Streamline Live Media Application Development with New Features in NVIDIA Holoscan for Media
NVIDIA Holoscan for Media is a software-defined platform for building and deploying applications for live media. Recent updates introduce a user-friendly...
Software-Defined Broadcast with NVIDIA Holoscan for Media
The broadcast industry is undergoing a transformation in how content is created, managed, distributed, and consumed. This transformation includes a shift from...
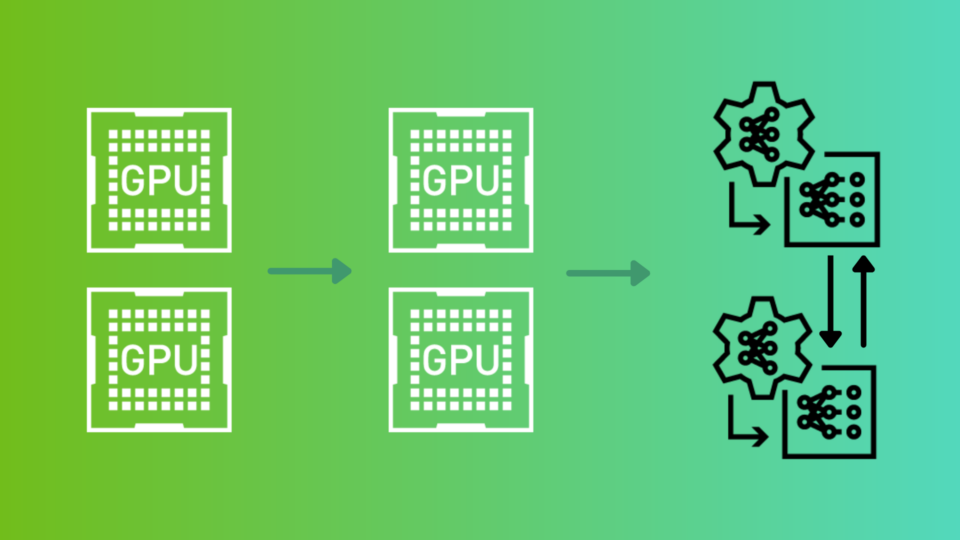
Unlocking Multi-GPU Model Training with Dask XGBoost
As data scientists, we often face the challenging task of training large models on huge datasets. One commonly used tool, XGBoost, is a robust and efficient...
Streamline Generative AI Development with NVIDIA NeMo on GPU-Accelerated Google Cloud
Generative AI has become a transformative force of our era, empowering organizations spanning every industry to achieve unparalleled levels of productivity,...
GPU Integration Propels Data Center Efficiency and Cost Savings for Taboola
When you see a context-relevant advertisement on a web page, it's most likely content served by a Taboola data pipeline. As the leading content recommendation...
Increasing Throughput and Reducing Costs for AI-Based Computer Vision with CV-CUDA
Real-time cloud-scale applications that involve AI-based computer vision are growing rapidly. The use cases include image understanding, content creation,...
GPUs continue to get faster with each new generation, and it is often the case that each activity on the GPU (such as a kernel or memory copy) completes very...
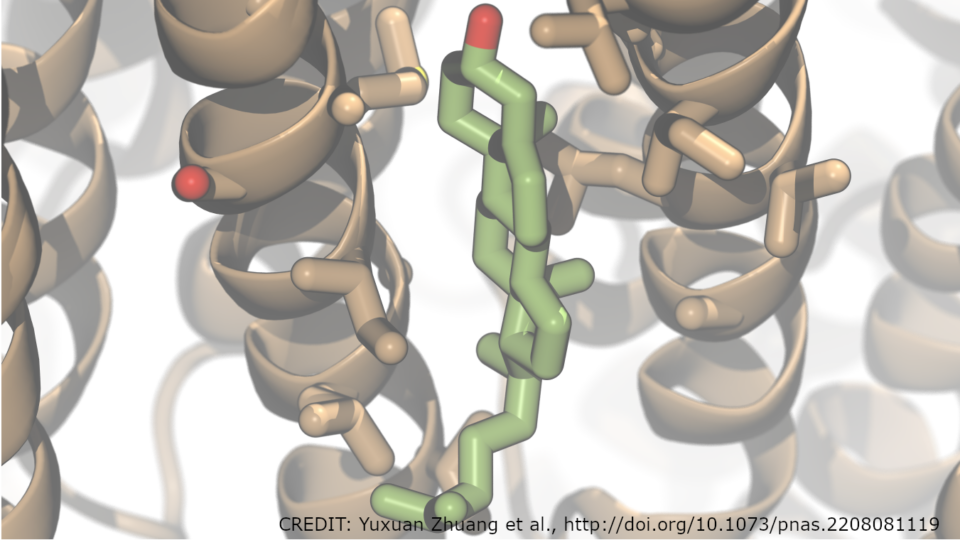
Using Carbon Capture and Storage Digital Twins for Net Zero Strategies
CO2 capture and storage technologies (CCS) catch CO2 from its production source, compress it, transport it through pipelines or by ships, and store it...
Learn the basic concepts, implementations, and applications of graph neural networks (GNNs) in this new self-paced course from NVIDIA Deep Learning Institute.
New Workshop: Data Parallelism: How to Train Deep Learning Models on Multiple GPUs
Learn how to decrease model training time by distributing data to multiple GPUs, while retaining the accuracy of training on a single GPU in this new instructor-led workshop.
New Asynchronous Programming Model Library Now Available with NVIDIA HPC SDK v22.11
Celebrating the SuperComputing 2022 international conference, NVIDIA announces the release of HPC Software Development Kit (SDK) v22.11. Members of the NVIDIA...