Posts by Tero Karras
Simulation / Modeling / Design
Dec 19, 2012
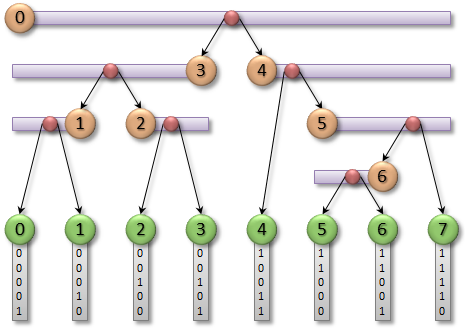
Thinking Parallel, Part III: Tree Construction on the GPU
In part II of this series, we looked at hierarchical tree traversal as a means of quickly identifying pairs of potentially colliding 3D objects and we...
17 MIN READ
Simulation / Modeling / Design
Nov 26, 2012
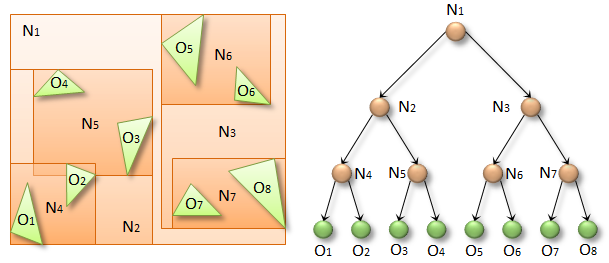
Thinking Parallel, Part II: Tree Traversal on the GPU
In the first part of this series, we looked at collision detection on the GPU and discussed two commonly used algorithms that find potentially colliding pairs...
14 MIN READ
Simulation / Modeling / Design
Nov 12, 2012
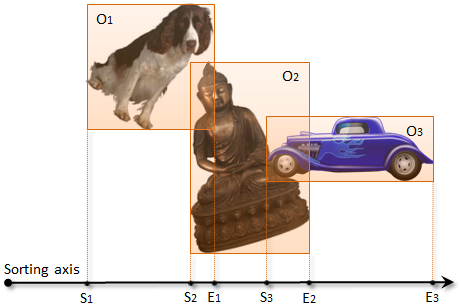
Thinking Parallel, Part I: Collision Detection on the GPU
This series of posts aims to highlight some of the main differences between conventional programming and parallel programming on the algorithmic level, using...
10 MIN READ