
NVIDIA CEO Jensen Huang described the NVIDIA® DGX-2™ server as “the world’s largest GPU” at its launch during GPU Technology Conference earlier this year. DGX-2 comprises 16 NVIDIA Tesla™ V100 32 GB GPUs and other top-drawer components (two 24 core Xeon CPUs, 1.5 TB of DDR4 DRAM memory, and 30 TB of NVMe storage) in a single system, delivering two petaFLOPS of performance, qualifying it as one of the most powerful supercomputers available all connected via the NVSwitch-powered NVLink fabric.
NVSwitch is what makes the DGX-2 the largest GPU, implying something more than the sum of its parts. It turns out that the most unassuming part in the DGX-2 server is what makes “the world’s largest GPU” claim possible. Let’s walk through how the new and innovative NVIDIA NVSwitch™ chip plus other engineering features enable the DGX-2 to be the world’s largest GPU.
Note: Information featured here comes from the Hot Chips 2018 featured presentation NVSwitch and DGX‑2 – NVIDIA’s NVLink-Switching Chip and Scale-Up GPU-Compute Server by Alex Ishii and Denis Foley.
Single GPU
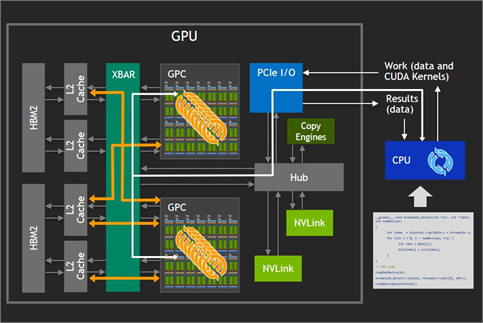
Let’s start with how a single multi-core GPU card interacts with a CPU as shown in figure 1. A programmer explicitly expresses parallel work using NVIDIA CUDA® technology. Work flows through the PCIe I/O port into the GPU, where data is distributed by the GPU driver to available Graphics Processing Clusters (GPC) and Streaming Multiprocessor (SM) cores. The XBAR is used so that the GPU/SM cores can exchange data on the L2 Cache and high bandwidth GPU memory (HBM2).
High bandwidth between the GPCs and the GPU memory allows massive compute capabilities, and fast synchronizations, but scale is limited by the requirement that data must fit in the local GPU memory to effectively use the high bandwidth provided by the XBAR.
Two GPUs (PCIe and NVLink)
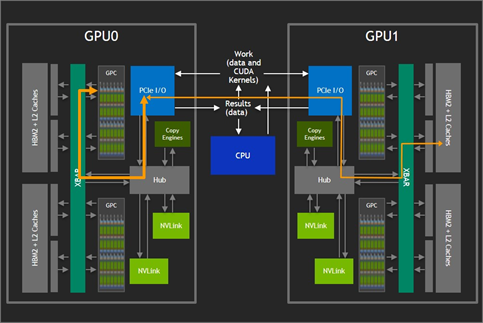
Figure 2 shows how adding another GPU card can increase the amount of available GPU memory. In the configuration shown, GPUs can access the memory on the other GPU only at the maximum bidirectional bandwidth of 32 GBps provided by PCIe. Moreover, these interactions compete with CPU operations on the bus which cuts in to the available bandwidth even further.
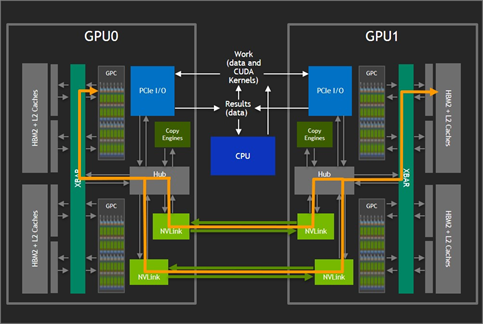
NVIDIA NVLink™ technology enables the GPCs to access remote GPU memory without going over the PCIe bus as figure 3 shows. The NVLinks effectively bridges between the XBARs. With up to six NVLinks available on V100 GPUs, bidirectional bandwidth between GPUs pushes 300 GBps. However, in systems with more than two GPUs, the six available NVLinks have previously had to be split into smaller groups of links with each group dedicated to the access of a single specific other GPU. This limited the scale of machines that could be built using direct attach and reduced the bandwidth between each pair of GPUs.
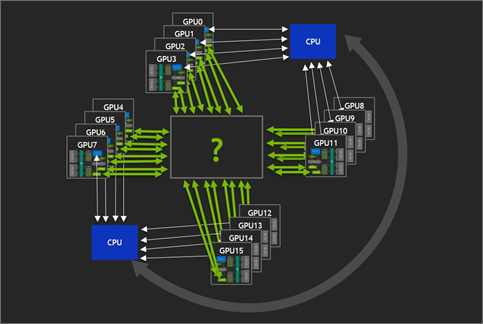
Super Crossbar Connecting the GPUs Together
Provide some sort of crossbar is the ideal, where a larger number of GPUs could each access all the GPU memory, all likely under the control of a single GPU Driver instance as figure 4 shows. With such a crossbar, GPU memory could be accessed without intervention from other processes, and available bandwidth would be high enough to provide performance scaling similar to the previous two GPU case.
Ultimately, the goal is to provide all of the following:
- Increased problem size capacity. Size would be limited by aggregate GPU memory capacity of the entire set of GPUs, rather than the capacity of a single GPU.
- Strong Scaling. NUMA-effects would be greatly reduced compared to existing solutions. Total memory bandwidth would actually grow with the number of GPUs.
- Ease-of-Use. Apps written for smaller number of GPUs would port more easily. In addition, the abundant resources could enable rapid experimentation.
The 16-GPU configuration illustrated aboe, which assumes 32GB V100 GPUs, yields an aggregate capacity which enables the ability to run “One Gigantic GPU” computations of unprecedented size.
Introducing the NVIDIA NVSwitch
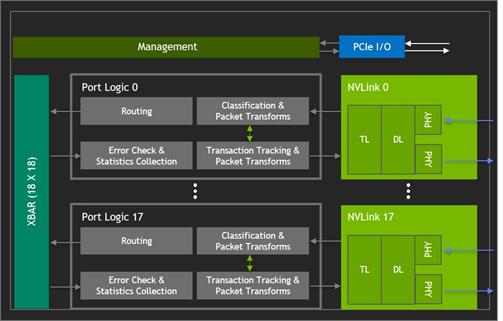
NVSwitch (figure 5) is a GPU-bridging device which provides the desired NVLink crossbar network. Packet-Transforms in the Port Logic blocks make traffic to/from multiple GPUs look like they are going to/from a single GPU.

NVSwitch chips run in parallel to support the interconnection of larger-and-larger numbers of GPUs. An eight-GPU closed system can be built with three NVSwitch chips. Two NVLinks paths connect each GPU to each switch, with traffic interleaved across all the NVLinks and NVSwitches. GPUs communicate pairwise using the full 300 GBps bidirectional bandwidth between any pair, because the NVSwitch chips provides unique paths from any source to any destination.
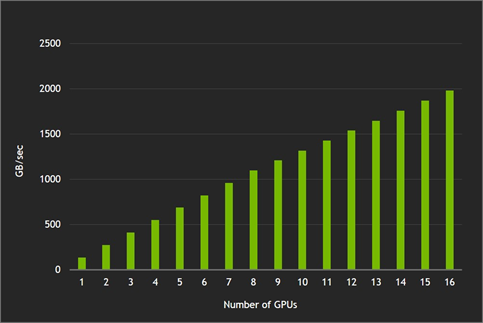
Achieved Bisection Bandwidth
This non-interfering pairwise communication capability is demonstrated by having each GPU reading data from another GPU with no two GPUs ever reading from the same remote GPU. The 1.98 TBps of read bandwidth achieved with 16 GPUs matches theoretical 80% bidirectional NVLink efficiency for 128B transfers.
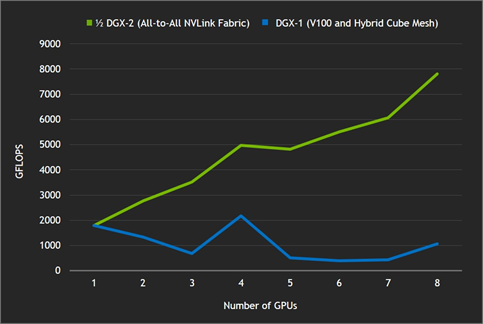
Strong Scaling with cuFFT (16K X 16K)
An example of strong-scaling performance can be obtained by running an “iso-problem instance” computation on more-and-more GPUs (more GFLOPS corresponding to shorter overall running time) versus an NVIDIA DGX-1 server with V100 GPUs, shown in figure 8. Without the NVLink crossbar provided by the NVSwitch network, as the problem is split over more GPUs it takes longer to transfer data than to simply calculate the same data locally.
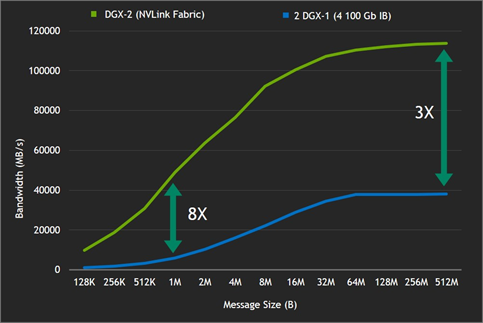
All-Reduce Benchmark
Figure 9 illustrates another demonstration of the advantages of the NVLink crossbar. The all-reduce benchmark measures an important communication primitive used in machine learning applications. The NVLink crossbar allows the 16-GPU DGX-2 server to provide increased bandwidth and lower latency compared to two eight-GPU servers (connected via InfiniBand). The NVLink network clearly providing efficiency superior to InfiniBand on smaller message sizes.
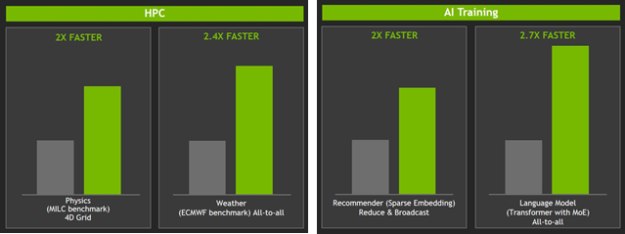
Speedups on HPC and AI Training Benchmarks
The HPC and AI training benchmarks shown in figure 10 offer performance boosts between 2 and 2.7 times faster when compared to two DGX-1 (V100) servers with the same total GPU count. The DGX-1 servers used have eight Tesla V100 32 GB GPUs and dual socket Xeon E5 2698v4 processors each. The servers were connected via four EDR IB/GbE ports.
Summary
The NVSwitch chip enables DGX-2 to be rightfully called the world’s largest GPU. NVSwitch is a non-blocking device which has 18-NVLink ports at 51.5 GBps per port and 928 GBps aggregate bidirectional bandwidth. When making use of the NVSwitch chip, the DGX-2 provides 512 GB of aggregate capacity and delivers performance on targeted applications which is over twice that of a pair of InfiniBand-connected DGX-1 servers.
Further information regarding the DGX-2 can be found here.
The NVSwitch is also used in the NVIDIA HGX-2, used by cloud service providers. More information on HGX-2 is available here.








