
Many CUDA kernels are bandwidth bound, and the increasing ratio of flops to bandwidth in new hardware results in more bandwidth bound kernels. This makes it very important to take steps to mitigate bandwidth bottlenecks in your code. In this post, I will show you how to use vector loads and stores in CUDA C/C++ to help increase bandwidth utilization while decreasing the number of executed instructions.
Let’s begin by looking at the following simple memory copy kernel.
__global__ void device_copy_scalar_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < N; i += blockDim.x * gridDim.x) {
d_out[i] = d_in[i];
}
}
void device_copy_scalar(int* d_in, int* d_out, int N)
{
int threads = 128;
int blocks = min((N + threads-1) / threads, MAX_BLOCKS);
device_copy_scalar_kernel<<<blocks, threads>>>(d_in, d_out, N);
}
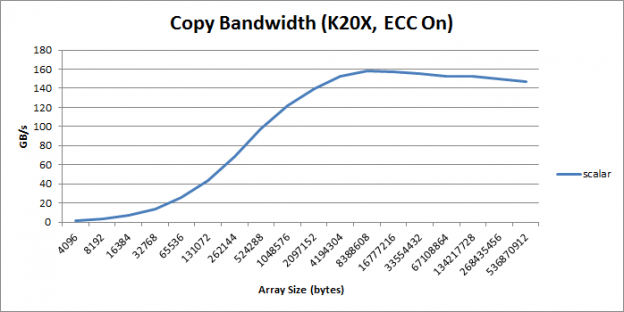
In this code, I am using grid-stride loops, described in an earlier CUDA Pro Tip post. Figure 1 shows the throughput of the kernel in GB/s as a function of copy size.
We can inspect the assembly for this kernel using the cuobjdump tool included with the CUDA Toolkit.
%> cuobjdump -sass executable
The SASS for the body of the scalar copy kernel is the following:
/*0058*/ IMAD R6.CC, R0, R9, c[0x0][0x140] /*0060*/ IMAD.HI.X R7, R0, R9, c[0x0][0x144] /*0068*/ IMAD R4.CC, R0, R9, c[0x0][0x148] /*0070*/ LD.E R2, [R6] /*0078*/ IMAD.HI.X R5, R0, R9, c[0x0][0x14c] /*0090*/ ST.E [R4], R2
Here we can see a total of six instructions associated with the copy operation. The four IMAD instructions compute the load and store addresses and the LD.E and ST.E load and store 32 bits from those addresses.
We can improve performance of this operation by using the vectorized load and store instructions LD.E.{64,128} and ST.E.{64,128}. These operations also load and store data but do so in 64- or 128-bit widths. Using vectorized loads reduces the total number of instructions, reduces latency, and improves bandwidth utilization.
The easiest way to use vectorized loads is to use the vector data types defined in the CUDA C/C++ standard headers, such as int2, int4, or float2. You can easily use these types via type casting in C/C++. For example in C++ you can recast the int pointer d_in to an int2 pointer using reinterpret_cast<int2*>(d_in). In C99 you can do the same thing using the casting operator: (int2*(d_in)).
Dereferencing those pointers will cause the compiler to generate the vectorized instructions. However, there is one important caveat: these instructions require aligned data. Device-allocated memory is automatically aligned to a multiple of the size of the data type, but if you offset the pointer the offset must also be aligned. For example reinterpret_cast<int2*>(d_in+1) is invalid because d_in+1 is not aligned to a multiple of sizeof(int2).
You can safely offset arrays if you use an “aligned” offset, as in reinterpret_cast<int2*>(d_in+2). You can also generate vectorized loads using structures as long as the structure is a power of two bytes in size.
struct Foo {int a, int b, double c}; // 16 bytes in size
Foo *x, *y;
…
x[i]=y[i];
Now that we have seen how to generate vectorized instructions let’s modify the memory copy kernel to use vector loads.
__global__ void device_copy_vector2_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < N/2; i += blockDim.x * gridDim.x) {
reinterpret_cast<int2*>(d_out)[i] = reinterpret_cast<int2*>(d_in)[i];
}
// in only one thread, process final element (if there is one)
if (idx==N/2 && N%2==1)
d_out[N-1] = d_in[N-1];
}
void device_copy_vector2(int* d_in, int* d_out, int n) {
threads = 128;
blocks = min((N/2 + threads-1) / threads, MAX_BLOCKS);
device_copy_vector2_kernel<<<blocks, threads>>>(d_in, d_out, N);
}
This kernel has only a few changes. First, the loop now executes only N/2 times because each iteration processes two elements. Second, we use the casting technique described above in the copy. Third, we handle any remaining elements which may arise if N is not divisible by 2. Finally, we launch half as many threads as we did in the scalar kernel.
Inspecting the SASS we see the following.
/*0088*/ IMAD R10.CC, R3, R5, c[0x0][0x140] /*0090*/ IMAD.HI.X R11, R3, R5, c[0x0][0x144] /*0098*/ IMAD R8.CC, R3, R5, c[0x0][0x148] /*00a0*/ LD.E.64 R6, [R10] /*00a8*/ IMAD.HI.X R9, R3, R5, c[0x0][0x14c] /*00c8*/ ST.E.64 [R8], R6
Notice that now the compiler generates LD.E.64 and ST.E.64. All the other instructions are the same. However, it is important to note that there will be half as many instructions executed because the loop only executes N/2 times. This 2x improvement in instruction count is very important in instruction-bound or latency-bound kernels.
We can also write a vector4 version of the copy kernel.
__global__ void device_copy_vector4_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for(int i = idx; i < N/4; i += blockDim.x * gridDim.x) {
reinterpret_cast<int4*>(d_out)[i] = reinterpret_cast<int4*>(d_in)[i];
}
// in only one thread, process final elements (if there are any)
int remainder = N%4;
if (idx==N/4 && remainder!=0) {
while(remainder) {
int idx = N - remainder--;
d_out[idx] = d_in[idx];
}
}
}
void device_copy_vector4(int* d_in, int* d_out, int N) {
int threads = 128;
int blocks = min((N/4 + threads-1) / threads, MAX_BLOCKS);
device_copy_vector4_kernel<<<blocks, threads>>>(d_in, d_out, N);
}
The corresponding SASS is the following:
/*0090*/ IMAD R10.CC, R3, R13, c[0x0][0x140] /*0098*/ IMAD.HI.X R11, R3, R13, c[0x0][0x144] /*00a0*/ IMAD R8.CC, R3, R13, c[0x0][0x148] /*00a8*/ LD.E.128 R4, [R10] /*00b0*/ IMAD.HI.X R9, R3, R13, c[0x0][0x14c] /*00d0*/ ST.E.128 [R8], R4
Here we can see the generated LD.E.128 and ST.E.128. This version of the code has reduced the instruction count by a factor of 4. You can see the overall performance for all 3 kernels in Figure 2.
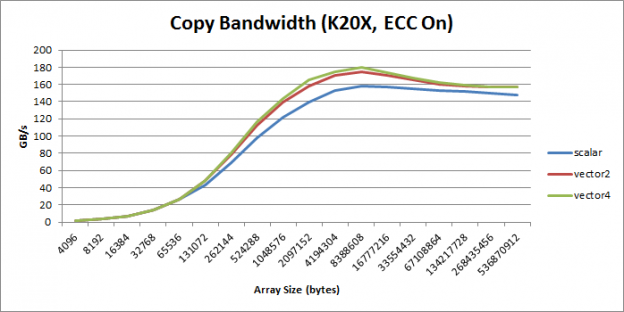
In almost all cases vectorized loads are preferable to scalar loads. Note however that using vectorized loads increases register pressure and reduces overall parallelism. So if you have a kernel that is already register limited or has very low parallelism, you may want to stick to scalar loads. Also, as discussed earlier, if your pointer is not aligned or your data type size in bytes is not a power of two you cannot use vectorized loads.
Vectorized loads are a fundamental CUDA optimization that you should use when possible, because they increase bandwidth, reduce instruction count, and reduce latency. In this post, I’ve shown how you can easily incorporate vectorized loads into existing kernels with relatively few changes.





