New TensorRT 6 Features Combine with Open-Source Plugins to Further Accelerate Inference
Inference is where AI goes to work. Identifying diseases. Answering questions. Recommending products and services. The inference market is also diffuse, and will happen everywhere from the data center to edge to IoT devices across multiple use-cases including image, speech and recommender systems to name a few. As a result, creating a benchmark to measure the performance of these diverse platforms and usages poses many challenges.
MLPerf, an industry-standard AI benchmark, seeks “…to build fair and useful benchmarks for measuring training and inference performance of ML hardware, software, and services.” In two rounds of testing on the training side, NVIDIA has consistently delivered leading results and record performances. MLPerf has since turned its attention to Inference, and results of MLPerf 0.5 Inference have recently been published. NVIDIA has landed top performance spots in data center and edge categories with our Turing architecture, and delivered highest performance across the edge and embedded categories with our Jetson Xavier platform across multiple workload types.
Here’s a brief description of MLPerf Inference’s use cases and benchmark scenarios.
Use cases are:
| Area | Task | Model | Dataset |
| Vision | Image classification | Resnet50-v1.5 | ImageNet (224×224) |
| Vision | Image classification | MobileNet-v1 | ImageNet (224×224) |
| Vision | Object detection | SSD-ResNet34 | COCO (1200×1200) |
| Vision | Object detection | SSD-MobileNet-v1 | COCO (300×300) |
| Language | Machine translation | GMNT | WMT16 |
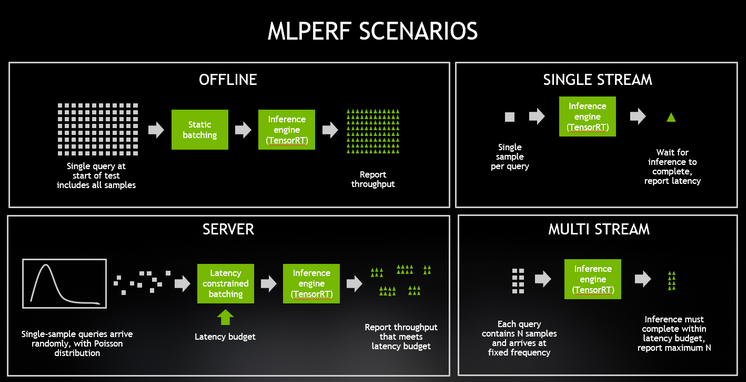
In terms of use-cases, MLPerf Inference 0.5 is strongly focused on computer vision, with four of five use-cases being image networks. The fifth, GNMT involves translation between German and English languages. The four image-focused use-cases use two network “backbones”: ResNet and MobileNet, which have been in the AI community for some time. More details about the benchmark’s inner workings are available from the MLPerf whitepaper. In this first version of MLPerf Inference, attention was focused on the benchmark’s overall evaluation framework, run-rules and its Load Generator, called LoadGen, which fires off workloads using different parameters depending on the benchmark scenario. Recall that one of the benchmark’s most ambitious design goals was to cover the span between data center, edge and IoT segments. To that end, the benchmark established four scenarios:
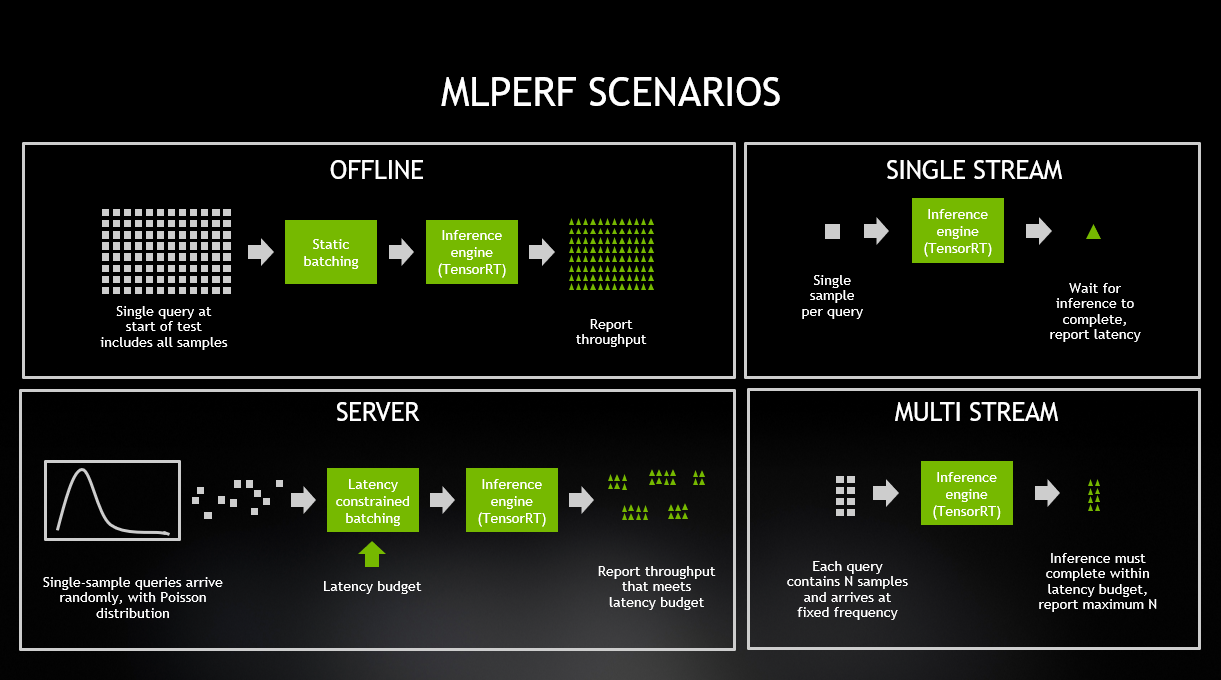
The Offline and Server scenarios are geared more toward data center platforms, whereas the single and multi-stream scenarios are more edge-focused. The result is that for each of the five benchmarks, different platforms were submitted for different scenarios. So it’s important to keep comparisons “apples to apples”, and not compare one platform’s Offline performance to another’s Multi-Stream on any given use-case.
Each of these test scenarios poses its own challenges. For instance, the Server scenario issues single-sample requests according to a Poisson distribution. This distribution, intended to model real-world traffic patterns, has periods of bursty traffic as well as lulls. The scenario also specifies a quality of service guarantee–a percentage of the traffic must be serviced within a benchmark-specific latency budget. For example, the Server Scenario for ResNet-50 requires that 99% of all requests be serviced within 15ms. One of the keys to performing well on this benchmark to to implement batching logic that accumulates as many samples as possible within the latency constraint and then sends them on for inference operations.
The Results Are In
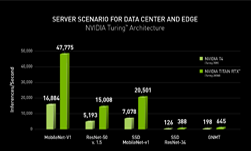
NVIDIA delivered top results in all four scenarios (Server, Offline, Single-Stream and Multi-Stream). NVIDIA delivered the best per-accelerator performance among commercially available products among all results submitted on all five of these benchmarks.
| NVIDIA Turing (70W) | NVIDIA Turing (280W) | ||||
| Server | Offline | Server | Offline | ||
| MobileNet-v1 | 16,884 | 17,726 | 49,775 | 55,597 | |
| ResNet-50 v. 1.5 | 5,193 | 5,622 | 15,008 | 16,563 | |
| SSD MobileNet-v1 | 7,078 | 7,609 | 20,503 | 22,945 | |
| SSD ResNet-34 | 126 | 137 | 388 | 415 | |
| GNMT | 198 | 354 | 654 | 1,061 | |
See MLPerf disclosures in end-notes.
The Single Stream scenario in MLPerf 0.5 sends the next query as soon as the system completes the previous query. The Multi-Stream scenario sends a new query at a fixed rate, with the unit of performance being maximum number of inferences per query supported. NVIDIA Jetson Xavier delivers the best performance of all commercially available SoCs with edge or mobile form factors, and was the only such device to run all four benchmarks shown above, again demonstrating Jetson’s performance and versatility.
| Xavier | ||
| Single Stream | Multi Stream | |
| MobileNet-v1 | 1,711 | 302 |
| ResNet-50 v. 1.5 | 491 | 100 |
| SSD MobileNet-v1 | 665 | 102 |
| SSD ResNet-34 | 34 | 2 |
See MLPerf disclosures in end-notes.
If you want to see all the performance numbers, go to the MLPerf Results Page.
TensorRT 6: Accelerating Inference Acceleration
We recently released TensorRT 6, whose optimizations deliver the highest inference across all GPU platforms. TensorRT played a pivotal role in NVIDIA’s top-tier performance on MLPerf Inference. The team here at NVIDIA that worked on our MLPerf Inference 0.5 submissions used several of TensorRT’s versatile plugins, which extend capabilities through CUDA-based plugins for custom operations, enabling developers to bring their own specific layers and kernels into TensorRT.
Since MLPerf 0.5 uses two image network backbones (ResNet and MobileNet) for the image classification and object detection usages, and then for translation uses the GNMT network. Here’s a rundown of some of the optimizations the team used for those benchmarks.
Several new features in TensorRT 6 made significant contributions to NVIDIA’s MLPerf Inference v0.5 results. These include:
Reformat Free I/O: Input data can be FP32, FP16 or INT8, and in any number of vector formats, which reduces the format layers needed to bring data in and convert it into specific formats.
Layer Fusion Brings Faster Kernels: By fusing ops found in layer kernels, AI applications can move inference samples through the network more quickly while not compromising accuracy. New in TensorRT 6 is a fusion of softmax+log+topK operations, which were three different kernels that now operate as a single kernel. These operations go beyond running just matrix multiplies (GEMMs) and can be applied to NLP models that make use of beam search.
Using INT8 for Portions of GNMT: The team implemented much of the decoder and scorer layers in INT8. Quantization operations made use of TensorRT’s standard calibrator, and then the rest of the pipeline was processed using FP16 or FP32 precision.
In addition, NVIDIA’s MLPerf Inference v0.5 team built several plugins available with our MLPerf submission. For instance, there’s a Persistent LSTM Plugin (called CgPersistentLSTMPlugin_TRT), which the team used to accelerate the GNMT encoder for small batches.
Next Steps
Today’s MLPerf Inference v0.5 results represent an important first milestone toward bringing independent industry benchmarks to the AI market. However, AI research continues to charge ahead with larger networks and data sets, as well as more demanding usages like real-time conversational AI that make use of pipelined ensemble networks. Large scale language models (LSLMs) such as BERT, GPT-2, and XL-Net have brought about exciting leaps in state-of-the-art accuracy for many natural language understanding (NLU) tasks. The MLPerf consortium continues its work to evolve both AI training and inference benchmarks, and NVIDIA looks forward to ongoing collaboration with the consortium to bring leading-edge usages into the benchmark in upcoming versions.
For today, you can access the scripts and plugins used for our MLPerf Inference v0.5 submission on the MLPerf GitHub page, as well as TensorRT 6, available here.
—
MLPerf Results Notes:
1) MLPerf v0.5 Inference results for data center server form factors and offline and server scenarios retrieved from www.mlperf.org on Nov. 6, 2019, from entries Inf-0.5-15,Inf-0. 5-16, Inf-0.5-19, Inf-0.5-21. Inf-0.5-22, Inf-0.5-23, Inf-0.5-25, Inf-0.5-26, Inf-0.5-27. Per-processor performance is calculated by dividing the primary metric of total performance by number of accelerators reported.
2) MLPerf v0.5 Inference results for edge form factors and single-stream and multi-stream scenarios retrieved from www.mlperf.org on Nov. 6, 2019, from entries Inf-0.5-24, Inf-0.5-28, Inf-0.5-29.
3) MLPerf name and logo are trademarks.