Today I’m excited to announce the general availability of CUDA 8, the latest update to NVIDIA’s powerful parallel computing platform and programming model. In this post I’ll give a quick overview of the major new features of CUDA 8.
- Support for the Pascal GPU architecture, including the new Tesla P100, P40, and P4 accelerators;
- New Unified Memory capabilities;
- Native FP16 and INT8 computation for deep learning and other workloads;
- The new nvGRAPH GPU-Accelerated Graph Analytics library;
- Powerful new profiling capabilities;
- Improved compiler performance and heterogeneous lambda support; and
- Expanded developer platform support including Microsoft Visual Studio 2015 (updates 2 and 3) and GCC 5.4 (Ubuntu 16.04).
To learn more you can watch the recording of my talk from GTC 2016, “CUDA 8 and Beyond”.
CUDA 8 Supports the new NVIDIA Pascal Architecture
A crucial goal for CUDA 8 is to provide support for the powerful new Pascal architecture, the first incarnation of which was launched at GTC 2016: Tesla P100. For full details on P100 and the Pascal GP100 GPU architecture, check out the blog post “Inside Pascal”. One of NVIDIA’s goals is to support CUDA across the entire NVIDIA platform, so CUDA 8 supports all new Pascal GPUs, including Tesla P100, P40, and P4, as well as NVIDIA Titan X, and Pascal-based GeForce, Quadro, and DrivePX GPUs.
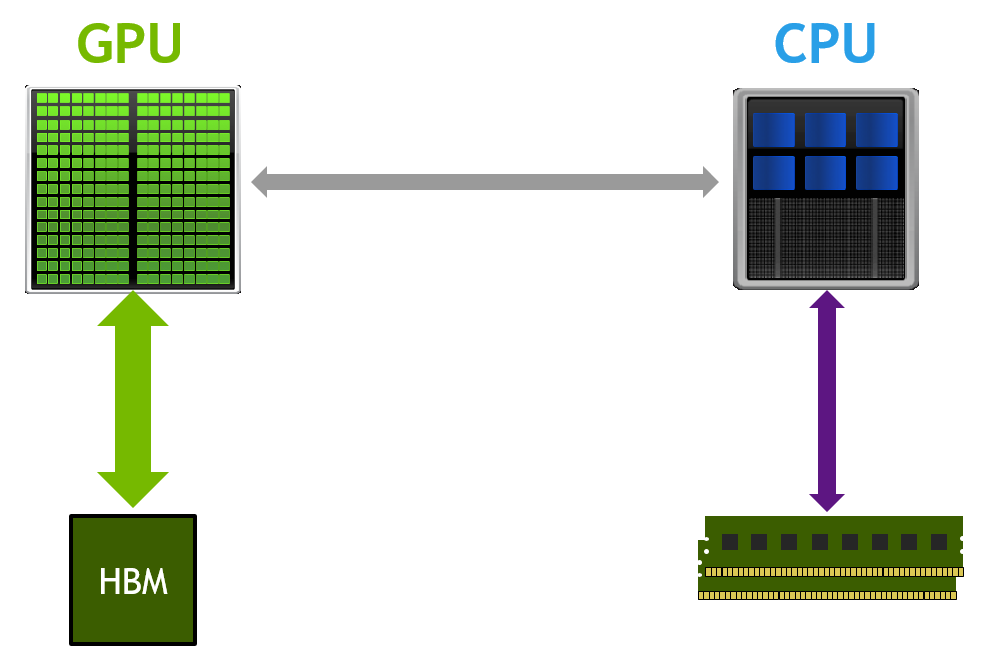
 In a nutshell, Tesla P100 provides massive double-, single- and half-precision computational performance, 3x the memory bandwidth of Maxwell GPUs via HBM2 stacked memory, and with its support for NVLink, up to 5x the GPU-GPU communication performance of PCI Express. Pascal also improves support for Unified Memory thanks to a larger virtual address space and a new page migration engine, enabling higher performance, oversubscription of GPU memory, and system-wide atomic memory operations.
In a nutshell, Tesla P100 provides massive double-, single- and half-precision computational performance, 3x the memory bandwidth of Maxwell GPUs via HBM2 stacked memory, and with its support for NVLink, up to 5x the GPU-GPU communication performance of PCI Express. Pascal also improves support for Unified Memory thanks to a larger virtual address space and a new page migration engine, enabling higher performance, oversubscription of GPU memory, and system-wide atomic memory operations.
CUDA 8 will enable CUDA applications to get high performance on Tesla P100 out of the box. Moreover, improvements in CUDA 8 enable developing efficient code for new Tesla P100 features such as NVLink and improved Unified Memory.
Unified Memory: Larger Datasets, Higher Performance, and More Control
Unified Memory is an important feature of the CUDA programming model that greatly simplifies programming and porting of applications to GPUs by providing a single, unified virtual address space for accessing all CPU and GPU memory in the system. Pascal GP100 features provide a significant advancement for GPU computing by expanding the capabilities and improving the performance of Unified Memory.
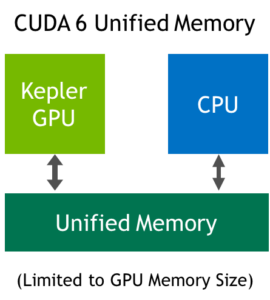
CUDA 6 introduced Unified Memory, which creates a pool of managed memory that is shared between the CPU and GPU, bridging the CPU-GPU divide. Managed memory is accessible to both the CPU and GPU using a single pointer. The CUDA system software automatically migrates data allocated in Unified Memory between GPU and CPU, so that it looks like CPU memory to code running on the CPU, and like GPU memory to code running on the GPU. For details of how Unified Memory in CUDA 6 and later simplifies porting code to the GPU, see the post “Unified Memory in CUDA 6”.
CUDA 6 Unified Memory was limited by the features of the Kepler and Maxwell GPU architectures: all managed memory touched by the CPU had to be synchronized with the GPU before any kernel launch; the CPU and GPU could not simultaneously access a managed memory allocation; and the Unified Memory address space was limited to the size of the GPU physical memory.

Pascal GP100 Unified Memory
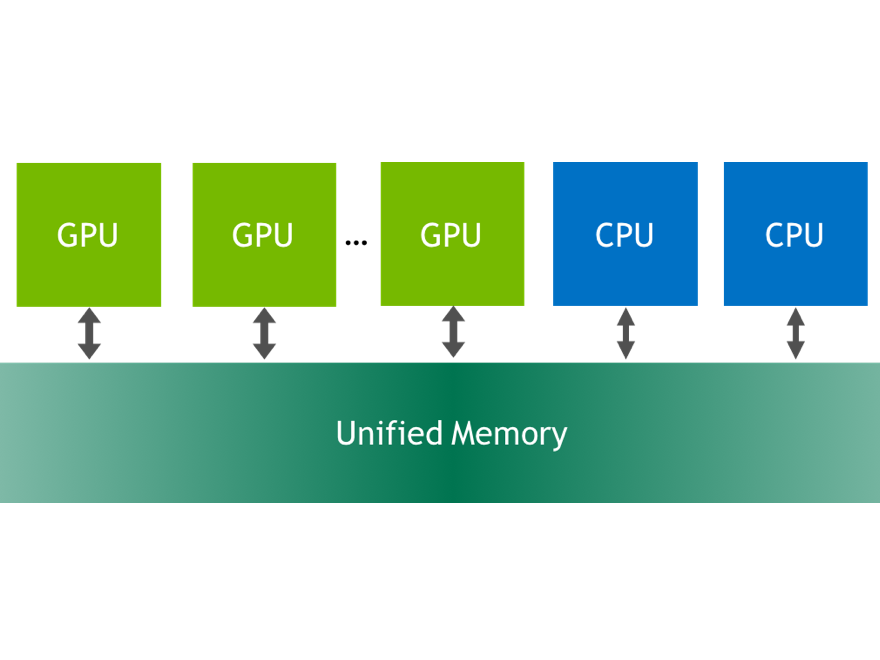
Expanding on the benefits of CUDA 6 Unified Memory, Pascal GP100 adds features to further simplify programming and sharing of memory between CPUs and GPUs. Unified Memory on Pascal also enables easier porting of CPU parallel computing applications to use GPUs for tremendous speedups. Two main hardware features enable these improvements: support for large address spaces and page faulting capability.
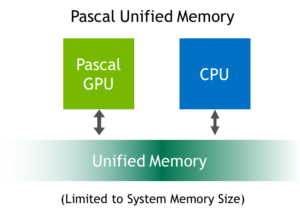
GP100 extends GPU addressing capabilities to enable 49-bit virtual addressing. This is large enough to cover the 48-bit virtual address spaces of modern CPUs, as well as the GPU’s own memory. Therefore, GP100 Unified Memory allows programs to access the full address spaces of all CPUs and GPUs in the system as a single virtual address space, unlimited by the physical memory size of any one processor.
Memory page faulting support in GP100 is a crucial new feature that provides more seamless Unified Memory functionality. Combined with the system-wide virtual address space, page faulting provides several benefits. First, page faulting means that the CUDA system software doesn’t need to synchronize all managed memory allocations to the GPU before each kernel launch. If a kernel running on the GPU accesses a page that is not resident in its memory, it faults, allowing the page to be automatically migrated to the GPU memory on-demand. Alternatively, the page may be mapped into the GPU address space for access over the PCIe or NVLink interconnects (mapping on access can sometimes be faster than migration). Note that Unified Memory is system-wide: GPUs (and CPUs) can fault on and migrate memory pages either from CPU memory or from the memory of other GPUs in the system.
With the new page fault mechanism, global data coherency is guaranteed with Unified Memory. This means that with GP100, the CPUs and GPUs can access Unified Memory allocations simultaneously. This was illegal on Kepler and Maxwell GPUs, because coherence could not be guaranteed if the CPU accessed a Unified Memory allocation while a GPU kernel was active. Note, as with any parallel application, developers need to ensure correct synchronization to avoid data hazards between processors.
Finally, on supporting platforms, memory allocated with the default OS allocator (e.g. ‘malloc’ or ‘new’) can be accessed from both GPU code and CPU code using the same pointer. On these systems, Unified Memory is the default: there is no need to use a special allocator or for the creation of a special managed memory pool. Moreover, GP100’s large virtual address space and page faulting capability enable applications to access the entire system virtual memory. This means that applications can oversubscribe the memory system: in other words they can allocate, access, and share arrays larger than the total physical capacity of the system, enabling out-of-core processing of very large datasets.
Certain operating system modifications are required to enable Unified Memory with the system allocator. NVIDIA is collaborating with Red Hat and working within the Linux community to enable this powerful functionality.
To learn more about the Tesla P100 accelerator and the Pascal architecture, see the blog post Inside Pascal.
Benefits of Unified Memory
There are two main ways that programmers benefit from Unified Memory.
Simpler programming and memory model
Unified Memory lowers the bar of entry to parallel programming on GPUs, by making explicit device memory management an optimization, rather than a requirement. Unified Memory lets programmers focus on developing parallel code without getting bogged down in the details of allocating and copying device memory. This makes it easier to learn to program GPUs and simpler to port existing code to the GPU. But it’s not just for beginners; Unified Memory also makes complex data structures and C++ classes much easier to use on the GPU. With GP100, applications can operate out-of-core on data sets that are larger than the total memory size of the system. On systems that support Unified Memory with the default system allocator, any hierarchical or nested data structure can automatically be accessed from any processor in the system.
Performance through data locality
By migrating data on demand between the CPU and GPU, Unified Memory can offer the performance of local data on the GPU, while providing the ease of use of globally shared data. The complexity of this functionality is kept under the covers of the CUDA driver and runtime, ensuring that application code is simpler to write. The point of migration is to achieve full bandwidth from each processor; the 750 GB/s of HBM2 memory bandwidth is vital to feeding the compute throughput of a GP100 GPU. With page faulting on GP100, locality can be ensured even for programs with sparse data access, where the pages accessed by the CPU or GPU cannot be known ahead of time, and where the CPU and GPU access parts of the same array allocations simultaneously.
An important point is that CUDA programmers still have the tools they need to explicitly optimize data management and CPU-GPU concurrency where necessary: CUDA 8 introduces useful APIs for providing the runtime with memory usage hints (cudaMemAdvise()) and for explicit prefetching (cudaMemPrefetchAsync()). These tools allow the same capabilities as explicit memory copy and pinning APIs without reverting to the limitations of explicit GPU memory allocation.
Unified Memory Support on Mac OS X
In addition to Pascal support in CUDA 8, CUDA 8 platform support for Unified Memory expands to Mac OS X. Now developers using Macs with NVIDIA GPUs can take advantage of the benefits and convenience of Unified Memory in their applications.
Graph Analytics
Graphs are mathematical structures used to model pairwise relations between objects. Graphs can be used to model many types of relations and processes in physical, biological, social and information systems, and their use is becoming increasingly common in the solutions to high-performance data analytics problems.
Corporations, scientists and non-profit groups have access to large graphs representing the social and commercial activities of their customers and users and there is tremendous untapped opportunity for them to use that data to communicate more effectively, create better product, and reduce waste by discovering valuable patterns in the information.

Cyberanalytics is the application of data mining, graph theory and networking technology to understand internet traffic patterns, especially toward detecting attacks on secure systems and identifying their sources. It may also be used in an ‘offensive’ capacity to identify central points of failure or critical paths in a network. Currently this is limited to mostly forensic, after-the-fact analysis, due to the large amounts of data involved and computation required, and the immaturity of tools in this area.
Graph analytics are very important since the internet is best described as a graph of links between computer systems. These links have a time-dependent nature as well, which makes cyberanalytics a dynamic graph problem. The goal is to increase performance at scale to move away from ‘forensic’ analytics and towards real-time, interactive analytics with the capability to respond to and even to prevent attacks. Key algorithms for analysis are Breadth First Search (BFS), Minimal Spanning Tree (MST), connected components (CC), Time dependent and congestion aware routing (shortest path), clustering, pagerank, partitioning, and pattern matching.
Genomics is the study of how genes interact in a cell and of variations in genes both over time and across a population. Humans have about 21000 genes which code for proteins, and a larger number of non-coding RNA strands which regulate the activity of those genes; each gene can typically produce several different proteins. These interactions can be described as graphs, and graph methods are used to find variations (branches) from a ‘standard’ genome (as far as one exists). Since each genome is unique, assembling a full sequence requires trying many options for branches and locations in a nearest-fit search. A human genome contains about 3 billion base pairs, so this search requires solving a very large graph problem. We can reduce it by two orders of magnitude by focusing on genes instead of bases and working with graph methods. Graph partitioning and shortest path search are key algorithms for genomics.
Introducing nvGRAPH
The computational requirements of large-scale graph processing for cyberanalytics, genomics, social network analysis and other fields demand powerful and efficient computing performance that only accelerators can provide. As more and more companies figure out how to capture data from customer interactions and networks of sensors, the need for real-time analysis of commercial-scale graph data will be ubiquitous. nvGRAPH is a new library of GPU-accelerated graph algorithms that aims to make real-time graph analytics possible without the need to spend time sampling or breaking up the data into smaller graphs.
The first release of nvGRAPH included in CUDA 8 supports some of the key algorithms mentioned above, and we intend to make nvGRAPH the fastest implementation on GPUs for all of the algorithms mentioned. Specifically, nvRank 1.0 supports PageRank, Single-Source Shortest Path, and Single-Source Widest Path. PageRank is an important algorithm useful in Internet and other search applications, recommendation engines, and social ad placement, among others. Single-Source Shortest Path is useful for path planning in robotics and autonomous vehicles and power network, logistics, and supply chain planning. Single-source widest path is useful for IP routing, chip design and EDA, and traffic sensitive routing.
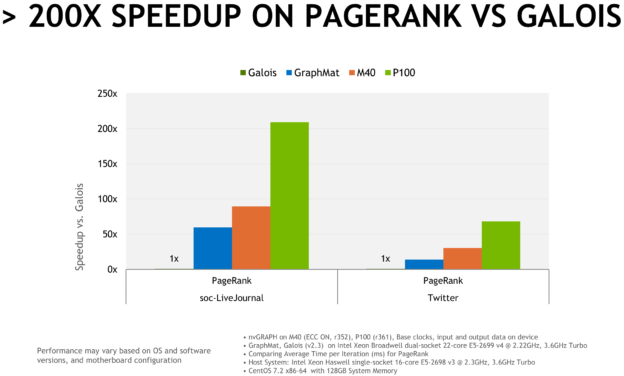
nvGRAPH 1.0 provides single-GPU implementations of these algorithms. nvGraph achieves a 4x speedup running PageRank on an 84-million-edge Wikipedia graph on a single K40 GPU, compared to a CPU implementation using MKL on a 48-core Xeon E5-2697. The chart above shows how nvGRAPH on P100 outperforms Galois running on dual-socket 22-core Xeon E5-2699 v4 CPUs by more than a factor of 200.
Mixed-Precision Computing
The combined use of different numerical precisions in a computational method is known as mixed precision. The NVIDIA Pascal architecture provides features aimed at providing even higher performance for applications that can utilize lower precision computation, by adding vector instructions that pack multiple operations into a 32-bit datapath. Specifically, these instructions operate on 16-bit floating point data (“half” or FP16) and 8- and 16-bit integer data (INT8 and INT16).
Some applications can get large performance or data size benefits from using lower-precision computation, compared to FP32 or FP64 floating point. For example, researchers in the rapidly growing field of deep learning have found that deep neural network architectures have a natural resilience to errors due to the backpropagation algorithm used in training them, and some have argued that 16-bit floating point (half precision, or FP16) is sufficient for training neural networks.
Storing FP16 (half precision) data compared to higher precision FP32 or FP64 reduces memory usage of the neural network, allowing training and deployment of larger networks, and FP16 data transfers take less time. Moreover, for many networks deep learning inference can be performed using 8-bit integer computations without significant impact on accuracy. In addition to deep learning, applications that use data from cameras, radios, and other real-world sensors often don’t require high-precision floating point computation, because the sensors generate low-precision or low dynamic range data.
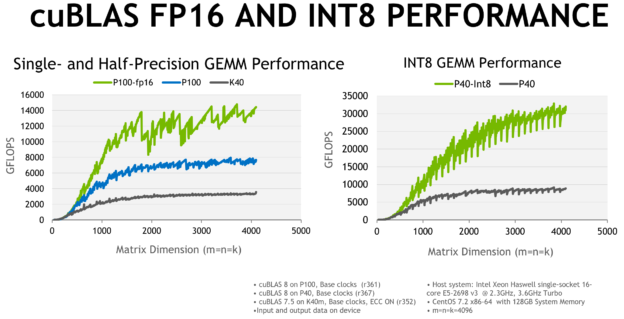
CUDA 8 provides a number of new features to enable you to develop applications that use FP16 and INT8 computation. CUDA libraries including cuBLAS, cuDNN, and cuFFT provide routines that use FP16 or INT8 for computation and/or data input and output. The chart below shows matrix-matrix multiplication performance on P100 and P40 using FP16 and INT8 computation, respectively.
To enable you to write your own code using these data types, CUDA provides built-in data types (e.g. half and half2) and intrinsics for FP16 arithmetic (e.g. __hadd(), __hmul(), __hfma2()) and new vector dot products that operate on INT8 and INT16 values (__dp4a(), __dp2a()).
I’ll be providing more details on mixed-precision programming in CUDA in an upcoming Parallel Forall blog post.
Powerful Profiling with Dependency Analysis
In heterogeneous applications that do significant computation on both CPUs and GPUs, it can be a challenge to locate the best place to spend your optimization effort. Ideally, when optimizing your code, you would like to target the locations in the application that will provide the highest speedup for the least effort. To this end, we are continuously improving the NVIDIA profiling tools: NSight, NVIDIA Visual Profiler (nvvp). CUDA 7.5 introduced PC sampling, providing instruction-level profiling so that you could pinpoint specific lines of code that are taking the most time in your application.
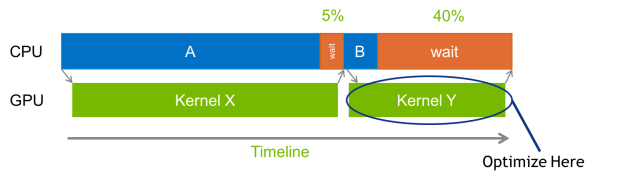
But the longest-running kernel in your application is not always the most critical optimization target. As the Figure 6 shows, sometimes a kernel with a shorter run time may be holding up the CPU from proceeding. In the image, Kernel X is the longest running, but speeding up Kernel Y will reduce the time the CPU spends waiting, so it is the best optimization target.
In CUDA 8, the Visual Profiler provides dependency analysis between GPU kernels and CPU CUDA API calls, enabling critical path analysis in your application to help you more profitably target your optimization effort. Figure 7 shows critical path analysis in the CUDA 8 Visual Profiler. You can see that with the critical path focused, GPU kernels, copies, and API calls that are not on the critical path are greyed out.
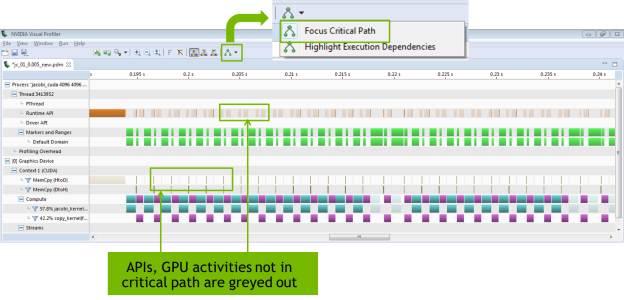
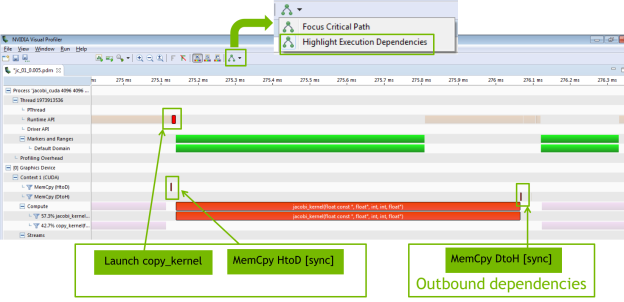
Figure 8 shows what happens when we highlight execution dependencies in the Visual Profiler.
More New Profiling Features
In addition to critical path analysis, CUDA 8 also provides the ability to profile both CPU and GPU code in the same application, to provide a list of CPU hotspots and call hierarchy, as well as visualizing the CPU source code in the profiler along with the GPU code.
With CUDA 8 you can also profile OpenACC code, just as you can with CUDA C++ code. And the Visual Profiler adds support for two important Pascal features: NVLink and Unified Memory. The profiler can show the topology of NVLink connections in your system and profile the bandwidth achieved across the links. For Unified Memory, it shows page faults and migrations on the timeline, and allows introspection into the sources of page faults.
Faster Compilation
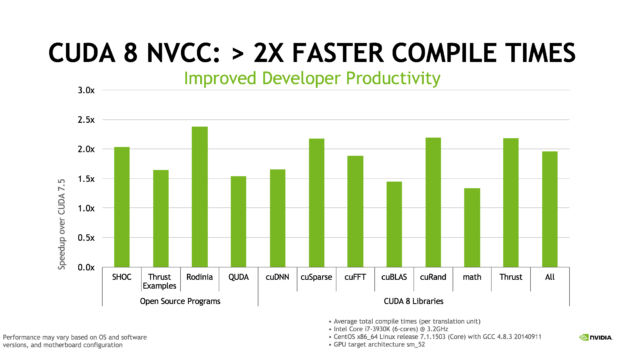
The NVCC compiler in CUDA 8 has been optimized for compilation time, so that you spend less time waiting for the CUDA files in your application to compile. Compilation time is 2x or more faster for a range of codes, especially those that heavily use C++ templates, such as Thrust and Eigen 3. Figure 9 shows some characteristic speedups.
Heterogeneous C++ Lambda
Lambda expressions are a powerful C++11 feature that enable anonymous functions (and closures) that can be defined in line with their use, can be passed as arguments, and can capture variables. I wrote at length about the C++11 features in CUDA 7 in my blog post The Power of C++11 Programming in CUDA 7. CUDA 7.5 extended this with experimental support for GPU lambdas: anonymous device function objects that you can define in host code, by annotating them with a __device__ specifier. (I wrote about CUDA 7.5 here.)
The GPU lambda support in CUDA 8 expands to support heterogeneous lambdas: lambda expressions annotated with a __host__ __device__ specifier, which allows them to be called on either the CPU or GPU, just like other __host__ __device__ functions.
Heterogeneous lambdas allow us to modify the Thrust SAXPY example from my CUDA 7.5 blog post so that it can run on either the CPU or GPU, as the following code shows.
void saxpy(float *x, float *y, float a, int N) {
using namespace thrust;
auto r = counting_iterator(0);
auto lambda = [=] __host__ __device__ (int i) {
y[i] = a * x[i] + y[i];
};
if(N > gpuThreshold)
for_each(device, r, r+N, lambda);
else
for_each(host, r, r+N, lambda);
}
GPU lambda support in CUDA 8 is experimental, and must be enabled by passing the flag --expt-extended-lambda to NVCC at compilation time.
Conclusion
CUDA 8 is the most feature-packed and powerful release of CUDA yet. CUDA 8 is available now for all developers. To get started with CUDA, download the latest CUDA Toolkit. To get a live walkthrough of all the goodies in the CUDA Toolkit version 8 sign up for our “What’s New” webinar Thursday, October 13.
To learn more about the Tesla P100 accelerator and the Pascal architecture, see the blog post Inside Pascal. To learn more about the Tesla P40 and P4 accelerators, see the blog post New Pascal GPUs Accelerate Inference in the Data Center.