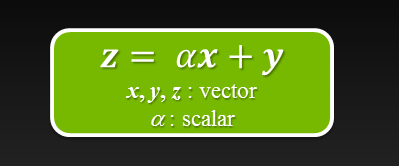Feb 25, 2015
Deep Speech: Accurate Speech Recognition with GPU-Accelerated Deep Learning
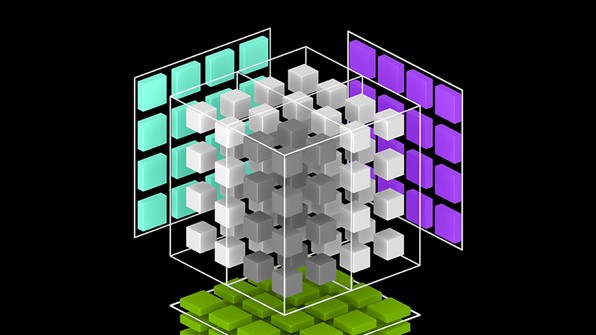
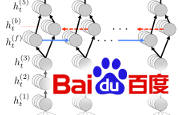
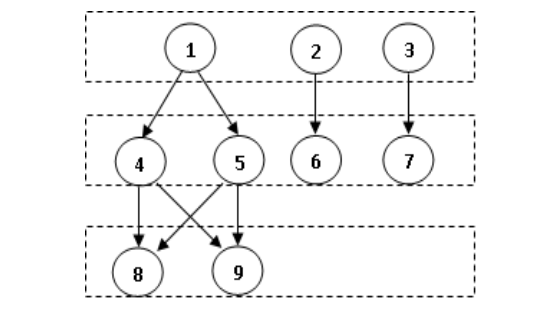
Speech recognition is an established technology, but it tends to fail when we need it the most, such as in noisy or crowded environments, or when the speaker is...
9 MIN READ