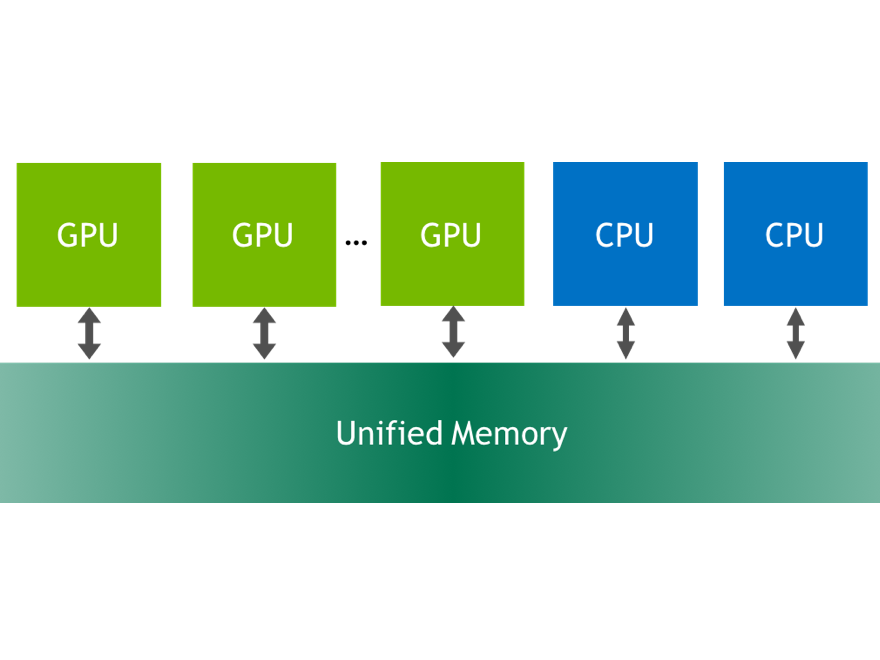
CUDA 6 introduces Unified Memory, which dramatically simplifies memory management for GPU computing. Now you can focus on writing parallel kernels when porting code to the GPU, and memory management becomes an optimization.
The CUDA 6 Release Candidate is now publicly available. In today’s CUDACast, I will show you some simple examples showing how easy it is to accelerate code on the GPU using Unified Memory in CUDA 6, and how powerful Unified Memory is for sharing C++ data structures between host and device code. If you’re interested in looking at the code in detail, you can find it in the Parallel Forall repository on GitHub. You can also check out the great Unified Memory post by Mark Harris.
To suggest a topic for a future episode of CUDACasts, or if you have any other feedback, please leave a comment below.