Nov 03, 2023
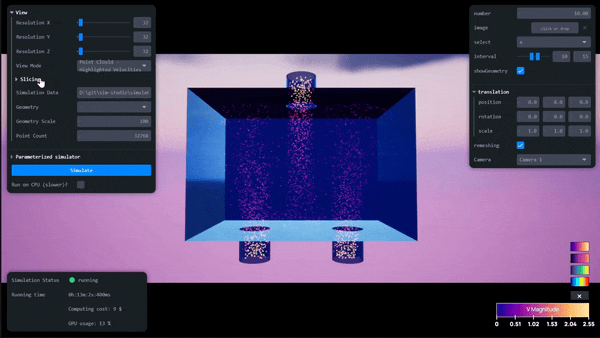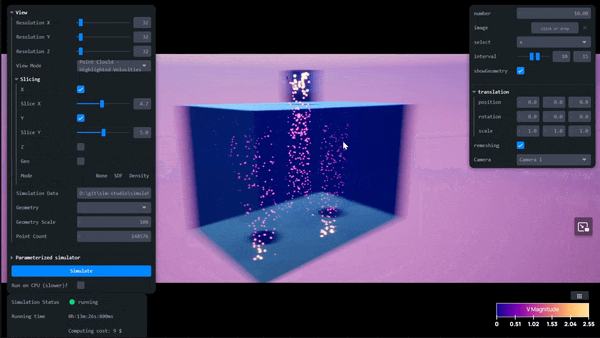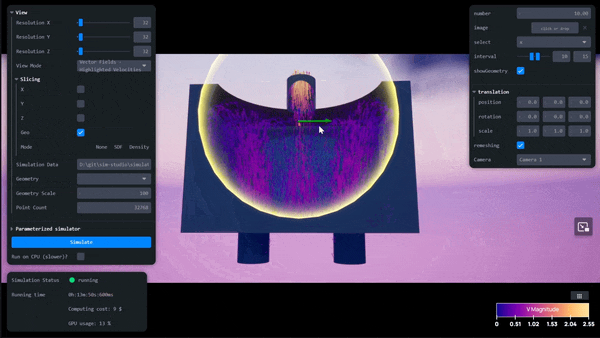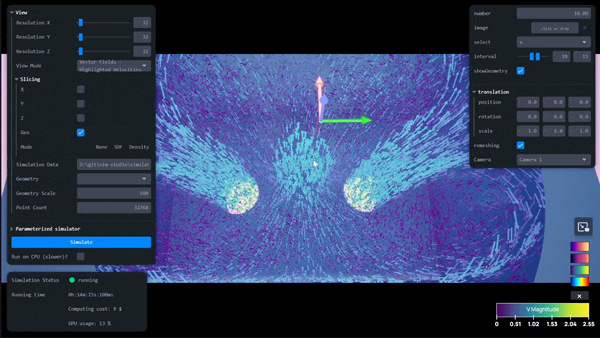
Analyze, Visualize, and Optimize Real-World Processes with OpenUSD in FlexSim
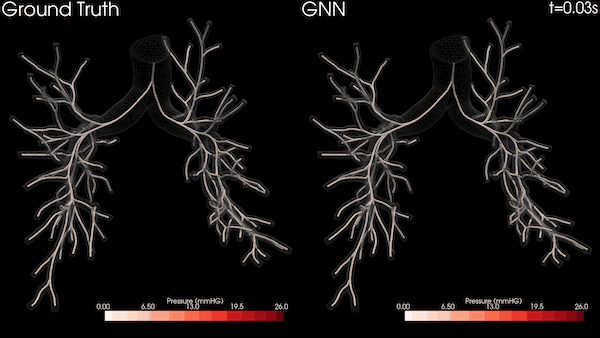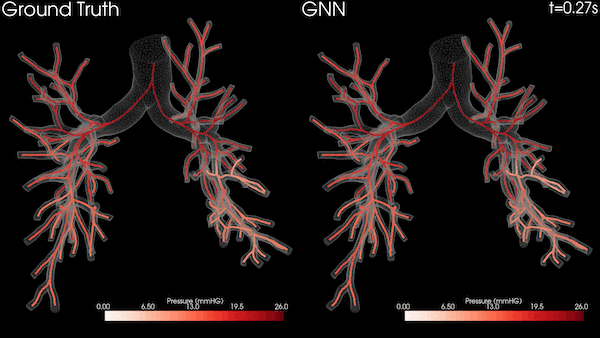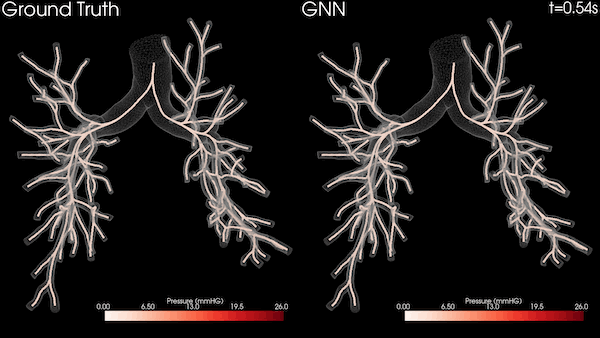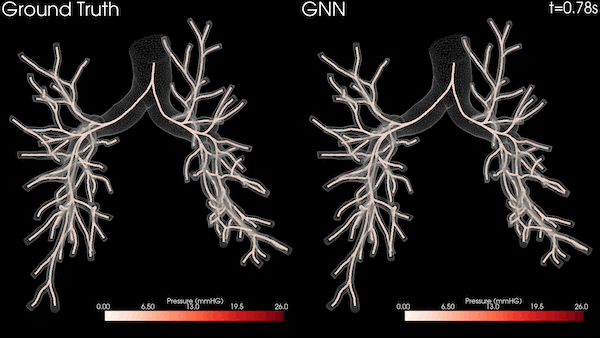
For manufacturing and industrial enterprises, efficiency and precision are essential. To streamline operations, reduce costs, and enhance productivity,...
6 MIN READ