Accelerated computing uses parallel processing to speed up work on demanding applications, from AI and data analytics to simulations and visualizations.
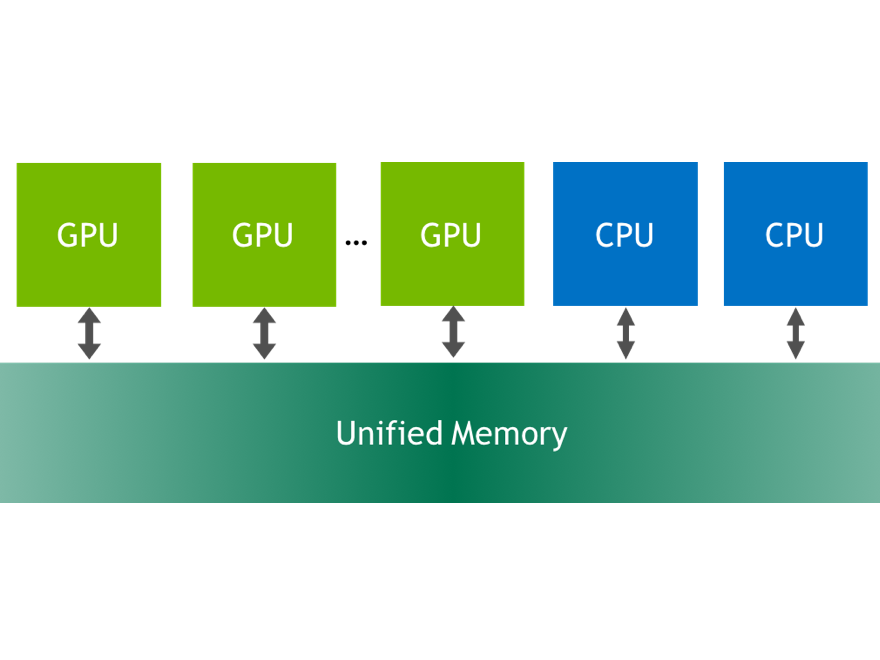
Many of today's applications process large volumes of data. While GPU architectures have very fast HBM or GDDR memory, they have limited capacity. Making the...
My previous introductory post, "An Even Easier Introduction to CUDA C++", introduced the basics of CUDA programming by showing how to write a simple program...
New Pascal GPUs Accelerate Inference in the Data Center
Artificial intelligence is already more ubiquitous than many people realize. Applications of AI abound, many of them powered by complex deep neural networks...
At the 2016 GPU Technology Conference in San Jose, NVIDIA CEO Jen-Hsun Huang announced the new NVIDIA Tesla P100, the most advanced accelerator ever built....
Today I'm excited to announce the general availability of CUDA 8, the latest update to NVIDIA's powerful parallel computing platform and programming model. In...
NVLink, Pascal and Stacked Memory: Feeding the Appetite for Big Data
For more recent info on NVLink, check out the post, "How NVLink Will Enable Faster, Easier Multi-GPU Computing". NVIDIA GPU accelerators have emerged in...