Think of a sentence and repeat it aloud three times. If someone recorded this speech and performed a point-by-point comparison, they would find that no single utterance exactly matched the others. Similar to different resolutions, angles, and lighting conditions in imagery, human speech varies with respect to timing, pitch, amplitude, and even how base units of speech – phonemes and morphemes – tie together to create words. As such, machine understanding of human speech has captivated and challenged researchers and inventors alike dating back to the Renaissance.
Automatic speech recognition (ASR), the first stage of the conversational AI pipeline, is a field of speech processing concerned with speech-to-text transformations. ASR helps us compose hands-free text messages to friends and individuals who are deaf or hard of hearing to interact with spoken-word communications. ASR also provides a framework for machine understanding. Human language becomes searchable and actionable, giving developers the ability to derive advanced analytics like speaker identification or sentiment analysis.
Introducing the Kaldi ASR Framework
The Kaldi Speech Recognition Toolkit project began in 2009 at Johns Hopkins University with the intent to develop techniques to reduce both the cost and time required to build speech recognition systems. While originally focused on ASR support for new languages and domains, the Kaldi project steadily grew in size and capabilities, enabling hundreds of researchers to participate in advancing the field. Kaldi has become the de-facto speech recognition toolkit in the community, helping enable speech services used by millions of people every day.
Kaldi’s hybrid approach to speech recognition builds on decades of cutting edge research and combines the best known techniques with the latest in deep learning. The theoretical underpinnings of the framework borrow from traditional machine learning, such as Gaussian Mixture Models and Hidden Markov Models. However, today’s acoustic models in Kaldi replace those earlier models with both Recurrent and Convolutional Deep Neural Networks (DNNs) to predict states efficiently, with state-of-the-art performance.
Kaldi adopted GPU acceleration for training workloads early on. NVIDIA began working with Johns Hopkins University in 2017 to better utilize GPUs for inference acceleration, unlocking extreme speedups.
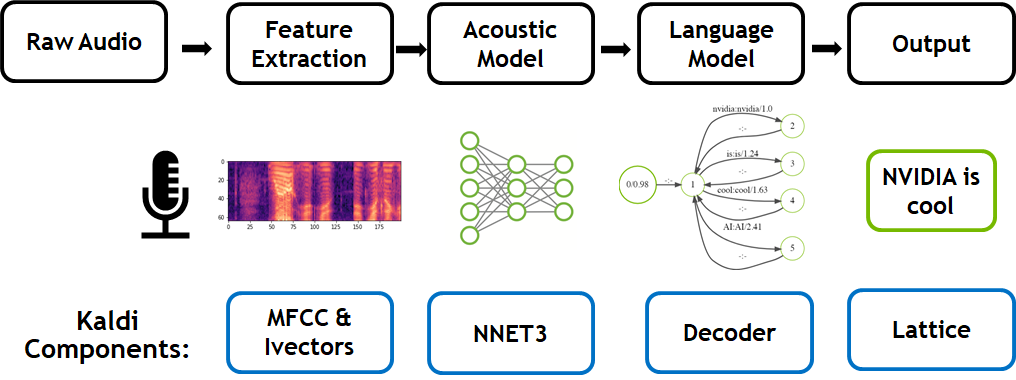
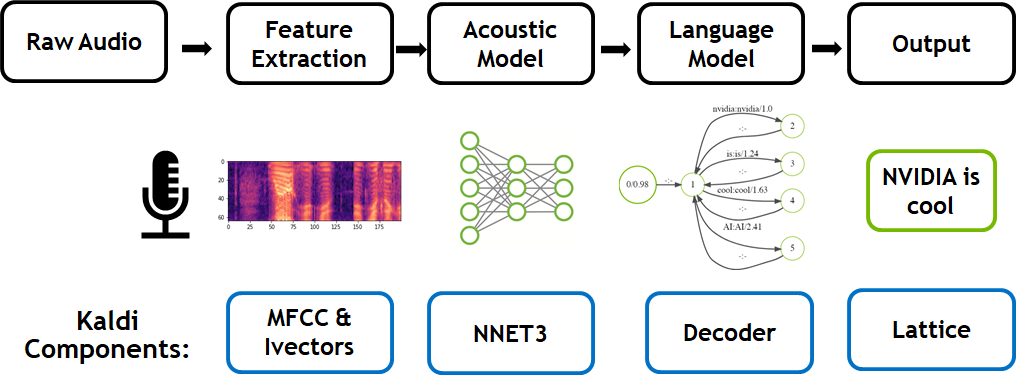
The traditional speech to text workflow shown in Figure 1 take place in three primary phases: feature extraction (converts a raw audio signal into spectral features suitable for machine learning tasks), acoustic modeling, and language modeling.
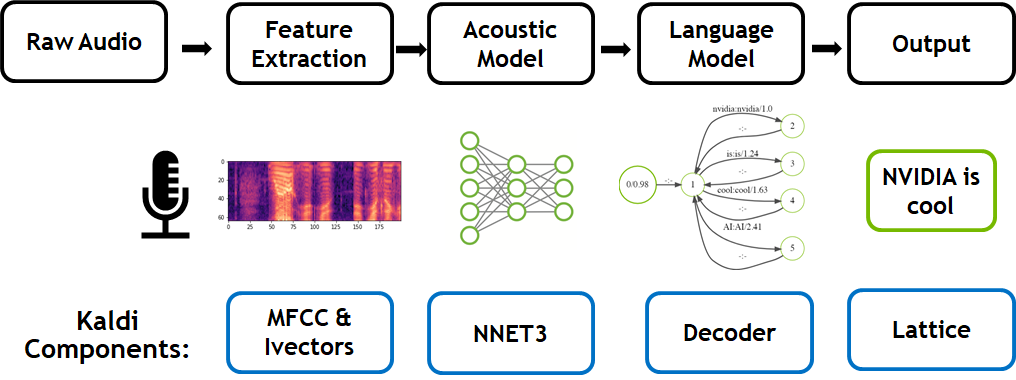
During training, two models are trained independently. Speech training data, comprised of transcribed recordings in a target language, is used to learn the acoustic model. The role of the acoustic model is to predict components of a phoneme, given a segment of audio features derived from the feature extractor. This consists of the elemental sounds of a given language –44 in English, for example. An n-gram model predicts the next word in a sequence for the language model. This is trained on text-only transcripts of conversations. If you hear the sentence, “Today, the clouds look grey. I think it’s going to _____”, you know a higher probability exists for the word ‘rain’ to occur next than ‘potato’. These two models combine to form the basis for speech recognition.
Audio is run through the feature extractor during inference, producing phoneme probabilities over time. An ASR decoder utilize these probabilities, along with the language model, to decode the most likely written sentence for the given input waveform. NVIDIA’s work in optimizing the Kaldi pipeline includes prior GPU optimizations to both the acoustic model and the introduction of a GPU-based Viterbi decoder in this post for the language model. NVIDIA GPUs parallelize this compute intensive decoding process for the first time.
You can find more detailed optimization information in the archive of our past GPU Technology Conference (GTC) presentations:
- 2018 GTC San Jose. Hugo Braun, Accelerate Your Kaldi Speech Pipeline on the GPU
- 2018 GTC DC. Justin Luitjens and Hugo Braun, Speech Recognition Using the GPU Accelerated Kaldi Framework
GPU Accelerated Kaldi Inferencing Performance Results
NVIDIA tested a model trained on the LibriSpeech corpus, according to the public Kaldi recipe, on both clean and noisy speech recordings. One experiment with clean data achieved speech-to-text inferencing 3,524x faster than real-time processing using an NVIDIA Tesla V100. This means 24 hours worth of human speech can be transcribed in 25 seconds. We tested a variety of GPUs – from the 30W Jetson AGX Xavier to the 70W NVIDIA Tesla T4 to the 300W Tesla V100. All showed a performance improvement over dual Platinum Xeon CPUs. Notably, the 30W AGX Xavier not only has comparable performance to dual Platinum Xeon CPUs but it does so at an 18x increase in efficiency and a 13x cost savings.
Table 1 below tracks the overall performance for a family of GPUs. We generated these results using two CPU sockets per GPU. Our goal is to show both power and cost performance improvements as a GPU is added to an existing system and dedicated to an open CPU socket. Additionally, we calculated performance per dollar on a processor by processor basis and do not include networking, server, power, or other infrastructure costs.

Intel Xeon Platinum 8168 CPU @ 2.70GHz, 410W, $6,500 | Xavier: AGX Devkit, 30W, $1299 | T4: PCIe, 70W, $2000 | V100: SXM, 300W, $9000 | Processor only, not including system, memory, storage
To be explicit, we included the CPU power and cost when calculating the GPU power and cost totals. For example, the V100 pricing included the $9,000 price for the GPU and $13,000 for the dual Platinum Xeon ($6,500 per socket); therefore, the V100 cost is treated as $22,000 in this case. (All prices are estimates). There is no additional CPU cost for Xavier, since it is an embedded processor/System on Chip (SoC) and includes both GPU and CPU.
Multi-GPU support with the current version of NVIDIA’s optimizations rely on separate processes per GPU and do not use interconnect fabric such as NVLINK. Nevertheless, our initial benchmarks compared to a dual Platinum 8168 CPU have shown that both inferencing performance per dollar and per watt generally improve as additional GPUs are added for processing, as shown in figure 2. We currently recommend 2 V100s or 4 T4s per CPU socket.
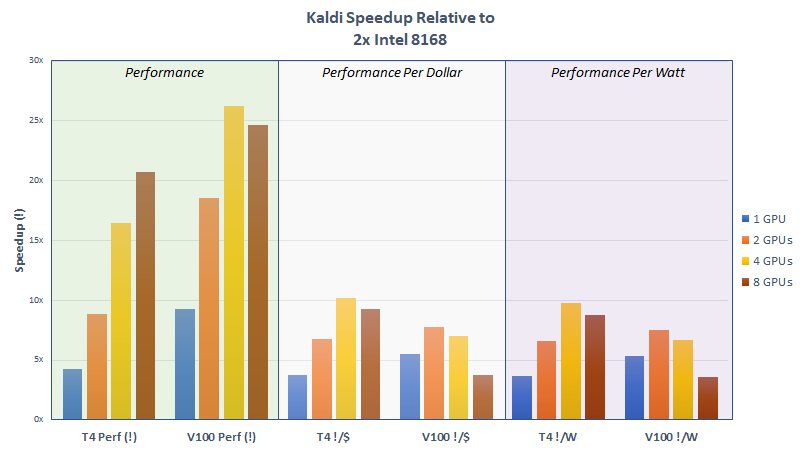
While NVIDIA focused its Kaldi acceleration work on speech inferencing alone, future work can explore additional techniques to accelerate other components, including training, of the Kaldi speech-to-text workflow.
How to Use NVIDIA’s Kaldi Modifications
The source code containing NVIDIA’s GPU optimizations can be found in a public pull request on the official Kaldi GitHub repository. A number of improvements to improve GPU acceleration during this acceleration have already been integrated. Further, NVIDIA is providing a Kaldi Toolkit Docker container via the NVIDIA GPU Cloud (NGC). Instructions for running the container and the Kaldi benchmarking code can be found below. Future container releases will focus on developer productivity, including scripts to help users quickly run their own ASR models and native support for additional pre-trained ones.
In conjunction with Johns Hopkins University, NVIDIA is excited to advance the state-of-the-art performance of the Kaldi framework. We encourage you to be an active participant in the open source project – especially testing NVIDIA’s contributions with other pre-trained language models.
Kaldi Docker Walkthrough
Log into NGC and pull the latest Kaldi container. Note that Kaldi versions adhere to the convention <yy.mm>, so the April 2019 version would be 19.04.
%> docker login nvcr.io %> docker pull nvcr.io/nvidia/kaldi:<yy.mm>-py3
Start the Kaldi container. The container provides scripts to download both the pretrained librispeech model and associated data.
%> nvidia-docker run --rm -it nvcr.io/nvidia/kaldi:<yy.mm>-py3 /bin/bash
Conversely, you can mount local volumes to the container to test other models and datasets. We recommend this command for those developers who already have some familiarity with Kaldi.
%> nvidia-docker run --rm -it -v :/work/kaldi -v :/work/models -v :/work/datasets -v :/work/data kaldi:<yy.mm>-py3
Download and preprocess data, running the speech-to-text benchmark with pre-trained LibriSpeech model.
%> cd /workspace/nvidia-examples/librispeech %> ./prepare_data.sh %> ./run_benchmark.sh %> ./run_multigpu_benchmark.sh
Learn More at GTC 2019
If you’re interested in learning more about Kaldi and the specific GPU optimizations made to the framework, please visit our talk Accelerate Your Speech Recognition Pipeline on the GPU on Tuesday, March 19th at 1:00PM in Room 231 of the San Jose Conference Center. We will also be hosting a Connect with the Experts session concerning the acceleration of speech recognition and synthesis later that day from 4:00PM to 5:00PM in Hall 3, Pod E.
References
“Speech Recognition with Kaldi Lectures.” Dan Povey, www.danielpovey.com/kaldi-lectures.html.
Deller, John R., et al. Discrete-Time Processing of Speech Signals. Wiley IEEE Press Imprint, 1999.