The Kepler architecture introduces texture objects, a new feature that makes textures easier to use and higher performance.
Texture References
Textures are likely a familiar concept to anyone who’s done much CUDA programming. A feature from the graphics world, textures are images that are stretched, rotated and pasted on polygons to form the 3D graphics we are familiar with. Using textures for GPU computing has always been a pro tip for the CUDA programmer; they enable fast random access to arrays and use a cache to provide bandwidth aggregation. On the flip side, the legacy texture reference API is cumbersome to use because it requires manual binding and unbinding of texture references to memory addresses, as the following code demonstrates. Also, texture references can only be declared as static global variables and cannot be passed as function arguments.
#define N 1024
texture<float, 1, cudaReadModeElementType> tex;
// texture reference name must be known at compile time
__global__ void kernel() {
int i = blockIdx.x *blockDim.x + threadIdx.x;
float x = tex1Dfetch(tex, i);
// do some work using x...
}
void call_kernel(float *buffer) {
// bind texture to buffer
cudaBindTexture(0, tex, buffer, N*sizeof(float));
dim3 block(128,1,1);
dim3 grid(N/block.x,1,1);
kernel <<<grid, block>>>();
// unbind texture from buffer
cudaUnbindTexture(tex);
}
int main() {
// declare and allocate memory
float *buffer;
cudaMalloc(&buffer, N*sizeof(float));
call_kernel(buffer);
cudaFree(buffer);
}
Texture Objects
Kepler GPUs and CUDA 5.0 introduce a new feature called texture objects (sometimes called bindless textures, since they don’t require manual binding/unbinding) that greatly improves the usability and programmability of textures. Texture objects use the new cudaTextureObject_t class API, whereby textures become first-class C++ objects and can be passed as arguments just as if they were pointers. There is no need to know at compile time which textures will be used at run time, which enables much more dynamic execution and flexible programming, as shown in the following code.
#define N 1024
// texture object is a kernel argument
__global__ void kernel(cudaTextureObject_t tex) {
int i = blockIdx.x *blockDim.x + threadIdx.x;
float x = tex1Dfetch<float>(tex, i);
// do some work using x ...
}
void call_kernel(cudaTextureObject_t tex) {
dim3 block(128,1,1);
dim3 grid(N/block.x,1,1);
kernel <<<grid, block>>>(tex);
}
int main() {
// declare and allocate memory
float *buffer;
cudaMalloc(&buffer, N*sizeof(float));
// create texture object
cudaResourceDesc resDesc;
memset(&resDesc, 0, sizeof(resDesc));
resDesc.resType = cudaResourceTypeLinear;
resDesc.res.linear.devPtr = buffer;
resDesc.res.linear.desc.f = cudaChannelFormatKindFloat;
resDesc.res.linear.desc.x = 32; // bits per channel
resDesc.res.linear.sizeInBytes = N*sizeof(float);
cudaTextureDesc texDesc;
memset(&texDesc, 0, sizeof(texDesc));
texDesc.readMode = cudaReadModeElementType;
// create texture object: we only have to do this once!
cudaTextureObject_t tex=0;
cudaCreateTextureObject(&tex, &resDesc, &texDesc, NULL);
call_kernel(tex); // pass texture as argument
// destroy texture object
cudaDestroyTextureObject(tex);
cudaFree(buffer);
}
Moreover, texture objects only need to be instantiated once, and are not subject to the hardware limit of 128 texture references, so there is no need to continuously bind and unbind them. (The Kepler hardware limit is over one million texture objects, a limit that will likely never be reached by any practical CUDA application in the lifetime of the architecture!) Using texture objects, the overhead of binding (up to 1 μs) and unbinding (up to 0.5 μs) textures is eliminated. What is not commonly known is that each outstanding texture reference that is bound when a kernel is launched incurs added launch latency—up to 0.5 μs per texture reference. This launch overhead persists even if the outstanding bound textures are not even referenced by the kernel. Again, using texture objects instead of texture references completely removes this overhead.
Strong Scaling in HPC
While these overheads may sound minor for any application that uses kernels that run for milliseconds or greater in duration, they are important for latency-sensitive, short-running kernels. High Performance Computing (HPC) applications that need strong scaling typify this use case. Strong scaling is how the solution time varies with the number of processors for a fixed global problem size. The goal is to solve a fixed problem in as short a time as possible. There is usually a limit to strong scaling, as at some point an application will become bound by the inter-processor communication bandwidth or latencies that arise from doing less work on each processor. Beyond this limit the total performance will actually decrease.
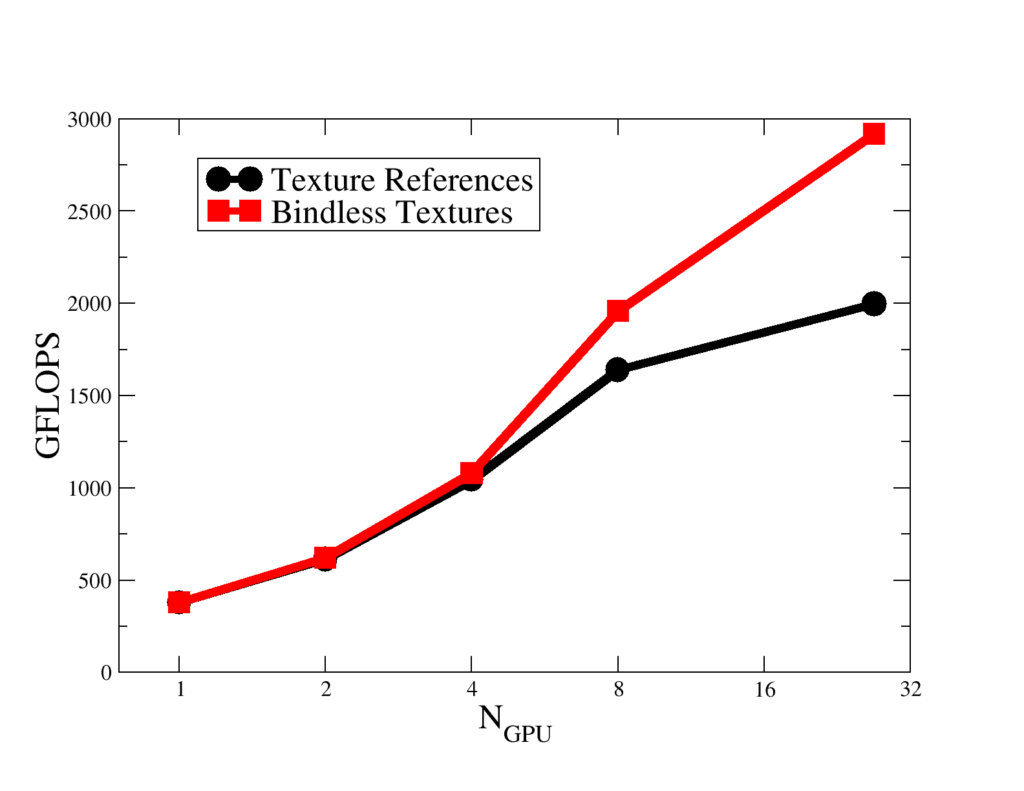
There are many large-scale HPC applications that will be running on the Titan supercomputer at Oak Ridge National Laboratory in Tennessee, for which achieving excellent strong scaling performance will be vital. Lattice Quantum Chromodynamics (LQCD) is one such application. LQCD uses a combination of sparse linear solvers, molecular dynamics algorithms and Monte Carlo methods to probe the structure of the nucleus. Using the highly optimized QUDA library, legacy LQCD applications MILC and Chroma can run on Titan making full use of the attached Tesla K20X accelerators. The QUDA library makes extensive use of textures, and using texture references the strong scaling tops out at 2 TFLOP/s, as you can see in Figure 1. Profiling using the CUDA visual profiler revealed that the overhead of texture binding and unbinding contributed significantly to time-critical communication routines running on the GPU. Moreover, many of the kernels run for O(10μs) using up to ten textures simultaneously. Thus the launch latency overhead is a significant bottleneck. Once the library was rewritten to use texture objects, strong scaling performance increased significantly and throughput increased to nearly 3 TFLOP/s at 27 GPUs (see Figure 1).
Texture objects are yet another powerful feature of the Kepler architecture that make it easier to achieve high performance and scalability with CUDA.