Jul 17, 2023
GPUs for ETL? Run Faster, Less Costly Workloads with NVIDIA RAPIDS Accelerator for Apache Spark and Databricks
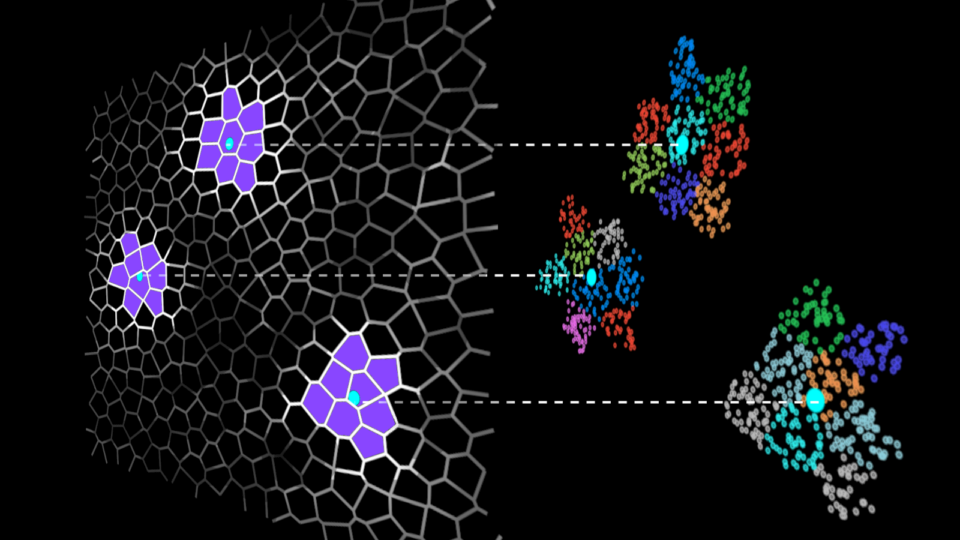
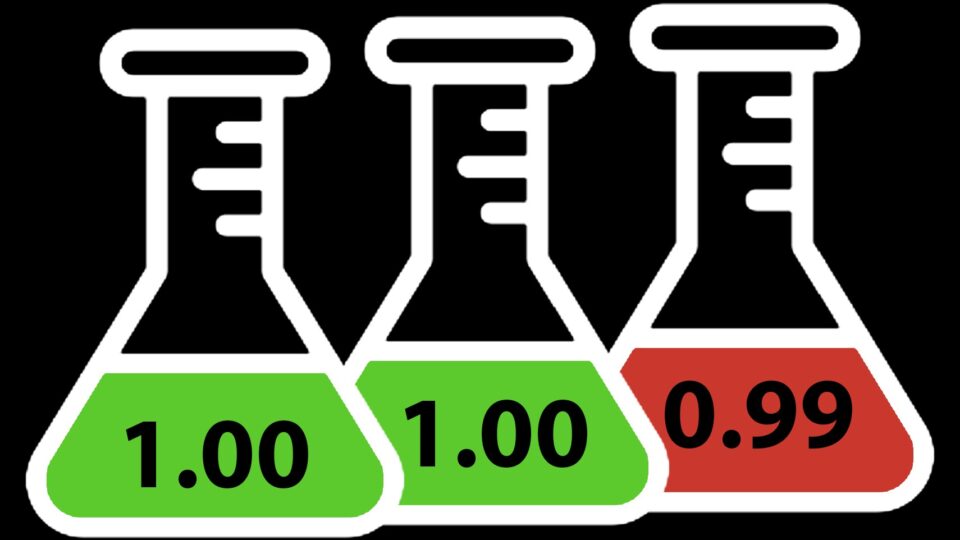
We were stuck. Really stuck. With a hard delivery deadline looming, our team needed to figure out how to process a complex extract-transform-load (ETL) job on...
7 MIN READ