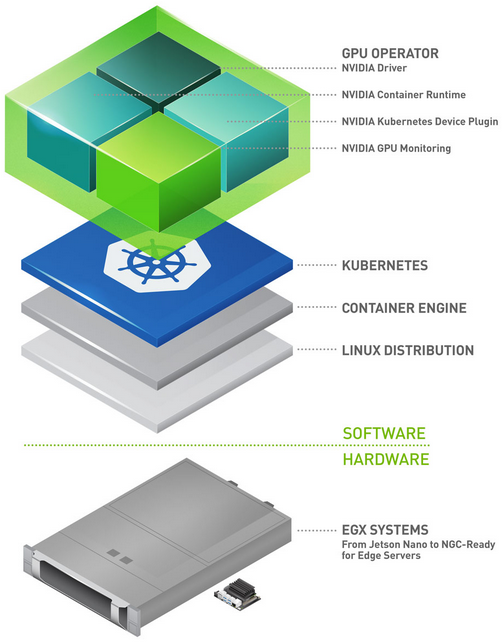
Editor’s note: Interested in GPU Operator? Register for our upcoming webinar on January 20th, “How to Easily use GPUs with Kubernetes”.
Over the last few years, NVIDIA has leveraged GPU containers in a variety of ways for testing, development and running AI workloads in production at scale. Containers optimized for NVIDIA GPUs and systems such as the DGX and OEM NGC-Ready servers are available as part of NGC.
But provisioning servers with GPUs reliably and scaling AI applications can be tricky. Kubernetes has quickly become the platform of choice for deploying complex applications built on top of numerous microservices due to its rich set of APIs, reliability, scalability and performance features.
Kubernetes provides access to special hardware resources such as NVIDIA GPUs, NICs, Infiniband adapters and other devices through the device plugin framework. However, configuring and managing nodes with these hardware resources requires configuration of multiple software components such as drivers, container runtimes or other libraries which are difficult and prone to errors.
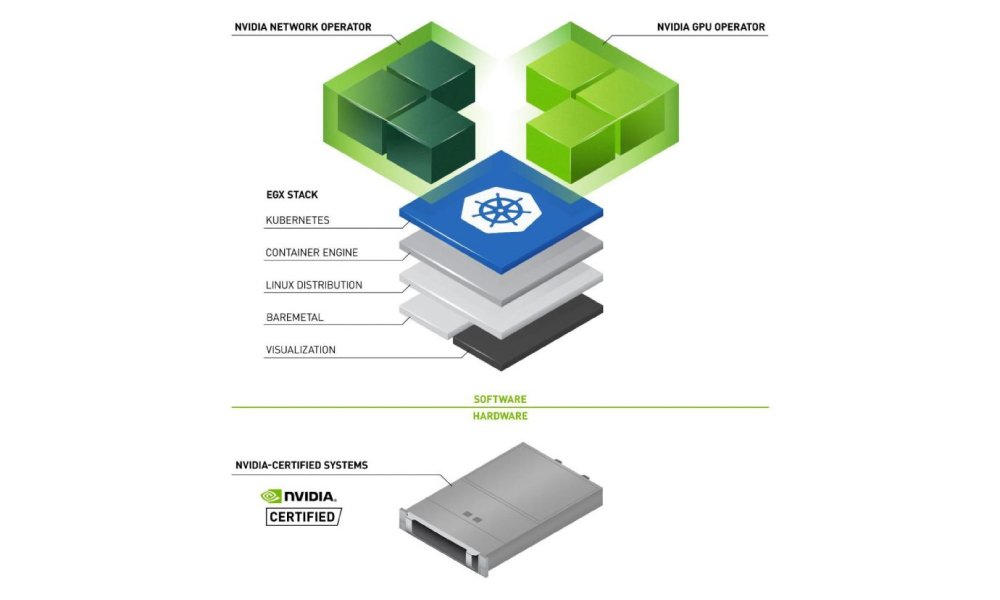
The Operator Framework within Kubernetes takes operational business logic and allows the creation of an automated framework for the deployment of applications within Kubernetes using standard Kubernetes APIs and kubectl. The NVIDIA GPU Operator introduced here is based on the operator framework and automates the management of all NVIDIA software components needed to provision GPUs within Kubernetes. NVIDIA, Red Hat, and others in the community have collaborated on creating the GPU Operator. The GPU Operator is an important component of the NVIDIA EGX software-defined platform that is designed to make large-scale hybrid-cloud and edge operations possible and efficient.
NVIDIA GPU Operator
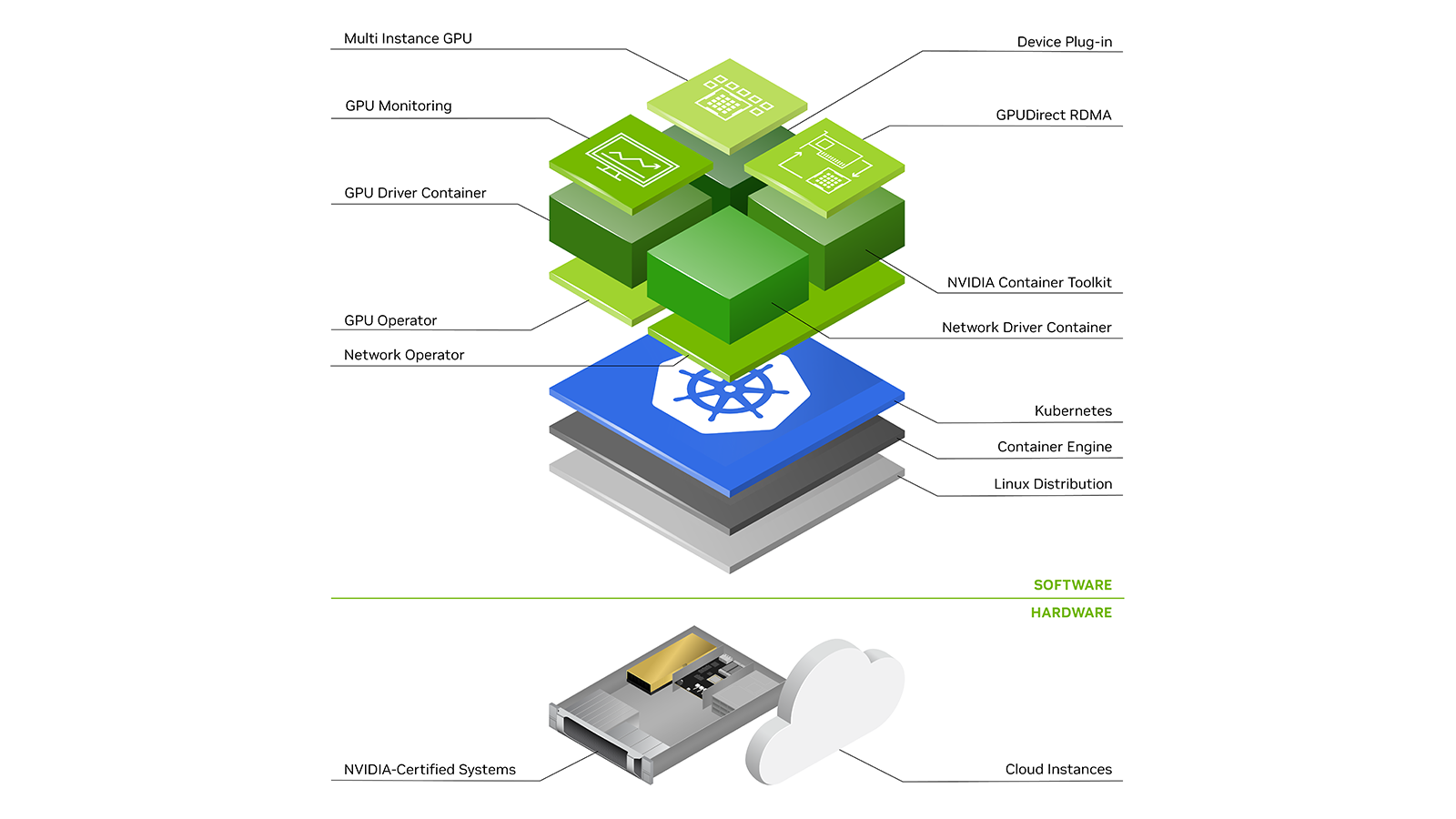
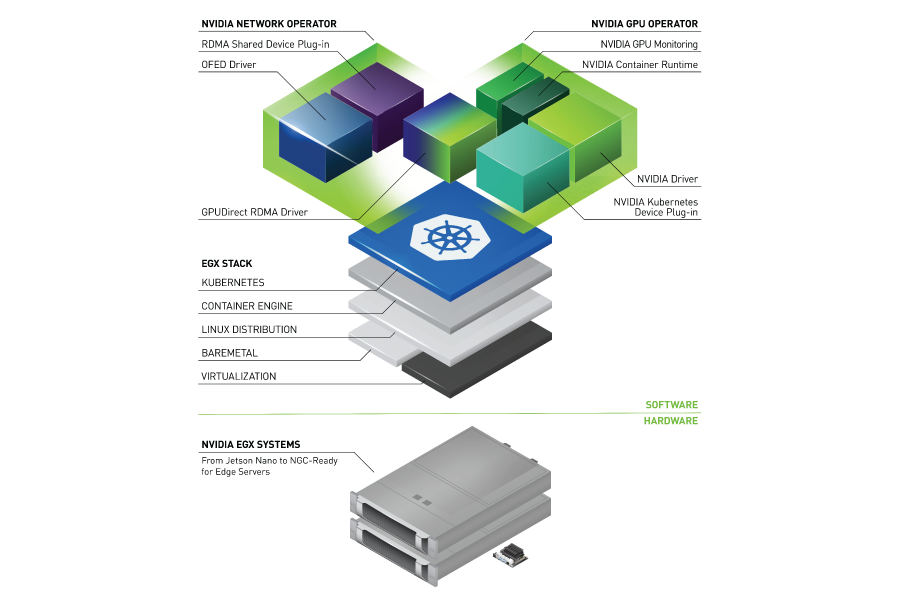
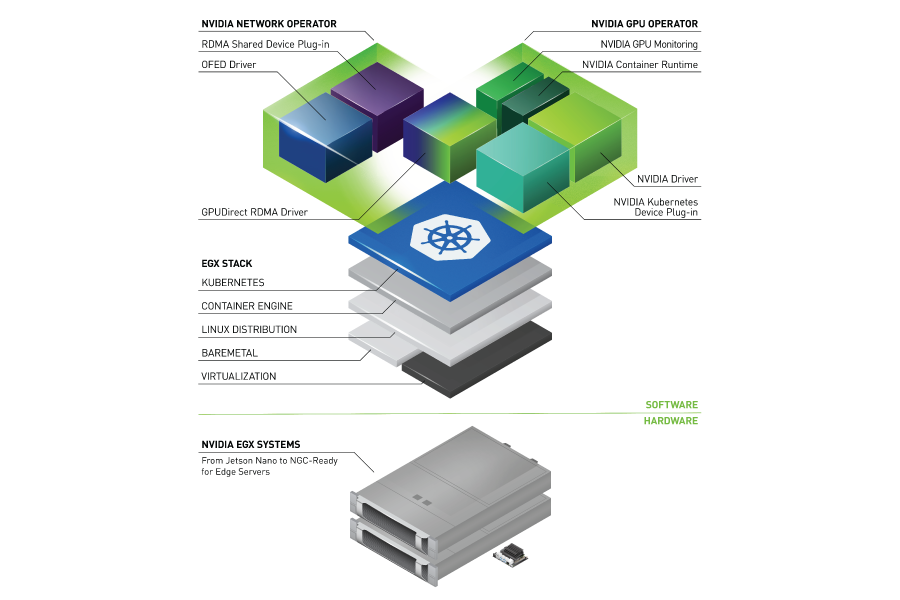
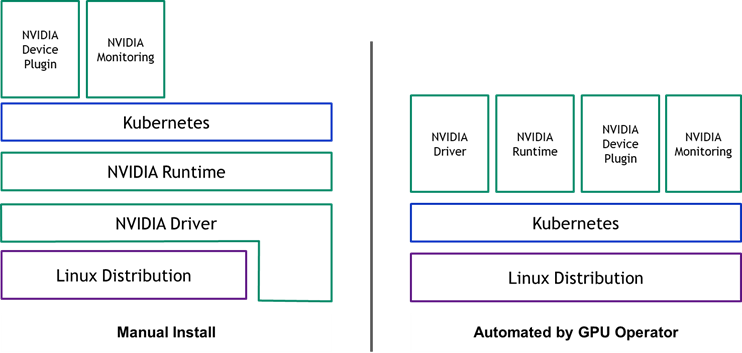
To provision GPU worker nodes in a Kubernetes cluster, the following NVIDIA software components are required – the driver, container runtime, device plugin and monitoring. As shown in Figure 1, these components need to be manually provisioned before GPU resources are available to the cluster and also need to be managed during the operation of the cluster. The GPU Operator simplifies both the initial deployment and management of the components by containerizing all the components and using standard Kubernetes APIs for automating and managing these components including versioning and upgrades. The GPU operator is fully open-source and is available on our GitHub repo.
Operator State Machine
The GPU Operator is based on the Operator Framework in Kubernetes. The operator is built as a new Custom Resource Definition (CRD) API with a corresponding controller. The operator runs in its own namespace (called “gpu-operator”) with the underlying NVIDIA components orchestrated in a separate namespace (called “gpu-operator-resources”). As with any standard operator in Kubernetes, the controller watches the namespace for changes and uses a reconcile loop (via the Reconcile() function) to implement a simple state machine for starting each of the NVIDIA components. The state machine includes a validation step at each state and on failure, the reconcile loop exits with an error. This is shown in Figure 2.
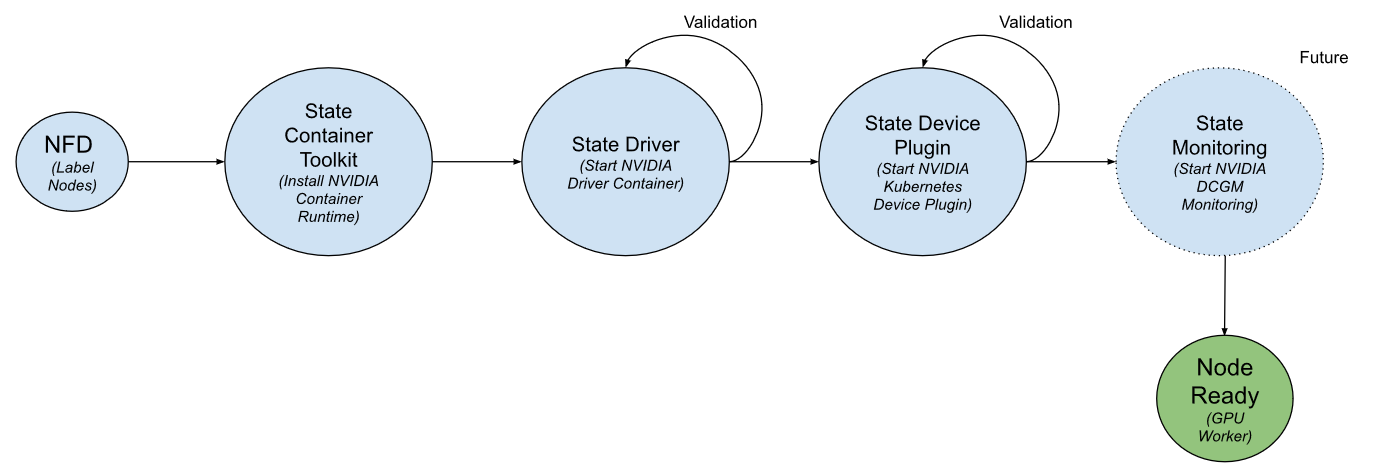
The GPU operator should run on nodes that are equipped with GPUs. To determine which nodes have GPUs, the operator relies on Node Feature Discovery (NFD) within Kubernetes. The NFD worker detects various hardware features on the node – for example, PCIe device ids, kernel versions, memory and other attributes. It then advertises these features to Kubernetes using node labels. The GPU operator then uses these node labels (by checking the PCIe device id) to determine if NVIDIA software components should be provisioned on the node. In this initial release, the GPU operator currently deploys the NVIDIA container runtime, NVIDIA containerized driver and the NVIDIA Kubernetes Device Plugin. In the future, the operator will also manage other components such as DCGM-based monitoring.
Let’s briefly look at the different states.
State Container Toolkit
This state deploys a DaemonSet that installs the NVIDIA container runtime on the host system via a container. The DaemonSet uses the PCIe device id from the NFD label to only install the runtime on nodes that have GPU resources. The PCIe device id 0x10DE is the vendor id for NVIDIA.
nodeSelector:
feature.node.kubernetes.io/pci-10de.present: "true"
State Driver
This state deploys a DaemonSet with the NVIDIA driver that is containerized. You can read more about driver containers here. On startup, the driver container may build the final NVIDIA kernel modules and load them into the Linux kernel on the host in preparation to run CUDA applications and runs in the background. The driver container includes the user-mode components of the driver required for applications. Again, the DaemonSet uses the NFD label to select nodes on which to deploy the driver container.
State Driver Validation
As mentioned above, the operator state machine includes validation steps to ensure that components have been started successfully. The operator schedules a simple CUDA workload (in this case a vectorAdd sample). The container state is “Success” if the application ran without any errors.
State Device Plugin
This state deploys a DaemonSet for the NVIDIA Kubernetes device plugin. It registers the list of GPUs on the node with the kubelet so that GPUs can be allocated to CUDA workloads.
State Device Plugin Validation
At this state, the validation container requests for a GPU to be allocated by Kubernetes and runs a simple CUDA workload (as described above) to check if the device plugin registered the list of resources and the workload ran successfully (i.e. the container status was “Success”).
To simplify the deployment of the GPU operator itself, NVIDIA provides a Helm chart. The versions of the software components that are deployed by the operator (e.g. driver, device plugin) can be customized by the user with templates (values.yaml) in the Helm chart. The operator then uses the template values to provision the desired versions of the software on the node. This provides a level of parameterization to the user.
Running the GPU Operator
Let’s take a quick look at how to deploy the GPU operator and run a CUDA workload. At this point, we assume that you have a Kubernetes cluster operational (i.e. the master control plane is available and worker nodes have joined the cluster). To keep things simple for this blog post, we will use a single node Kubernetes cluster with an NVIDIA Tesla T4 GPU running Ubuntu 18.04.3 LTS.
The GPU Operator does not address the setting up of a Kubernetes cluster itself – there are many solutions available today for this purpose. NVIDIA is working with different partners on integrating the GPU Operator into their solutions for managing GPUs.
Let’s verify that our Kubernetes cluster (along with a Helm setup with Tiller) is operational. Note that while the node has a GPU, there are no NVIDIA software components deployed on the node – we will be using the GPU operator to provision the components.
$ sudo kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-6fcc7d5fd6-n2dnt 1/1 Running 0 6m45s kube-system calico-node-77hjv 1/1 Running 0 6m45s kube-system coredns-5c98db65d4-cg6st 1/1 Running 0 7m10s kube-system coredns-5c98db65d4-kfl6v 1/1 Running 0 7m10s kube-system etcd-ip-172-31-5-174 1/1 Running 0 6m5s kube-system kube-apiserver-ip-172-31-5-174 1/1 Running 0 6m11s kube-system kube-controller-manager-ip-172-31-5-174 1/1 Running 0 6m26s kube-system kube-proxy-mbnsg 1/1 Running 0 7m10s kube-system kube-scheduler-ip-172-31-5-174 1/1 Running 0 6m18s kube-system tiller-deploy-8557598fbc-hrrhd 1/1 Running 0 21s
A single node Kubernetes cluster (the master has been untainted, so it can run workloads)
$ kubectl get nodes NAME STATUS ROLES AGE VERSION ip-172-31-5-174 Ready master 3m2s v1.15.3
We can see that the node has an NVIDIA GPU but no drivers or other software tools installed.
$ lspci | grep -i nvidia 00:1e.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1) $ nvidia-smi nvidia-smi: command not found
As a prerequisite, let’s ensure that some kernel modules are setup on the system. The NVIDIA driver has some dependencies on these modules for symbol resolution.
$ sudo modprobe -a i2c_core ipmi_msghandler
Now, let’s go ahead and deploy the GPU operator. We will use a Helm chart for this purpose that is available from NGC. First, add the Helm repo:
$ helm repo add nvidia https://helm.ngc.nvidia.com/nvidia "nvidia" has been added to your repositories $ helm repo update Hang tight while we grab the latest from your chart repositories... ...Skip local chart repository ...Successfully got an update from the "nvidia" chart repository ...Successfully got an update from the "stable" chart repository Update Complete.
And then deploy the operator with the chart
$ helm install --devel nvidia/gpu-operator -n test-operator --wait $ kubectl apply -f https://raw.githubusercontent.com/NVIDIA/gpu-operator/master/manifests/cr/sro_cr_sched_none.yaml specialresource.sro.openshift.io/gpu created
We can verify that the GPU operator is running in its own namespace and is watching the components in another namespace.
$ kubectl get pods -n gpu-operator NAME READY STATUS RESTARTS AGE special-resource-operator-7654cd5d88-w5jbf 1/1 Running 0 98s
After a few minutes, the GPU operator would have deployed all the NVIDIA software components. The output also shows the validation containers run as part of the GPU operator state machine. The sample CUDA containers (vectorAdd) have completed successfully as part of the state machine.
$ kubectl get pods -n gpu-operator-resources NAME READY STATUS RESTARTS AGE nvidia-container-toolkit-daemonset-wwzfn 1/1 Running 0 3m36s nvidia-device-plugin-daemonset-pwfq7 1/1 Running 0 101s nvidia-device-plugin-validation 0/1 Completed 0 92s nvidia-driver-daemonset-skpn7 1/1 Running 0 3m27s nvidia-driver-validation 0/1 Completed 0 3m $ kubectl -n gpu-operator-resources logs -f nvidia-device-plugin-validation [Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
We can also see that the NFD has labeled the node with different attributes. A node label with the PCIe device id 0x10DE has been set for the NVIDIA GPU.
$ kubectl -n node-feature-discovery logs -f nfd-worker-zsjsp 2019/10/21 00:46:25 cpu-cpuid.AVX512F = true 2019/10/21 00:46:25 cpu-hardware_multithreading = true 2019/10/21 00:46:25 cpu-cpuid.AVX = true 2019/10/21 00:46:25 cpu-cpuid.AVX512VL = true 2019/10/21 00:46:25 cpu-cpuid.AVX512CD = true 2019/10/21 00:46:25 cpu-cpuid.AVX2 = true 2019/10/21 00:46:25 cpu-cpuid.FMA3 = true 2019/10/21 00:46:25 cpu-cpuid.ADX = true 2019/10/21 00:46:25 cpu-cpuid.AVX512DQ = true 2019/10/21 00:46:25 cpu-cpuid.AESNI = true 2019/10/21 00:46:25 cpu-cpuid.AVX512BW = true 2019/10/21 00:46:25 cpu-cpuid.MPX = true 2019/10/21 00:46:25 kernel-config.NO_HZ = true 2019/10/21 00:46:25 kernel-config.NO_HZ_IDLE = true 2019/10/21 00:46:25 kernel-version.full = 4.15.0-1051-aws 2019/10/21 00:46:25 kernel-version.major = 4 2019/10/21 00:46:25 kernel-version.minor = 15 2019/10/21 00:46:25 kernel-version.revision = 0 2019/10/21 00:46:25 pci-10de.present = true 2019/10/21 00:46:25 pci-1d0f.present = true 2019/10/21 00:46:25 storage-nonrotationaldisk = true 2019/10/21 00:46:25 system-os_release.ID = ubuntu 2019/10/21 00:46:25 system-os_release.VERSION_ID = 18.04 2019/10/21 00:46:25 system-os_release.VERSION_ID.major = 18 2019/10/21 00:46:25 system-os_release.VERSION_ID.minor = 04
Let’s launch a TensorFlow notebook. An example manifest is available on our GitHub repo, so let’s use that
$ kubectl apply -f https://nvidia.github.io/gpu-operator/notebook-example.yml
Once the pod is created, we can use the token to view the notebook in a browser window.
$ kubectl logs -f tf-notebook
[C 02:52:44.849 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=b7881f90dfb6c8c5892cff7e8232684f201c846c48da81c9
We can either use port forwarding or use the node port 30001 to reach the container. Use the URL from the logs above to open the Jupyter notebook in the browser.
$ kubectl port-forward tf-notebook 8888:8888

You can now see the Jupyter homepage and continue with your workflows — all running within Kubernetes and accelerated with GPUs!
Conclusion
This post covers the NVIDIA GPU Operator and how it can be used to provision and manage nodes with NVIDIA GPUs into a Kubernetes cluster. Get started with the GPU Operator via a Helm chart on NGC today or get the source from our GitHub repo. The future is exciting and includes features like support for advanced labelling, monitoring, update management and more.
If you have questions or comments please leave them below in the comments section. For technical questions about installation and usage, we recommend filing an issue on the GitHub repo.