Jan 30, 2024
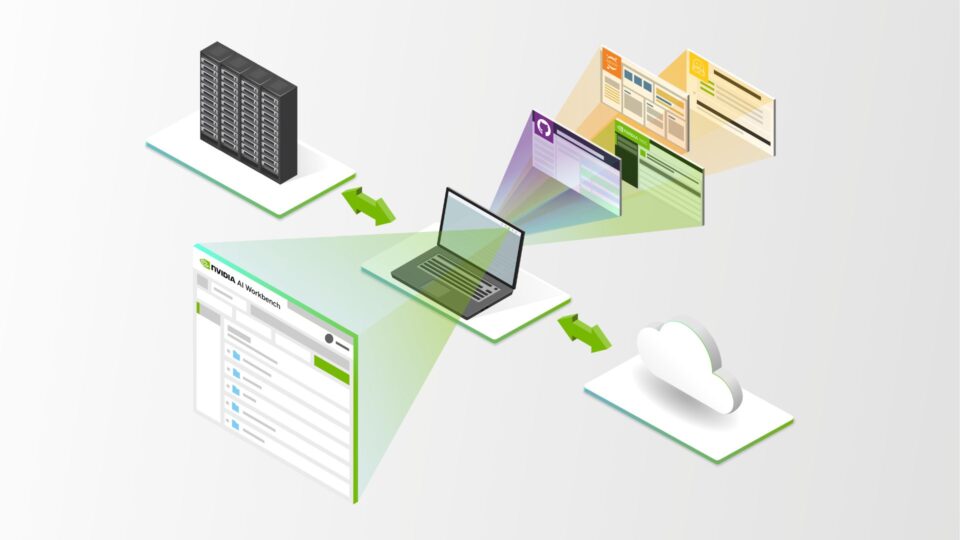
Create, Share, and Scale Enterprise AI Workflows with NVIDIA AI Workbench, Now in Beta
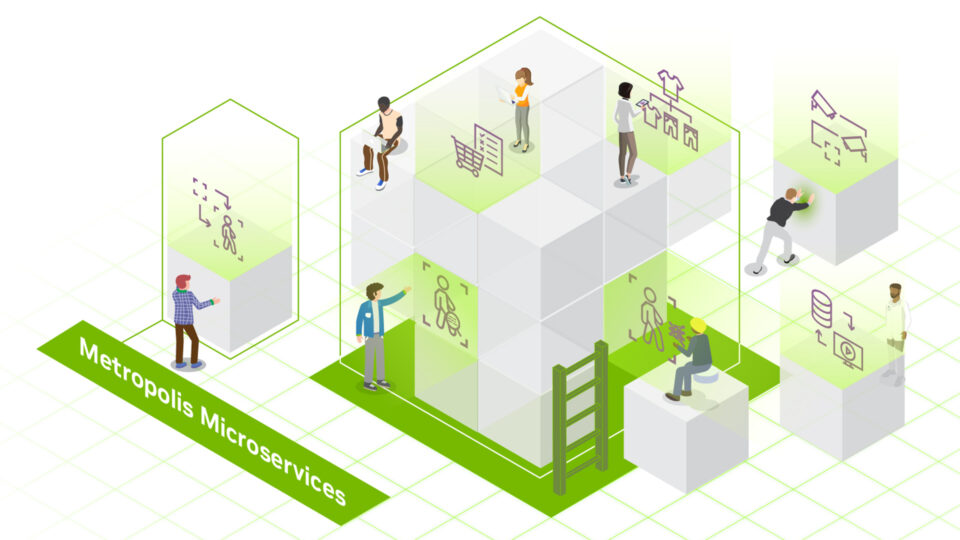
NVIDIA AI Workbench is now in beta, bringing a wealth of new features to streamline how enterprise developers create, use, and share AI and machine learning...
10 MIN READ