorflow 1.12. This offers major improvements for GPU performance enabled by the experimental XLA compiler. Google outlines XLA in their recent blog, including instructions on how to enable it. XLA delivers significant speedups by fusing multiple operations into a single GPU kernel, eliminating the need for multiple memory transfers, dramatically improving performance. The XLA compiler is experimental at this time, with caveats outlined in the Google blog post. However, promising performance improvements of up to 3X on Google’s internal models with GPUs have been recorded.
Furthermore, the 18.11 NGC Tensorflow container integrates the latest TensorRT 5.0.2, enabling data scientists to easily deploy their trained model with optimized inference performance. TensorRT addresses the specific challenges for inference performance. It efficiently executes with small batch sizes with low latencies, down to a batch size of 1. TensorRT 5.0.2 supports low-precision data types, such as 16-bit floating point or 8-bit integers.
On a related note, NVIDIA provides profilers with powerful insights into CUDA application performance. However, while these profiles provide voluminous data about the low-level performance of the application, it is often hard to interpret for a TensorFlow user. That’s because the profile doesn’t correlate its output back to the original graph the TensorFlow user built. We enhanced TensorFlow’s graph executor (using the NVIDIA profiler NVTX extensions) to emit markers into profiles collected with CUDA profilers such as nvprof, simplifying performance analysis.
These markers show the time range spent in each graph operator and can be used by power users to easily identify compute kernels with their associated TensorFlow layers. Previously, the profile would only show the kernel launches and host/device memory operations (the Runtime API row). Now, TensorFlow adds markers into the profile with meaningfully names in relation to the TensorFlow graph, as shown in figure 1. This allows users to map GPU execution profile events to specific nodes in their model graph.

PyTorch
NVIDIA works closely with the PyTorch development community to continually improve performance of training deep learning models on Volta Tensor Core GPUs. Apex is a set of light weight extensions to PyTorch that are maintained by NVIDIA to accelerate training. These extensions are currently being evaluated for merging directly into the main PyTorch repository. However, the PyTorch NGC container comes pre-built with Apex utilities, so data scientists and researchers can easily start using them. Learn more about Apex capabilities in this blog. We recently added some performance-oriented utilities in addition to the automatic mixed precision utilities and distributed training wrapper originally included with Apex.
First, we added a new fused implementation of the Adam optimizer. The existing default PyTorch implementation requires several redundant passes to and from GPU device memory. These redundant passes create significant overhead, especially when scaling training across many GPUs in a data parallel fashion. The fused Adam optimizer in Apex eliminates these redundant passes, improving performance. For example, an NVIDIA-optimized version of the Transformer network using the fused Apex implementation delivered end-to-end training speedups between 5% and 7% over the existing implementation in PyTorch. The observed end-to-end speedups ranged from 6% to as high as 45% (for small batch sizes) for an optimized version of Google Neural Machine Translation (GNMT).
Next, we added an optimized implementation of layer normalization. For that same Transformer network, Apex’s layer normalization delivered a 4% end-to-end speedup in training performance.
Finally, we augmented the distributed data parallel wrapper, for use in multi-GPU and multi-node training. This included significant under-the-hood performance tuning as well as new user-facing options to improve performance and accuracy. One example is the “delay_allreduce” option. This option buffers all the gradients from all the layers to be accumulated across the GPUs,then link them together once the backward pass is completed.
While this option omits the opportunity to overlap communications of already calculated gradients with computation of gradients of other model layers, it can improve performance in cases where persistent kernel implementations are used, including batch normalization and certain cuDNN RNNs. The details of the “delay_allreduce” option, as well as other user-facing options, can be found in the Apex documentation.
These PyTorch optimizations enabled NVIDIA to caputre multiple speed records on MLPerf, which you can read about here.
Performance Libraries
cuDNN
The latest version of cuDNN 7.4.1 contains significant performance improvements for NHWC data layouts, persistent RNN data gradient calculation, strided convolution activation gradient calculation, and improved heuristics in the cudnnGetConvolution<*>() set of APIs.
A key to improved performance from Volta Tensor Cores is reducing the number of tensor transpositions needed when training a model, as discussed in this previous blog post. The natural tensor data layout for convolutions with Tensor Cores is the NHWC layout. Over the last few releases of cuDNN, we also added highly optimized kernels that operate on the NHWC data layout for a series of memory bound operations such as add tensor, op tensor, activation, average pooling, and batch normalization. These are all available in the latest cuDNN 7.4.1 release.
These new implementations enable more efficient memory access and can reach close to peak memory bandwidth in many typical use-cases. In addition, the new extended batch normalization API also supports optional fused element-wise add activation saving several round-trips to and from global memory, noticeably improving performance.These fused operations will speed up training of networks with batch normalization and skip connections. This includes most of modern image networks, for classification, detection, segmentation, and other tasks.
As an example, performance increased more than 20% using cuDNN’s new NHWC and fused batch normalization support when training the SSD network (with a ResNet-34 backbone) on a DGX-1V, with 8 Tesla V100 GPUs, as compared to running with the NCHW data layout and without the fused batch normalization.
As discussed earlier in this blog, training deep neural networks at scale requires processing smaller batch sizes than the maximum that can fit on each GPU. This provides a new opportunity for optimization, especially models with RNNs (recurrent neural networks). When the batch size is small, the cuDNN library can use RNN implementations which use persistent algorithms in certain cases.
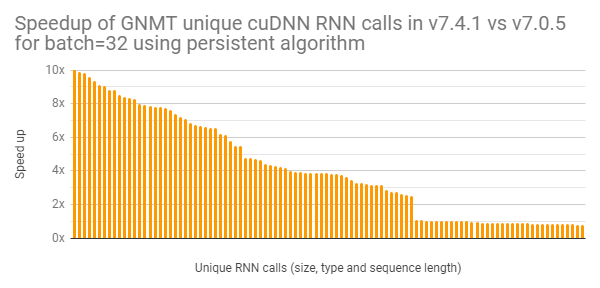
(This post explains the performance benefits of persistent algorithms for RNN implementations.) While cuDNN has supported persistent RNNs for several releases, we recently optimized them heavily for Tensor Cores. The graph in figure 2 shows one example of the performance improvements we’ve made to the persistent RNNs used for the GNMT language translation model running with a batch size of 32 on a Tesla V100. As the chart shows, the performance of many of the RNN calls have significantly improved in performance.
The latest cuDNN 7.4.1 significantly enhanced the performance of calculating the activation gradients. Previously, unit-stride cases were handled by highly specialized and fast kernels, whereas the non-unit stride cases fell back to more generalized but slower kernel implementations. The latest cuDNN addresses this gap and has much improved performance for non-unit stride cases. With this enhancement, the relevant activation gradient computation operations in networks such as Deep Speech 2, and Inception v3, are improved by up to 25x.
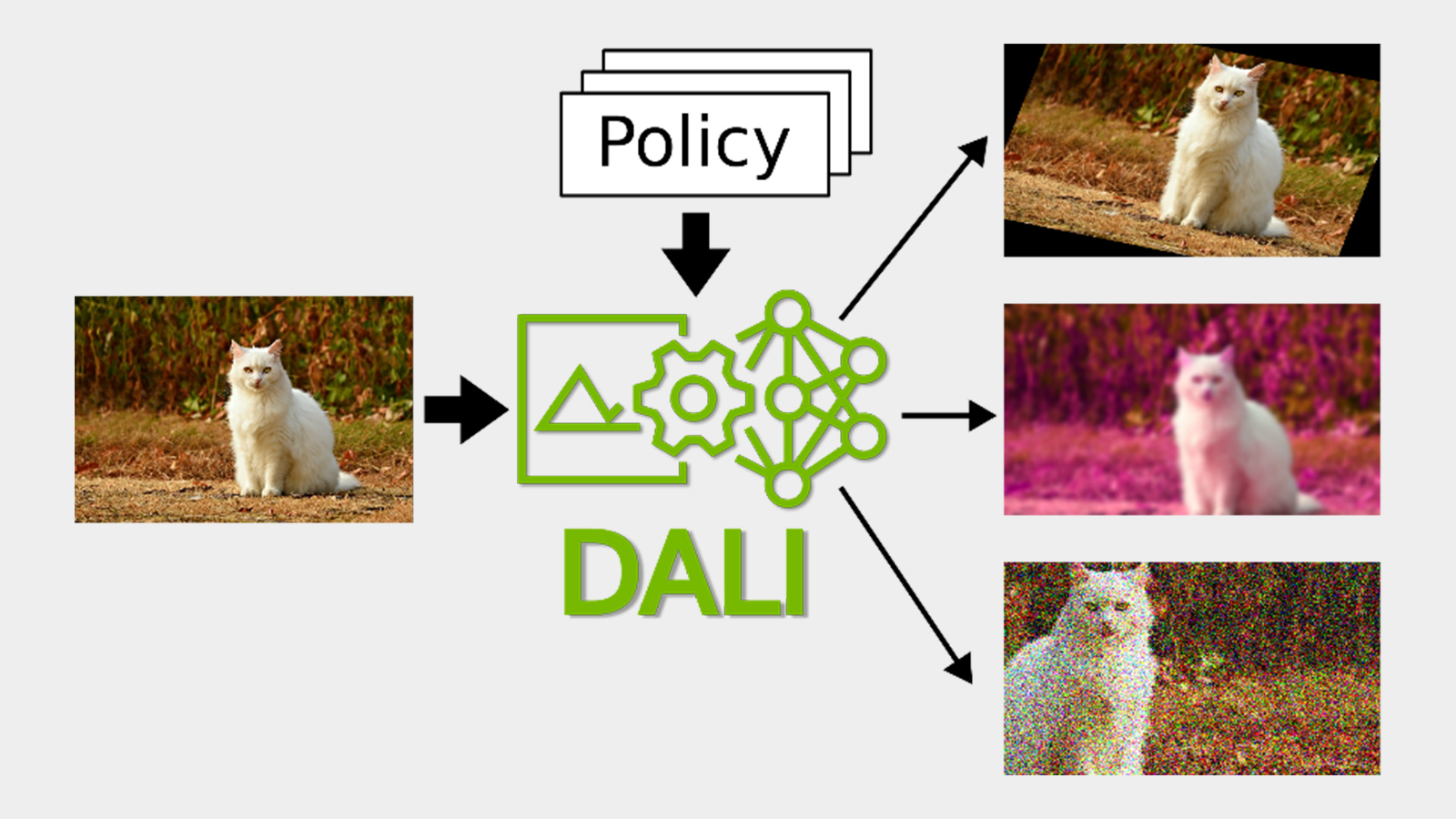
DALI
Training and inference of models for vision tasks (such as classification, object detection, segmentation, and others) requires a significant and involved data input and augmentation pipeline, When running at scale with optimized code, this pipeline can quickly become a bottleneck in overall performance when multiple GPUs have to wait for the CPU to prepare the data. Even when utilizing multiple CPU cores for this processing, the CPU can struggle to provide data quickly enough for the GPUs. This results in periods of idle GPU time spent waiting on the CPU to complete its tasks. It becomes advantageous to move these data pipelines from the CPU to the GPU. DALI, an open source, framework agnostic, library for GPU accelerated data input and augmentation pipelines has been developed to address this issue, migrating work from the CPU to the GPU.
Let’s take the example of the popular Single Shot Detector (SSD) model. The data input pipeline has multiple stages, as shown in figure 3.

All of these pipeline stages look fairly standard across computer vision tasks, except SSD Random (IoU- Intersection over Union- based) Crop which is SSD specific. Newly-added operators in DALI provide a fast GPU based pipeline for the entire workflow by providing access to the COCO dataset (COCOReader), IoU-based cropping (SSDRandomCrop) and bounding-box flipping (BbFlip).
Conclusion
Researchers can take advantage of the latest performance enhancements discussed in this blog to accelerate their deep learning training with minimal effort. Jumpstart your AI research by visiting NVIDIA GPU Cloud (NGC) to download the fully optimized deep learning framework containers, pre-trained AI models, and model scripts, giving you access to the world’s highest-performing deep learning solutions. In addition, the individual libraries are also available with the enhancements in cuDNN andDALI.