Whether to employ mixed precision to train your TensorFlow models is no longer a tough decision. NVIDIA’s Automatic Mixed Precision (AMP) feature for TensorFlow, recently announced at the 2019 GTC, features automatic mixed precision training by making all the required model and optimizer adjustments internally within TensorFlow with minimal programmer intervention.
Performance increases using automatic mixed precision depend on model architecture. However, a set of models shown below trained up to 3x faster with AMP. Enabling automatic mixed precision in the existing TensorFlow training scripts requires setting an environment variable or changing just a few lines of code.
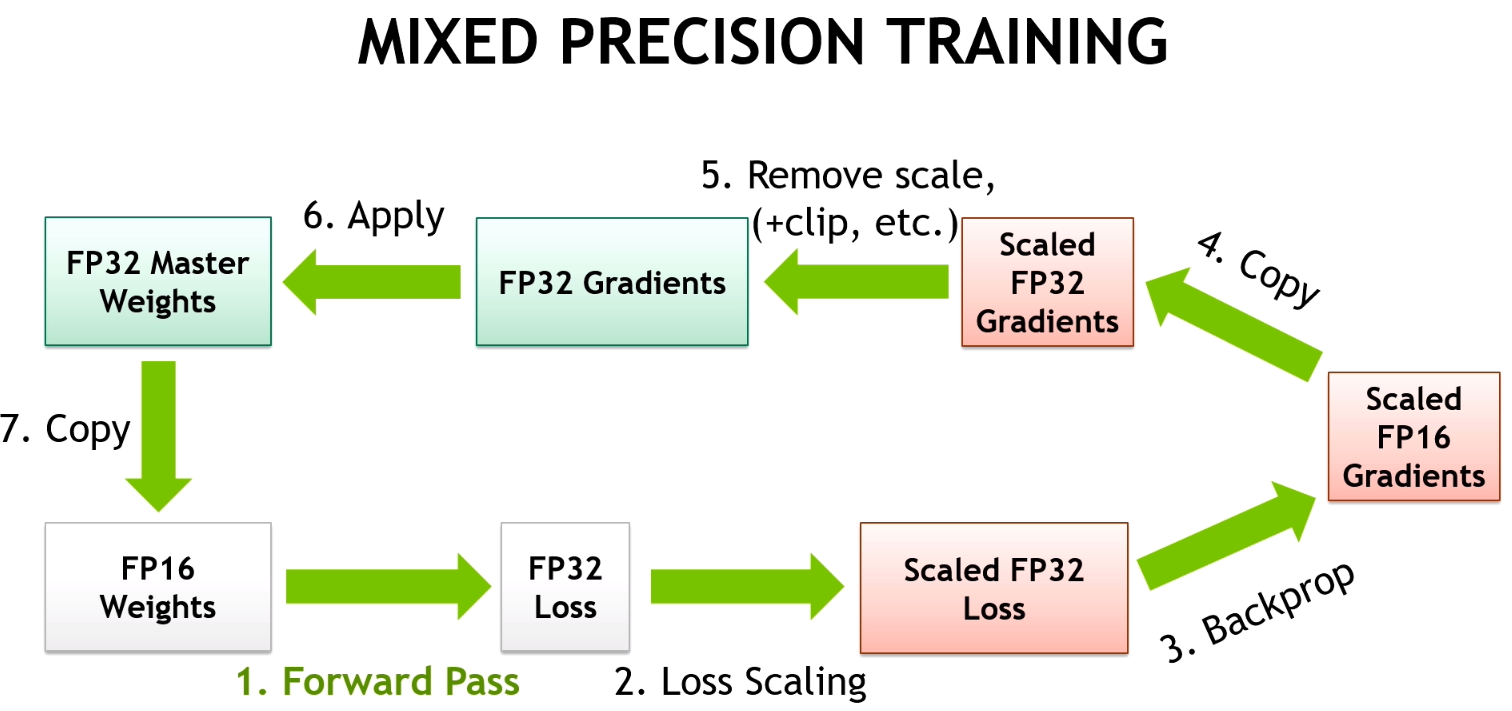
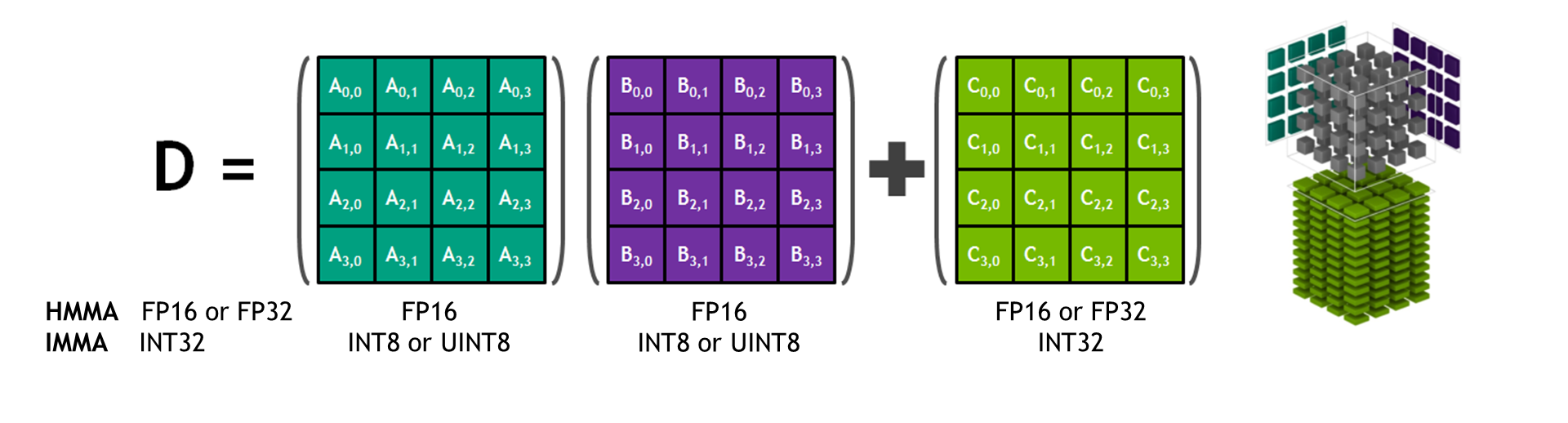
Mixed-precision training uses half-precision floating point to speed up training, achieving the same accuracy as single-precision training sessions using the same hyper parameters. Using half-precision enables using Tensor Cores introduced in NVIDIA Volta and Turing GPU architectures, as shown in figure 1. Tensor Cores provide up to 8x more throughput compared to single precision on the same GPU. Mixed precision also reduces the memory footprint, enabling larger models or larger minibatches.

While mixed precision training was already possible in TensorFlow, using it required manual model and optimizer adjustments by developers. Automatic mixed precision makes all the adjustments internally in TensorFlow, providing two benefits over manual operations. First, programmers need not modify network model code, reducing development and maintenance effort. Second, using AMP maintains forward and backward compatibility with all the APIs for defining and running TensorFlow models.
Today, the automatic mixed precision feature is available inside NVIDIA NGC TensorFlow 19.03 container. Enabling this feature inside the container requires simply setting one environment variable:
export TF_ENABLE_AUTO_MIXED_PRECISION=1
As an alternative, the environment variable can be set inside the TensorFlow Python script:
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
NVIDIA continues to work closely with Google to have the automatic mixed precision features merged into TensorFlow master.
Once enabling mixed precision, you can achieve further speedups by:
- Enabling the TensorFlow XLA compiler. Please note that Google still lists XLA as an experimental tool
- Increasing the minibatch size. Larger mini-batches often lead to better GPU utilization, mixed-precision enables up to 2x larger minibatches.
Figure 2 shows examples of performance increases using AMP using different networks. You can find all the models here except for ssd-rn50-fpn-640.
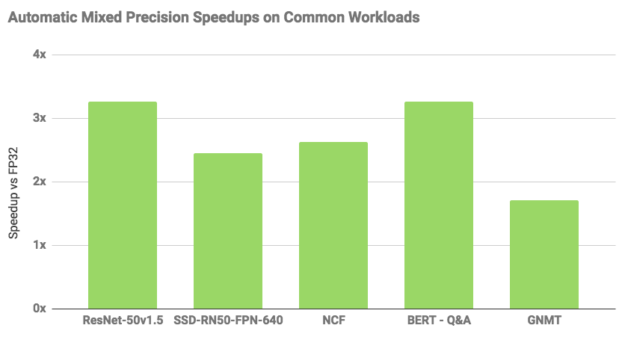
Batch sizes measured as follows. rn50 (v1.5): 128 for FP32, 256 for AMP+XLA; ssd-rn50-fpn-640: 8 for FP32, 16 for AMP+XLA; ncf: 1M for FP32 and AMP+XLA; bert-squadqa: 4 for FP32, 10 for AMP+XLA; gnmt: 128 for FP32, 192 for AMP.
Example Walkthrough: ResNet-50
You can explore the training scripts provided for Resnet-50 in order to test the performance of a Volta or Turing GPU with and without automatic mixed precision. You can find these scripts in NVIDIA NGC model script registry and on GitHub. Follow the README provided with the scripts to set up your environment to run the training scripts in the GitHub repo.
Use the following command line for all the steps below. This example uses a single V100-16GB to recreate the reported performance.
python ./main.py --mode=training_benchmark --warmup_steps 200 --num_iter 500 --iter_unit batch --data_dir= --results_dir=
- Run the training performance benchmark in FP32 using a batch size of 128, since a batch size of 256 doesn’t fit in this configuration:
Additional arguments:--batch_size 128
Expected performance: 365 img/sec - Enable training with automatic mixed precision using the following parameters:
Additional arguments:--batch_size 128 --use_tf_amp
Expected performance: 780 img/sec - Enable XLA, which can significantly increase training performance with mixed precision:
Additional arguments:--batch_size 128 --use_tf_amp --use_xla
Expected performance: 1010 img/sec - Train with a larger batch size, since automatic mixed precision converted many tensors to use half-precision, reducing memory requirements:
Additional arguments:--batch_size 256 --use_tf_amp --use_xla
Expected performance: 1205 img/sec
Availability
You can find all the features discussed above for automatic mixed-precision in the NVIDIA optimized TensorFlow 19.03 NVIDIA NGC container. Pull the NVIDIA GPU optimized TensorFlow container and experience the leap in performance improvements. The NVIDIA developer blog will offer an in-depth tutorial on how to implement AMP in your workflow in the near future. Feel free to leave feedback or questions for our team in our TensorFlow forum.
Acknowledgements
Thanks to Carl Case, Ujval Kapasi and Paulius Micikevicius for contributing to this post.
Additional Resources
- Webinar: Automatic Mixed Precision Training in TensorFlow
- GTC San Jose Talk – S9143: Mixed Precision Training of Deep Neural Networks
- GTC San Jose Talk – S91029: New automated mixed-precision tools for TensorFlow training
- ICLR 2018 paper: Mixed Precision Training