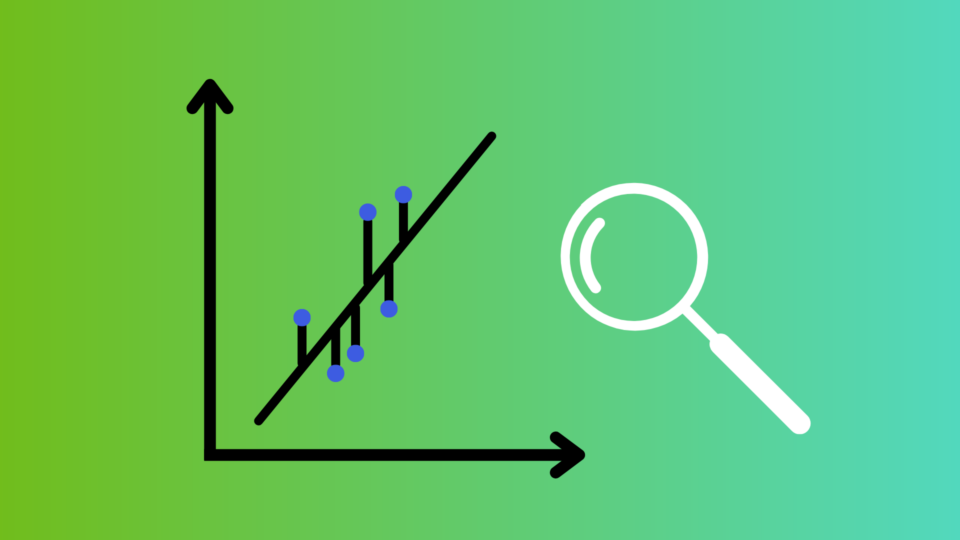
A Comprehensive Overview of Regression Evaluation Metrics
As a data scientist, evaluating machine learning model performance is a crucial aspect of your work. To do so effectively, you have a wide range of statistical...
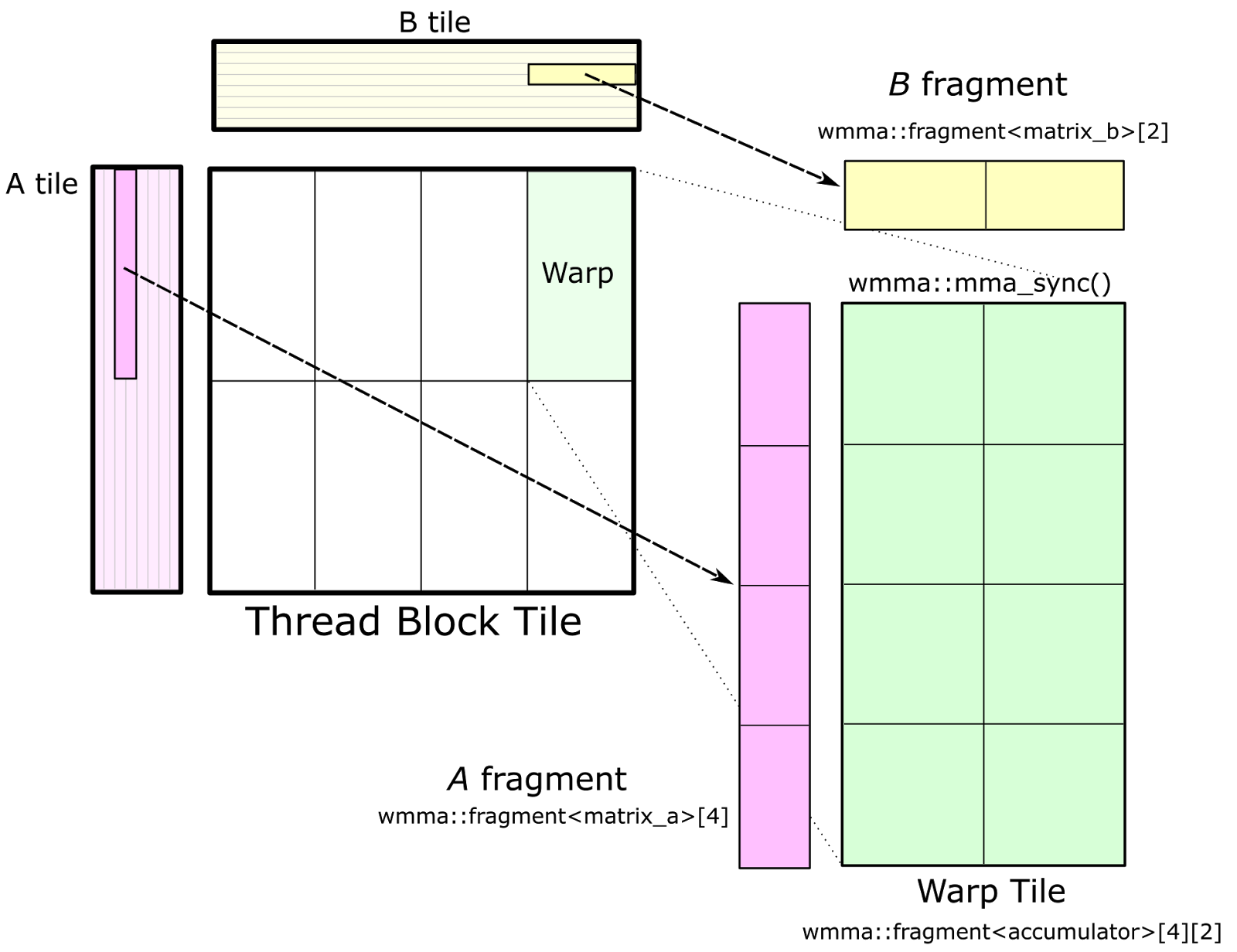
Update May 21, 2018: CUTLASS 1.0 is now available as Open Source software at the CUTLASS repository. CUTLASS 1.0 has changed substantially from our preview...
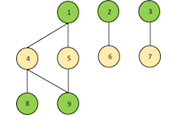
Graph Coloring: More Parallelism for Incomplete-LU Factorization
In this blog post I will briefly discuss the importance and simplicity of graph coloring and its application to one of the most common problems in sparse linear...
[Note: Lung Sheng Chien from NVIDIA also contributed to this post.] A key bottleneck for most science and engineering simulations is the solution of sparse...
Optimizing the High Performance Conjugate Gradient Benchmark on GPUs
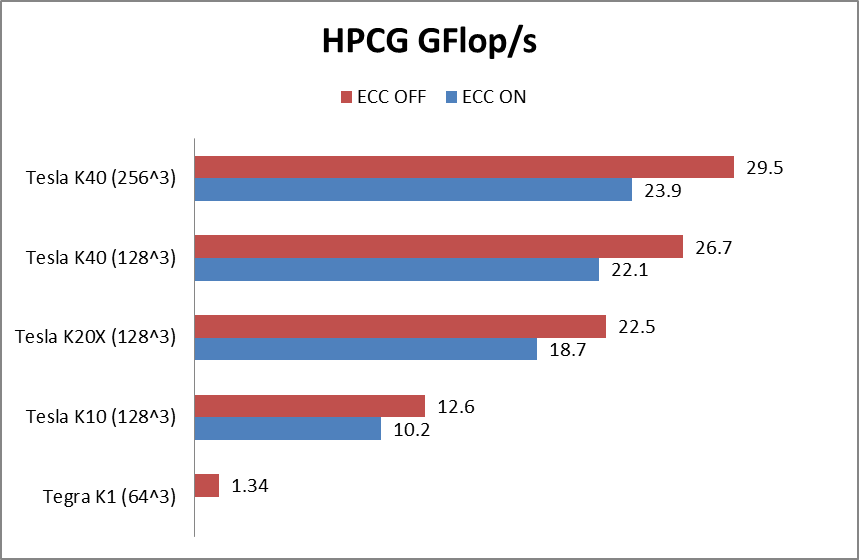
[This post was co-written by Everett Phillips and Massimiliano Fatica.] The High Performance Conjugate Gradient Benchmark (HPCG) is a new benchmark intended to...
CUDA Pro Tip: Fast and Robust Computation of Givens Rotations
A Givens rotation [1] represents a rotation in a plane represented by a matrix of the form $latex G(i, j, \theta) = \begin{bmatrix} 1 & \cdots & 0 &...