Some of the fastest computers in the world are cluster computers. A cluster is a computer system comprising two or more computers (“nodes”) connected with a high-speed network. Cluster computers can achieve higher availability, reliability, and scalability than is possible with an individual computer. With the increasing adoption of GPUs in high performance computing (HPC), NVIDIA GPUs are becoming part of some of the world’s most powerful supercomputers and clusters. The most recent top 500 list of the worlds fastest supercomputers included nearly 50 supercomputers powered by NVIDIA GPUs, and the current world’s fastest supercomputer, Oak Ridge National Labs TITAN, utilizes more than 18,000 NVIDIA Kepler GPUs.
In this post I will take you step by step through the process of designing, deploying, and managing a small research prototype GPU cluster for HPC. I will describe all the components needed for a GPU cluster as well as the complete cluster management software stack. The goal is to build a research prototype GPU cluster using all open source and free software and with minimal hardware cost.
I gave a talk on this topic at GTC 2013 (session S3516 – Building Your Own GPU Research Cluster Using Open Source Software Stack). The slides and a recording are available at that link so please check it out!
There are multiple motivating reason for building a GPU-based research cluster.
- Get a feel for production systems and performance estimates;
- Port your applications to GPUs and distributed computing (using CUDA-aware MPI);
- Tune GPU and CPU load balancing for your application;
- Use the cluster as development platform;
- Early experience means increased readiness;
- The investment is relatively small for a research prototype cluster
Figure 1 shows the steps to build a small GPU cluster. Let’s look at the process in more detail.

1. Choose Your Hardware
There are two steps to choosing the correct hardware.
- Node Hardware Details. This is the specification of the machine (node) for your cluster. Each node has the following components.
- CPU processor from any vendor;
- A motherboard with the following PCI-express connections:
- 2x PCIe x16 Gen2/3 connections for Tesla GPUs;
- 1x PCIe x8 wide for HCI Infiniband card;
- 2 available network ports;
- A minimum of 16-24 GB DDR3 RAM. (It is good to have more RAM in the system).
- A power-supply unit (SMPS) with ample power rating. The total power supply needed includes power taken by the CPU, GPUs and other components in the system.
- Secondary storage (HDD / SSD) based on your needs.
GPU boards are wide enough to cover two physically adjacent PCI-e slots, so make sure that the PCIe x16 and x8 slots are physically separated on the motherboard so that you can fit a minimum of 2 PCI-e x16 GPUs and 1 PCIe x8 network card.
- Choose the right form factor for GPUs. Once you decide your machine specs you should also decide which model GPUs you would like to consider for your system. The form factor of GPUs is an important consideration. Kepler-based NVIDIA Tesla GPUs are available in two main form factors.
- Tesla workstation products (C Series) are actively cooled GPU boards (this means they have a fan cooler over the GPU chip) that you can just plug in to your desktop computer in a PCI-e x16 slot. These use either two 6-pin or one 8-pin power supply connector.
- Server products (M Series) are passively cooled GPUs (no fans) installed in standard servers sold by various OEMs.
There are three different options for adding GPUs to your cluster:
- you can buy C-series GPUs and install them in existing workstations or servers with enough space;
- you can buy workstations from a vendor with C-series GPUs installed; or
- you can buy servers with M-series GPUs installed.
2. Allocate Space, Power and Cooling
The goal for this step is to assess your physical infrastructure, including space, power and cooling needs, network considerations and storage requirements to ensure optimal system choices with room to grow your cluster in the future. You should make sure that you have enough space, power and cooling for your cluster. Clusters are mainly rack mounted, with multiple machines installed in a vertical rack. Vendors offer many server solutions that minimize the use of rack space.
3. Assembly and Physical Deployment
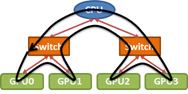
After deciding the machine configuration and real estate the next step is to physically deploy your cluster. Figure 2 shows the cluster deployment connections. The head node is the external interface to the cluster; it receives all external network connections, processes incoming requests, and assigns work to compute nodes (nodes with GPUs that perform the computation).
In a research prototype cluster you can also make use one of the compute nodes as a head node, but routing all traffic from the head node and also making it a compute node is not a good idea for production clusters because of performance and security issues. Production and large clusters mostly have a dedicated node to handle all incoming traffic while the head node just manages the work distribution for the compute nodes.

4. Head Node Installation
I recommend installing the head node with the open source Rocks Linux distribution. Rocks is a customizable, easy and quick way to install nodes. The Rocks installation package includes essential components for clusters, such as MPI. ROCKS head node installation is well-documented in the Rocks user guide, but here is a summary of the steps.
- Follow the steps in Chapter 3 of the Rocks user guide and do a CD-based installation.
- Install the NVIDIA drivers and CUDA Toolkit on the head node. (CUDA 5 provides a unified package that contain NVIDIA driver, toolkit and CUDA Samples.)
- Install network interconnect drivers (e.g. Infiniband) on the head node. These drivers are available from your interconnect manufacturer.
- Nagios® Core™ is an open source system and network monitoring application. It watches hosts and services that you specify, alerting you when things go wrong and when they get better. To install, follow the instructions given in the Nagios installation guide.
- The NRPE Nagios add-on allows you to execute Nagios plugins on remote Linux machines. This allows you to monitor local resources like CPU load and memory usage, which are not usually exposed to external machines, on remote machines using Nagios. Install NRPE following the install guide.
5. Compute Node Installation
After you have completed the head node installation, you will install the compute node software with the help of Rocks and the following steps.
- On the head node: in a terminal shell run the command:
> insert-ethers
Choose “Compute Nodes” as the new node to add.
- Power on the compute node with the Rocks CD as the first boot device or do a network installation.
- The compute node will connect to the head node and start the installation.
- Install the NRPE package as described in the NRPE guide.
6. Management and Monitoring
Once you finish the head node and all compute node installations, your cluster is ready to use! Before you actually start using it to run applications of interest, you should also set up management and monitoring tools on the cluster. These tools are necessary for proper management and monitoring of all resources available in cluster. In this section, I will describe various tools and software packages for GPU management and monitoring.
GPU System Management
The NVIDIA System Management Interface (NVIDIA-SMI) is a tool distributed as part of the NVIDIA GPU driver. NVIDIA-SMI provides a variety of GPU system information including
- thermal monitoring metrics: GPU temperature, chassis inlet/outlet temperatures;
- system Information: firmware revision, configuration information;
- system state: fan states, GPU faults, power system fault; ECC errors, etc.
NVIDIA-SMI allows you to configure the compute mode for any device in the system (Reference: CUDA C Programming Guide)
- Default compute mode: multiple host threads can use the device at the same time.
- Exclusive-process compute mode: Only one CUDA context may be created on the device across all processes in the system and that context may be current to as many threads as desired within the process that created the context.
- Exclusive-process-and-thread compute mode: Only one CUDA context may be created on the device across all processes in the system and that context may only be current to one thread at a time.
- Prohibited compute mode: No CUDA context can be created on the device.
NVIDIA-SMI also allows you to turn ECC (Error Correcting Code memory) mode on and off. The default is ON, but applications that do not need ECC can get higher memory bandwidth by disabling it.
GPU Monitoring with the Tesla Deployment Kit
The Tesla Deployment Kit is a collection of tools provided to better manage NVIDIA Tesla™ GPUs. These tools support Linux (32-bit and 64-bit), Windows 7 (64-bit), and Windows Server 2008 R2 (64-bit). The current distribution contains NVIDIA-healthmon and the NVML API.
NVML API
The NVML API is a C-based API which provides programmatic state monitoring and management of NVIDIA GPU devices. The NVML dynamic run-time library ships with the NVIDIA display driver, and the NVML SDK provides headers, stub libraries and sample applications. NVML can be used from Python or Perl (bindings are available) as well as C/C++ or Fortran.
Ganglia is an open-source scalable distributed monitoring system used for clusters and grids with very low per-node overhead and high concurrency. Ganglia gmond is an NVML-based Python module for monitoring NVIDIA GPUs in the Ganglia interface.
NVIDIA-HEALTHMON
This utility provides quick health checking of GPUs in cluster nodes. The tool detects issues and suggests remedies to software and system configuration problems, but it is not a comprehensive hardware diagnostic tool. Features include:
- basic CUDA and NVML sanity check;
- diagnosis of GPU failures;
- check for conflicting drivers;
- poorly seated GPU detection;
- check for disconnected power cables;
- ECC error detection and reporting;
- bandwidth test;
- infoROM validation.
7. Run Benchmarks and Applications
Once your cluster is up and running you will want to validate it by running some benchmarks and sample applications. There are various benchmarks and code samples for GPUs and the network as well as applications to run on the entire cluster. For GPUs, you need to run two basic tests.
- devicequery: This sample code is available with the CUDA Samples included in the CUDA Toolkit installation package. devicequery simply enumerates the properties of the CUDA devices present in a node. This is not a benchmark but successfully running this or any other CUDA sample serves to verify that you have the CUDA driver and toolkit properly installed on the system.
- bandwidthtest: This is another of the CUDA Samples included with the Toolkit. This sample measures the cudaMemcopy bandwidth of the GPU across PCI-e as well as internally. You should measure device-to-device copy bandwidth, host-to-device copy bandwidth for pageable and page-locked memory, and device-to-host copy bandwidth for pageable and page-locked memory.
To benchmark network performance, you should run the bandwidth and latency tests for your installed MPI distribution. MPI standard installations have standard benchmarks such as /tests/osu_benchmarks-3.1.1. You should consider using an open source CUDA-aware MPI implementation like MVAPICH2, as described in earlier Parallel Forall posts An Introduction to CUDA-Aware MPI and Benchmarking CUDA-Aware MPI.
To benchmark the entire cluster, you should run the LINPACK numerical linear algebra application. The top 500 supercomputers list uses the HPL benchmark to decide the fastest supercomputers on Earth. The CUDA-enabled version of HPL (High-Performance LINPACK) optimized for GPUs is available from NVIDIA on request, and there is a Fermi-optimized version available to all NVIDIA registered developers.
In this post I have provided an overview of the basic steps to build a GPU-accelerated research prototype cluster. For more details on GPU-based clusters and some of best practices for production clusters, please refer to Dale Southard’s GTC 2013 talk S3249 – Introduction to Deploying, Managing, and Using GPU Clusters by Dale Southard.