
The world’s ultimate embedded solution for AI developers, Jetson AGX Xavier, is now shipping as standalone production modules from NVIDIA. A member of NVIDIA’s AGX Systems for autonomous machines, Jetson AGX Xavier is ideal for deploying advanced AI and computer vision to the edge, enabling robotic platforms in the field with workstation-level performance and the ability to operate fully autonomously without relying on human intervention and cloud connectivity. Intelligent machines powered by Jetson AGX Xavier have the freedom to interact and navigate safely in their environments, unencumbered by complex terrain and dynamic obstacles, accomplishing real-world tasks with complete autonomy. This includes package delivery and industrial inspection that require advanced levels of real-time perception and inferencing to perform. As the world’s first computer designed specifically for robotics and edge computing, Jetson AGX Xavier’s high-performance can handle visual odometry, sensor fusion, localization and mapping, obstacle detection, and path planning algorithms critical to next-generation robots. Figure 1 shows the production compute modules now available globally. Developers can now begin deploying new autonomous machines in volume.

The latest generation of NVIDIA’s industry-leading Jetson AGX family of embedded Linux high-performance computers, Jetson AGX Xavier delivers GPU workstation class performance with an unparalleled 32 TeraOPS (TOPS) of peak compute and 750Gbps of high-speed I/O in a compact 100x87mm form-factor. Users can configure operating modes at 10W, 15W, and 30W as needed for their applications. Jetson AGX Xavier sets a new bar for compute density, energy efficiency, and AI inferencing capabilities deployable to the edge, enabling next-level intelligent machines with end-to-end autonomous capabilities.
Jetson powers the AI behind many of the world’s most advanced robots and autonomous machines using deep learning and computer vision while focusing on performance, efficiency, and programmability. Jetson AGX Xavier, diagrammed in figure 2, consists of over 9 billion transistors, based on the most complex System-on-Chip (SoC) ever created. The platform comprises an integrated 512-core NVIDIA Volta GPU including 64 Tensor Cores, 8-core NVIDIA Carmel ARMv8.2 64-bit CPU, 16GB 256-bit LPDDR4x, dual NVIDIA Deep Learning Accelerator (DLA) engines, NVIDIA Vision Accelerator engine, HD video codecs, 128Gbps of dedicated camera ingest, and 16 lanes of PCIe Gen 4 expansion. Memory bandwidth over the 256-bit interface weighs in at 137GB/s, while the DLA engines offload inferencing of Deep Neural Networks (DNNs).NVIDIA’s JetPack SDK 4.1.1 for Jetson AGX Xavier includes CUDA 10.0, cuDNN 7.3, and TensorRT 5.0, providing the complete AI software stack.
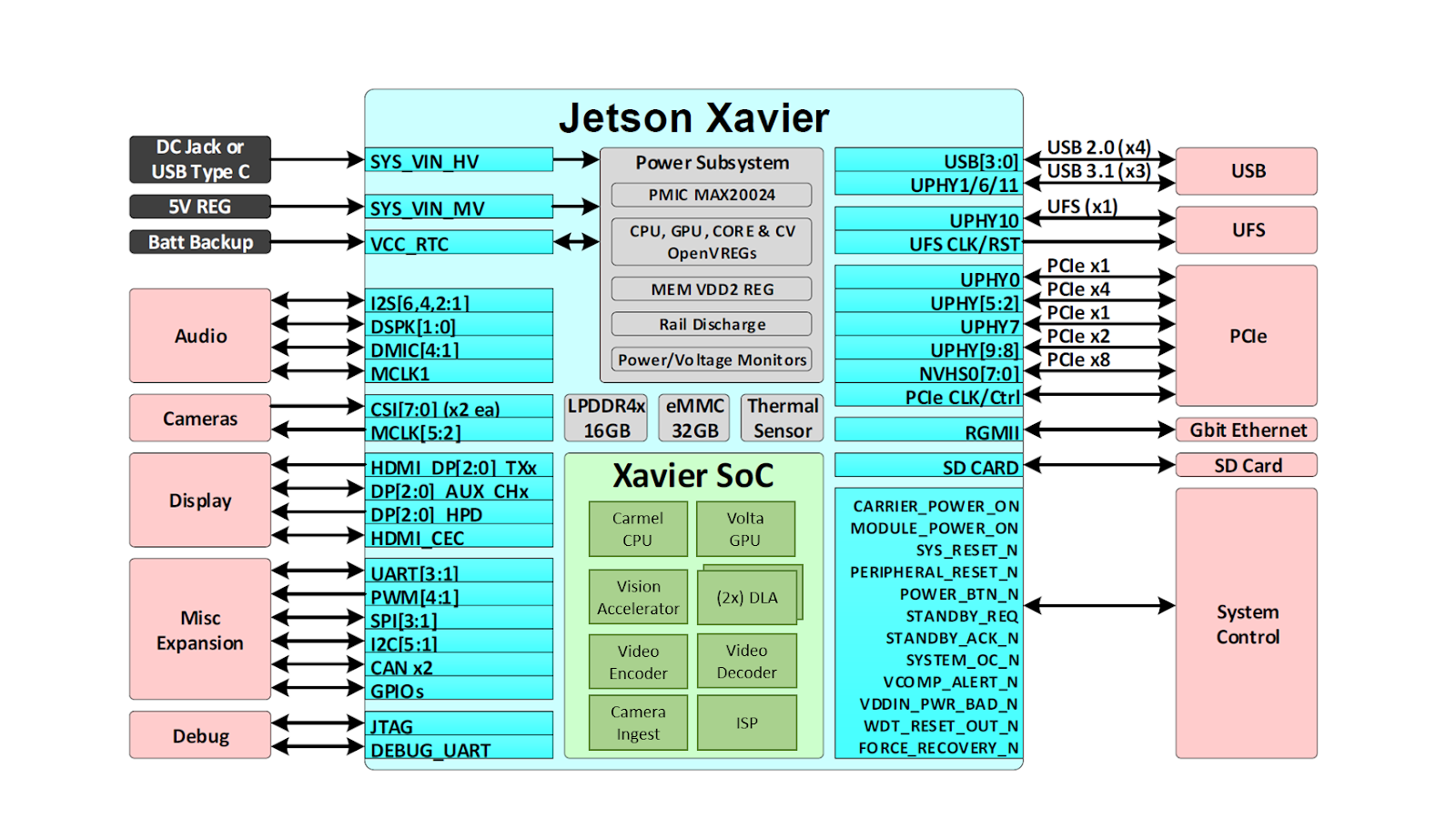
This enables developers the ability to deploy accelerated AI in applications like robotics, intelligent video analytics, medical instruments, embedded IoT edge devices, and more. Like its predecessors Jetson TX1 and TX2, Jetson AGX Xavier uses a System-on-Module (SoM) paradigm. All the processing is contained onboard the compute module and high-speed I/O lives on a breakout carrier or enclosure that’s provided through a high-density board-to-board connector. Encapsulating functionality on the module in this way makes it easy for developers to integrate Jetson Xavier into their own designs. NVIDIA has released comprehensive documentation and reference design files available to download for embedded designers creating their own devices and platforms using Jetson AGX Xavier. Be sure to consult the Jetson AGX Xavier Module Data Sheet and Jetson AGX Xavier OEM Product Design Guide for the full product features listed from Table 1, in addition to electromechanical specifications, the module pin-out, power sequencing, and signal routing guidelines.
| NVIDIA Jetson AGX Xavier Module | |
| CPU | 8-core NVIDIA Carmel 64-bit ARMv8.2 @ 2265MHz |
| GPU | 512-core NVIDIA Volta @ 1377MHz with 64 TensorCores |
| DL | Dual NVIDIA Deep Learning Accelerators (DLAs) |
| Memory | 16GB 256-bit LPDDR4x @ 2133MHz | 137GB/s |
| Storage | 32GB eMMC 5.1 |
| Vision | (2x) 7-way VLIW Vision Accelerator |
| Encoder* | (4x) 4Kp60 | (8x) 4Kp30 | (16x) 1080p60 | (32x) 1080p30 Maximum throughput up to (2x) 1000MP/s – H.265 Main |
| Decoder* | (2x) 8Kp30 | (6x) 4Kp60 | (12x) 4Kp30 | (26x) 1080p60 | (52x) 1080p30 Maximum throughput up to (2x) 1500MP/s – H.265 Main |
| Camera† | (16x) MIPI CSI-2 lanes, (8x) SLVS-EC lanes; up to 6 active sensor streams and 36 virtual channels |
| Display | (3x) eDP 1.4 / DP 1.2 / HDMI 2.0 @ 4Kp60 |
| Ethernet | 10/100/1000 BASE-T Ethernet + MAC + RGMII interface |
| USB | (3x) USB 3.1 + (4x) USB 2.0 |
| PCIe†† | (5x) PCIe Gen 4 controllers | 1×8, 1×4, 1×2, 2×1 |
| CAN | Dual CAN bus controller |
| Misc I/Os | UART, SPI, I2C, I2S, GPIOs |
| Socket | 699-pin board-to-board connector, 100x87mm with 16mm Z-height |
| Thermals‡ | -25°C to 80°C |
| Power | 10W / 15W / 30W profiles, 9.0V-20VDC input |
| *Maximum number of concurrent streams up to the aggregate throughput. Supported video codecs: H.265, H.264, VP9 Please refer to the Jetson AGX Xavier Module Data Sheet §1.6.1 and §1.6.2 for specific codec and profile specifications. †MIPI CSI-2, up to 40 Gbps in D-PHY V1.2 or 109 Gbps in CPHY v1.1 SLVS-EC, up to 18.4 Gbps ††(3x) Root Port + Endpoint controllers and (2x) Root Port controllers ‡Operating temperature range, Thermal Transfer Plate (TTP) max junction temperature. |
|
Jetson AGX Xavier includes more than 750Gbps of high-speed I/O, providing an extraordinary amount of bandwidth for streaming sensors and high-speed peripherals. It’s one of the first embedded devices to support PCIe Gen 4, providing 16 lanes across five PCIe Gen 4 controllers, three of which can operate in root port or endpoint mode. 16 MIPI CSI-2 lanes can be connected to four 4-lane cameras, six 2-lane cameras, six 1-lane cameras, or a combination of these configurations up to six cameras, with 36 virtual channels allowing more cameras to be connected simultaneously using stream aggregation. Other high-speed I/O includes three USB 3.1 ports, SLVS-EC, UFS, and RGMII for Gigabit Ethernet. Developers now have access to NVIDIA’s JetPack 4.1.1 Developer Preview software for Jetson AGX Xavier, listed in table 2. The Developer Preview includes Linux For Tegra (L4T) R31.1 Board Support Package (BSP) with support for Linux kernel 4.9 and Ubuntu 18.04 on the target. On the host PC side, JetPack 4.1.1 supports Ubuntu 16.04 and Ubuntu 18.04.
| NVIDIA JetPack 4.1.1 Developer Preview Release | |
|---|---|
| L4T R31.0.1 (Linux K4.9) | Ubuntu 18.04 LTS aarch64 |
| CUDA Toolkit 10.0 | cuDNN 7.3 |
| TensorRT 5.0 GA | GStreamer 1.14.1 |
| VisionWorks 1.6 | OpenCV 3.3.1 |
| OpenGL 4.6 / GLES 3.2 | Vulkan 1.1 |
| NVIDIA Nsight Systems 2018.1 | NVIDIA Nsight Graphics 2018.6 |
| Multimedia API R31.1 | Argus 0.97 Camera API |
The JetPack 4.1.1 Developer Preview release allows developers to immediately begin prototyping products and applications with Jetson AGX Xavier in preparation for production deployment. NVIDIA will continue making improvements to JetPack with additional feature enhancements and performance optimizations. Please read the Release Notes for highlights and software status of this release.
Volta GPU
The Jetson AGX Xavier integrated Volta GPU, shown in figure 3, provides 512 CUDA cores and 64 Tensor Cores for up to 11 TFLOPS FP16 or 22 TOPS of INT8 compute, with a maximum clock frequency of 1.37GHz. It supports CUDA 10 with a compute capability of sm_72. The GPU includes eight Volta Streaming Multiprocessors (SMs) with 64 CUDA cores and 8 Tensor Cores per Volta SM. Each Volta SM includes a 128KB L1 cache, 8x larger than previous generations. The SMs share a 512KB L2 cache and offers 4x faster access than previous generations.

Each SM consists of 4 separate processing blocks referred to as SMPs (streaming multiprocessor partitions), each including its own L0 instruction cache, warp scheduler, dispatch unit, and register file, along with CUDA cores and Tensor Cores. With twice the number of SMPs per SM than Pascal, the Volta SM features improved concurrency and supports more threads, warps, and thread blocks in flight.
Tensor Cores
NVIDIA Tensor Cores are programmable fused matrix-multiply-and-accumulate units that execute concurrently alongside CUDA cores. Tensor Cores implement new floating-point HMMA (Half-Precision Matrix Multiply and Accumulate) and IMMA (Integer Matrix Multiply and Accumulate) instructions for accelerating dense linear algebra computations, signal processing, and deep learning inference.
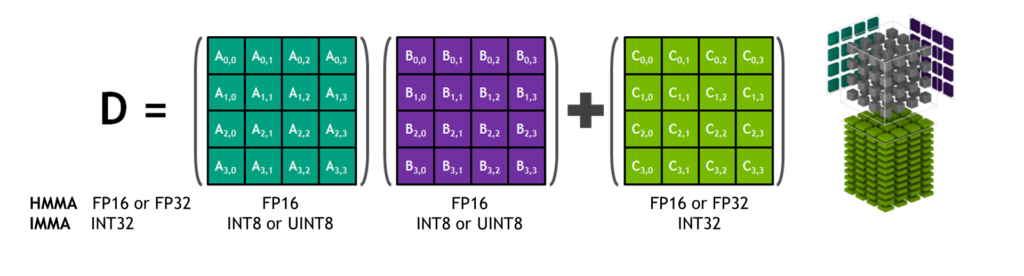
The matrix multiply inputs A and B are FP16 matrices for HMMA instructions, while the accumulation matrices C and D may be FP16 or FP32 matrices. For IMMA, the matrix multiply input A is a signed or unsigned INT8 or INT16 matrix, B is a signed or unsigned INT8 matrix, and both C and D accumulator matrices are signed INT32. Hence the range of precision and computation is sufficient to avoid overflow and underflow conditions during internal accumulation.
NVIDIA libraries including cuBLAS, cuDNN, and TensorRT have been updated to utilize HMMA and IMMA internally, allowing programmers to easily take advantage of the performance gains inherent in Tensor Cores. Users can also directly access Tensor Core operations at the warp level via a new API exposed in the wmma namespace and mma.h header included in CUDA 10. The warp-level interface maps 16×16, 32×8, and 8×32 size matrices across all 32 threads per warp.
Deep Learning Accelerator
Jetson AGX Xavier features two NVIDIA Deep Learning Accelerator (DLA) engines, shown in figure 5, that offload the inferencing of fixed-function Convolutional Neural Networks (CNNs). These engines improve energy efficiency and free up the GPU to run more complex networks and dynamic tasks implemented by the user. The NVIDIA DLA hardware architecture is open-source and available at NVDLA.org. Each DLA has up to 5 TOPS INT8 or 2.5 TFLOPS FP16 performance with a power consumption of only 0.5-1.5W. The DLAs support accelerating CNN layers such as convolution, deconvolution, activation functions, min/max/mean pooling, local response normalization, and fully-connected layers.
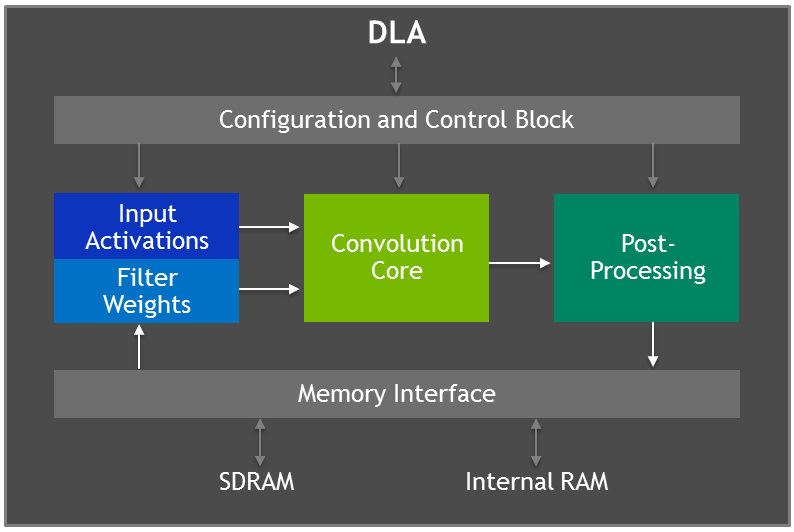
DLA hardware consists of the following components:
- Convolution Core – optimized high-performance convolution engine.
- Single Data Processor – single-point lookup engine for activation functions.
- Planar Data Processor – planar averaging engine for pooling.
- Channel Data Processor – multi-channel averaging engine for advanced normalization functions.
- Dedicated Memory and Data Reshape Engines – memory-to-memory transformation acceleration for tensor reshape and copy operations.
Developers program DLA engines using TensorRT 5.0 to perform inferencing on networks, including support for AlexNet, GoogleNet, and ResNet-50. For networks that utilize layer configurations not supported by DLA, TensorRT provides GPU fallback for the layers that are unable to be run on DLAs. The JetPack 4.0 Developer Preview limits DLA precision to FP16 mode initially, with INT8 precision and increased performance for DLA coming in a future JetPack release.
TensorRT 5.0 adds the following APIs to its IBuilder interface to enable the DLAs:
setDeviceType()andsetDefaultDeviceType()for selecting GPU, DLA_0, or DLA_1 for the execution of a particular layer, or for all layers in the network by default.canRunOnDLA()to check if a layer can run on DLA as configured.getMaxDLABatchSize()for retrieving the maximum batch size that DLA can support.allowGPUFallback()to enable the GPU to execute layers that DLA does not support.
Please refer to Chapter 6 of the TensorRT 5.0 Developer Guide for the full list of supported layer configurations and code examples of working with DLA in TensorRT.
Deep Learning Inferencing Benchmarks
We’ve released deep learning inferencing benchmark results for Jetson AGX Xavier on common DNNs such as variants of ResNet, GoogleNet, and VGG. We ran these benchmarks for Jetson AGX Xavier using the JetPack 4.1.1 Developer Preview release with TensorRT 5.0 on Jetson AGX Xavier’s GPU and DLA engines. The GPU and two DLAs ran the same networks architectures concurrently in INT8 and FP16 precision respectively, with the aggregate performance being reported for each configuration. The GPU and DLAs can be running different networks or network models concurrently in real-world use cases, serving unique functions alongside each other in parallel or in a processing pipeline. Using INT8 versus full FP32 precision in TensorRT results in an accuracy loss of 1% or less.
First, let’s consider the results from ResNet-18 FCN (Fully Convolutional Network), which is a full-HD model with 2048×1024 resolution used for semantic segmentation. Segmentation provides per-pixel classification for tasks like freespace detection and occupancy mapping, and is representative of deep learning workloads computed by autonomous machines for perception, path planning, and navigation. Figure 6 shows the measured throughput of running ResNet-18 FCN on Jetson AGX Xavier versus Jetson TX2.
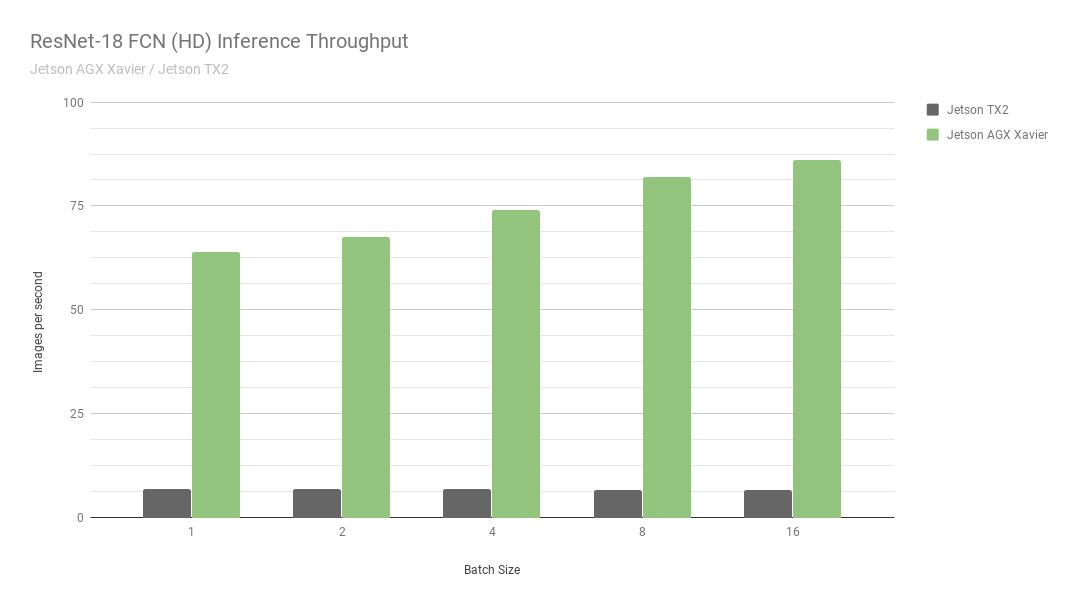
Jetson AGX Xavier currently achieves up to 13x the performance in ResNet-18 FCN inference as compared to Jetson TX2. NVIDIA will continue releasing software optimizations and feature enhancements in JetPack that will further improve performance and power characteristics over time. Note that the full listings of the benchmark results report the performance of ResNet-18 FCN for Jetson AGX Xavier up to batch size 32, however in figure 7 we only plot up to a batch size of 16, as Jetson TX2 is able to run ResNet-18 FCN up to batch size 16.
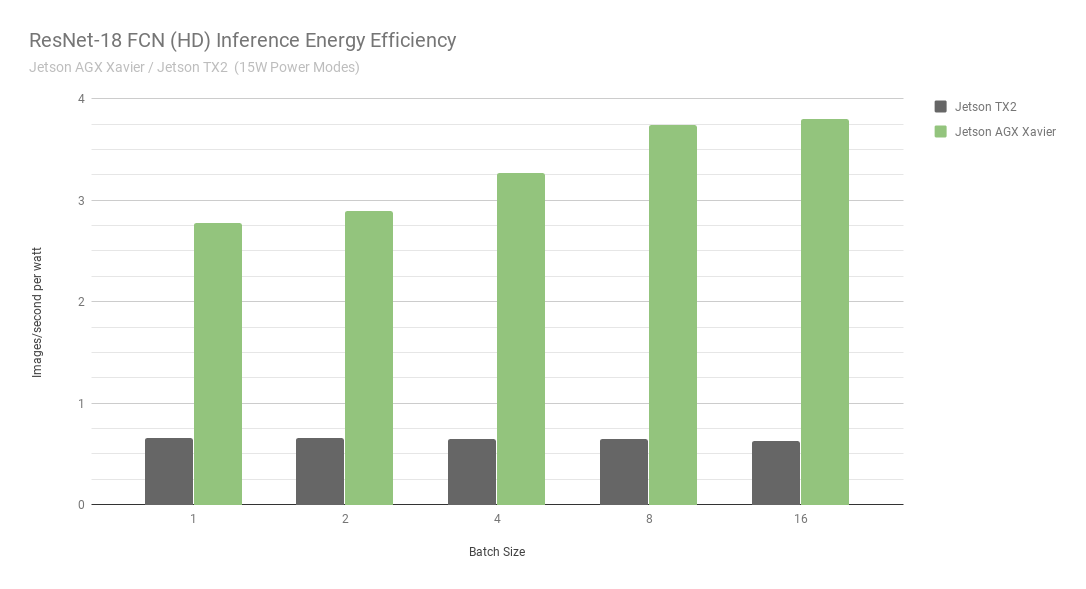
When considering energy efficiency using images processed per second per watt, Jetson AGX Xavier is currently up to 6x more power efficient than Jetson TX2 at ResNet-18 FCN. We calculated efficiency by measuring the total module power consumption using onboard INA voltage and current monitors, including the energy usage of CPU, GPU, DLAs, memory, miscellaneous SoC power, I/O, and regulator efficiency loses on all rails. Both Jetsons were run in 15W power mode. Jetson AGX Xavier and JetPack ship with configurable preset power profiles for 10W, 15W, and 30W, switchable at runtime using the nvpmodel power management tool. Users can also define their own customized profiles with different clocks and DVFS (Dynamic Voltage and Frequency Scaling) governor settings that have been tailored to achieve the best performance for individual applications.
Next, let’s compare Jetson AGX Xavier benchmarks on the image recognition networks ResNet-50 and VGG19 across batch sizes 1 through 128 versus Jetson TX2. These models classify image patches with 224×224 resolution, and are frequently used as the encoder backbone in various object detection networks. Using a batch size of 8 or higher at the lower resolution can be used to approximate the performance and latency of a batch size of 1 at higher resolutions. Robotic platforms and autonomous machines often incorporate multiple cameras and sensors which can be batch processed for increased performance, in addition to performing detection of regions-of-interest (ROIs) followed by further classification of the ROIs in batches. Figure 8 also includes estimates of future performance for Jetson AGX Xavier, incorporating of software enhancements such as INT8 support for DLA and additional optimizations for GPU.
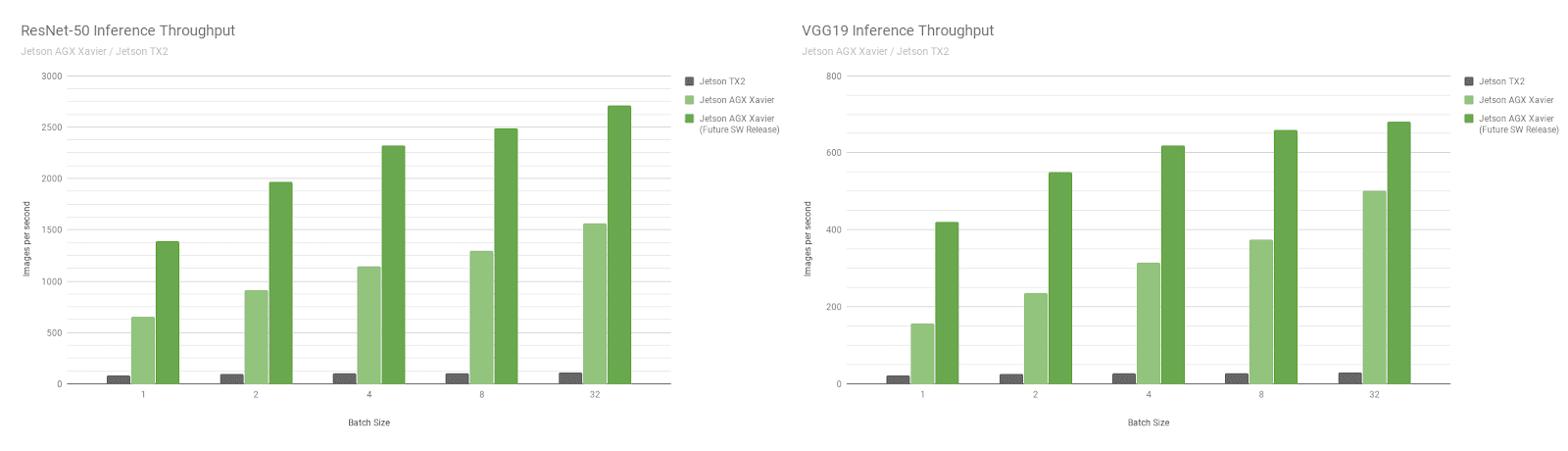
Jetson AGX Xavier currently achieves up to 18x the throughput of Jetson TX2 on VGG19 and 14x on ResNet-50 measured running the JetPack 4.1.1, as shown in figure 9. The latency of ResNet-50 is as low as 1.5ms, or over 650FPS with a batch size of 1. Jetson AGX Xavier is estimated to be up to 24x faster than Jetson TX2 with future software improvements. Note that for legacy comparisons we also provide data for GoogleNet and AlexNet in the full performance listings.
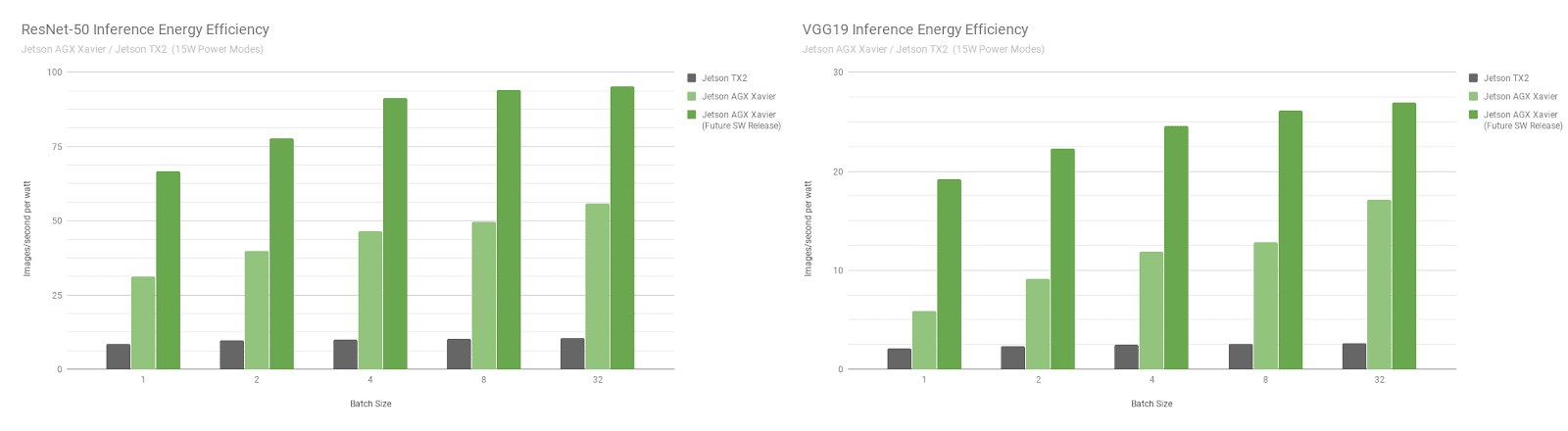
Jetson AGX Xavier is currently more than 7x more efficient at VGG19 inference than Jetson TX2 and 5x more efficient with ResNet-50, with up to a 10x increase in efficiency when considering future software optimizations and enhancements. Consult the full performance results for additional data and details about the inferencing benchmarks. We also benchmark the CPU performance in the next section.
Carmel CPU Complex
Jetson AGX Xavier’s CPU complex shown in figure 10 consists of four heterogeneous dual-core NVIDIA Carmel CPU clusters based on ARMv8.2 with a maximum clock frequency of 2.26GHz. Each core includes 128KB instruction and 64KB data L1 caches plus a 2MB L2 cache shared between the two cores. The CPU clusters share a 4MB L3 cache.

The Carmel CPU cores feature NVIDIA’s Dynamic Code Optimization, a 10-way superscalar architecture, and a full implementation of ARMv8.2 including full Advanced SIMD, VFP (Vector Floating Point), and ARMv8.2-FP16.
The SPECint_rate benchmark measures CPU throughput for multi-core systems. The overall performance score averages several intensive sub-tests, including compression, vector and graph operations, code compilation, and executing AI for games like chess and Go. Figure 11 shows benchmark results with a greater than 2.5x increase in CPU performance between generations.
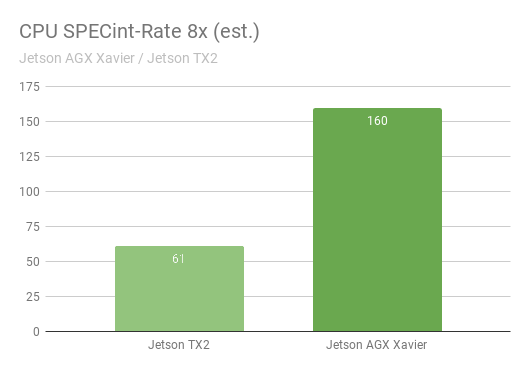
Eight simultaneous copies of the SPECint_rate tests ran, keeping the CPUs fully loaded. Jetson AGX Xavier naturally has eight CPU cores; Jetson TX2’s architecture uses four Arm Cortex-A57 cores and two NVIDIA Denver D15 cores. Running two copies per Denver core results in higher performance.
Vision Accelerator
Jetson AGX Xavier features two Vision Accelerator engines, shown in figure 12. Each includes a dual 7-way VLIW (Very Long Instruction Word) vector processor that offloads computer vision algorithms such as feature detection & matching, optical flow, stereo disparity block matching, and point cloud processing with low latency and low power. Imaging filters such as convolutions, morphological operators, histogramming, colorspace conversion, and warping are also ideal for acceleration.

Each Vision Accelerator includes a Cortex-R5 core for command and control, two vector processing units (each with 192KB of on-chip vector memory), and two DMA units for data movement. The 7-way vector processing units contain slots for two vector, two scalar, and three memory operations per instruction. The Early Access software release lacks support for the Vision Accelerator but will be enabled in a future version of JetPack.
NVIDIA Jetson AGX Xavier Developer Kit
The Jetson AGX Xavier Developer Kit contains everything needed for developers to get up and running quickly The kit includes the Jetson AGX Xavier compute module, reference open-source carrier board, power supply, and JetPack SDK, enabling users to quickly begin developing applications. The Jetson AGX Xavier Developer Kit can be purchased for only $1,299.

At 105mm2, the Jetson AGX Xavier Developer Kit is significantly smaller than the Jetson TX1 and TX2 Developer Kits while improving available I/O. I/O capabilities include two USB3.1 ports (supporting DisplayPort and Power Delivery), a hybrid eSATAp + USB3.0 port, a PCIe x16 slot (x8 electrical), sites for M.2 Key-M NVMe and M.2 Key-E WLAN mezzanines, Gigabit Ethernet, HDMI 2.0, and an 8-camera MIPI CSI connector. See Table 3 below for a full list of the I/Os available through the developer kit reference carrier board.
| Developer Kit I/Os | Jetson AGX Xavier Module Interface |
| PCIe x16 | PCIe x8 Gen 4 / SLVS x8 |
| RJ45 | Gigabit Ethernet |
| USB-C | 2x USB3.1 (DisplayPort optional) (Power Delivery optional) |
| Camera connector | 16x MIPI CSI-2 lanes, up to 6 active sensor streams |
| M.2 Key M | NVMe x4 |
| M.2 Key E | PCIe x1 (for Wi-Fi / LTE / 5G) + USB2 + UART + I2S/PCM |
| 40 pin header | UART + SPI + CAN + I2C + I2S + DMIC + GPIOs |
| HD Audio header | High Definition Audio |
| eSATAp + USB 3.0 | SATA via PCIe x1 bridge (Power + Data for 2.5” SATA) + USB3.0 |
| HDMI Type A | HDMI 2.0, eDP 1.2a, DP 1.4 |
| uSD/ UFS card socket | SD/UFS |
We’ve pulled together an open-source Two Days to a Demo deep learning tutorial for Jetson AGX Xavier that guides developers through training and deploying DNN inferencing to perform image recognition, object detection, and segmentation, enabling you to rapidly begin creating your own AI applications. Two Days to a Demo uses NVIDIA DIGITS interactive training system in the cloud or a GPU-accelerated PC, and uses TensorRT to perform accelerated inferencing on images or live camera feeds on Jetson. The Two Days to a Demo code repository on GitHub has been updated to include support for the Xavier DLAs and GPU INT8 precision.
Intelligent Video Analytics (IVA)
AI and deep learning enables vast amounts of data to be effectively utilized for keeping cities safer and more convenient, including applications such as traffic management, smart parking, and streamlined checkout experiences in retail stores. NVIDIA Jetson and NVIDIA DeepStream SDK enables distributed smart cameras to perform intelligent video analytics at the edge in real time, reducing the massive bandwidth loads placed on transmission infrastructure and improving security along with anonymity.
Video capture of IVA demo running on Jetson AGX Xavier with 30 concurrent HD streams
Jetson TX2 could process two HD streams concurrently with object detection and tracking. As shown in the video above, Jetson AGX Xavier is able to handle 30 independent HD video streams simultaneously at 1080p30 — a 15x improvement. Jetson AGX Xavier offers a total throughput of over 1850MP/s, enabling it to decode, pre-process, perform inferencing with ResNet-based detection, and visualize each frame in just over 1 millisecond. The capabilities of Jetson AGX Xavier bring greatly increased levels of performance and scalability to edge video analytics.
A New Era of Autonomy
Jetson AGX Xavier delivers unprecedented levels of performance onboard robots and intelligent machines. These systems require demanding compute capability for AI-driven perception, navigation, and manipulation in order to provide robust autonomous operation. Applications include manufacturing, industrial inspection, precision agriculture, and services in the home. Autonomous delivery robots that deliver packages to end consumers and support logistics in warehouses, stores, and factories represents one class of application.
A typical processing pipeline for fully-autonomous delivery and logistics requires several stages of vision and perception tasks, shown in figure 14. Mobile delivery robots frequently have several peripheral HD cameras that provide 360° situational awareness in addition to LIDAR and other ranging sensors that are fused in software along with inertial sensors. A forward-facing stereo driving camera is often used, needing pre-processing and stereo depth mapping. NVIDIA has created Stereo DNN models with improved accuracy over tradition block-matching methods to support this.

Object detection models like SSD or Faster-RCNN and feature-based tracking typically inform obstacle avoidance of pedestrians, vehicles, and landmarks. In the case of warehouse and storefront robots, these object detection models locate items of interest like products, shelves, and barcodes. Facial recognition, pose estimation, and Automatic Speech Recognition (ASR) facilitate Human-Machine Interaction (HMI) so that the robot can coordinate and communicate effectively with humans.
High-framerate Simultaneous Localization and Mapping (SLAM) is critical to keeping the robot updated with accurate position in 3D. GPS alone lacks precision for sub-meter positioning and is unavailable indoors. SLAM performs registration and alignment of the latest sensor data with the previous data the system has accumulated in its point cloud. Frequently noisy sensor data requires substantial filtering to properly localize, especially from moving platforms.
The path planning stage often uses semantic segmentation networks like ResNet-18 FCN, SegNet, or DeepLab to perform free-space detection, telling the robot where to drive unoccluded. Too many types of generic obstacles to detect and track individually frequently exist in the real world, so a segmentation-based approach labels every pixel or voxel with its classification. Together with the previous stages of the pipeline, this informs the planner and control loop of the safe routes that it can take.
The performance and efficiency of Jetson AGX Xavier makes it possible to process onboard all of the components needed in real-time for these robots to function safely with full autonomy, including high-performance vision algorithms for real-time perception, navigation, and manipulation. With standalone Jetson AGX Xavier modules now shipping in production, developers can deploy these AI solutions to the next generation of autonomous machines.
Start Building the Next Wave of Autonomous Machines Today
Jetson AGX Xavier brings game-changing levels of compute to robotics and edge devices, bringing high-end workstation performance to an embedded platform that’s been optimized for size, weight, and power. The production Jetson AGX Xavier compute module is now available globally through distribution, with volume pricing of $1,099 in quantities of 1000 units. Get started and become an NVIDIA Registered Developer today to take advantage of the $1,299 price for the Jetson AGX Xavier Developer Kit, including the ability to download platform documentation and the latest JetPack software for Jetson AGX Xavier. You can also connect with other developers in the community on the DevTalk forums.
For a deep-dive on the Jetson AGX Xavier architecture, view our On-Demand webinar, Jetson AGX Xavier and the New Era of Autonomous Machines.









