Today OpenAI, a non-profit artificial intelligence research company, launched OpenAI Gym, a toolkit for developing and comparing reinforcement learning algorithms. It supports teaching agents everything from walking to playing games like Pong or Go.

OpenAI researcher John Schulman shared some details about his organization, and how OpenAI Gym will make it easier for AI researchers to design, iterate and improve their next generation applications. John studied physics at Caltech, and went to UC Berkeley for graduate school. There, after a brief stint in neuroscience, he studied machine learning and robotics under Pieter Abbeel, eventually honing in on reinforcement learning as his primary topic of interest. John lives in Berkeley, California, where he enjoys running in the hills and occasionally going to the gym.
What is OpenAI? What is your mission?
OpenAI is a non-profit artificial intelligence research company. Day to day, we are working on research projects in unsupervised learning and reinforcement learning. Our mission and long-term goal is to advance artificial intelligence in the ways that will maximally benefit humanity as a whole.
What is reinforcement learning? How is it different from supervised and unsupervised learning?
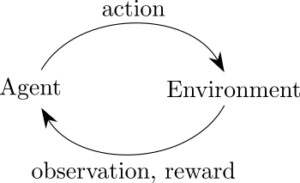
Reinforcement learning (RL) is the branch of machine learning that is concerned with making sequences of decisions. It assumes that there is an agent that is situated in an environment. At each step, the agent takes an action, and it receives an observation and reward from the environment. An RL algorithm seeks to maximize the agent’s total reward, given a previously unknown environment, through a learning process that usually involves lots of trial and error.
The reinforcement learning problem sketched above, involving a reward-maximizing agent, is extremely general, and RL algorithms have been applied in a variety of different fields. They have been applied in business management problems such as deciding how much inventory a store should hold or how it should set prices. They have also been applied to robotic control problems, and rapid development is currently occurring in this area. The following video shows Hopper: a two-dimensional one-legged robot trained to hop forward as fast as possible with OpenAI Gym.
While reinforcement learning is focused on making good decisions, supervised and unsupervised learning are mostly focused on making predictions. However, there are lots of connections between these areas, some of which are active topics of research. Besides its different focus, the sequential nature of reinforcement learning also sets it apart from most supervised learning problems. In reinforcement learning, the agent’s decisions affect what input data it receives, i.e., what situations it ends up in. That makes it harder to develop stable algorithms and necessitates exploration—the agent needs to actively seek out unknown territory where it might receive large rewards.
What is OpenAI Gym, and how will it help advance the development of AI?
OpenAI Gym is a toolkit for developing and comparing reinforcement learning algorithms. It includes a curated and diverse collection of environments, which currently include simulated robotics tasks, board games, algorithmic tasks such as addition of multi-digit numbers, and more. We expect this collection to grow over time, and we expect users to contribute their own environments. These environments all expose a common interface, making it possible to write generic algorithms that can be applied to many different environments.
OpenAI Gym also has a site where people can post their results on these environments and share their code. The goal is to make it easy for people to iterate on and improve RL algorithms, and get a sense for which algorithms really work.
Just to give you a sense of what the code looks like, here’s how you can create one of our environments (the classic cart-pole task, where the aim is to balance a vertical pole on a rolling cart), simulate some random actions, and then submit the results to the scoreboard. (In reality, you’ll only want to submit your results if you’ve implemented a learning algorithm.)
import gym
env = gym.make("CartPole-v0") # Creates the classic cart-pole environment
env.monitor.start("/tmp/gym-results", algorithm_id="random")
# ^^^ starts logging statistics and recording videos
for _ in xrange(1000):
action = env.action_space.sample() # random action
observation, reward, done, info = env.step(action)
env.monitor.close()
gym.upload("/tmp/gym-results", api_key="JMXoHnlRtm86Fif6FUw4Qop1DwDkYHy0")
# ^^^ upload stats to the website
This snippet does not include any learning or training—that would require much more code. Soon we are hoping to show clean implementations of various important algorithms on OpenAI Gym environments. If you’re interested, keep an eye on our website.
How are neural networks used in reinforcement learning?
To answer this, I’ll need to talk a little bit about what RL algorithms learn. Some reinforcement learning algorithms are focused on learning a policy, which is a function that takes in observations (e.g., camera images) and outputs actions (e.g., motor torques). Other algorithms are focused on learning value functions, which measure the goodness of states (i.e., the state of the world) and actions. Since we usually don’t have access to the full state of the world, we typically use one or more past observations instead. A Q-function (a type of value function) measures the goodness of a state-action pair 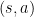

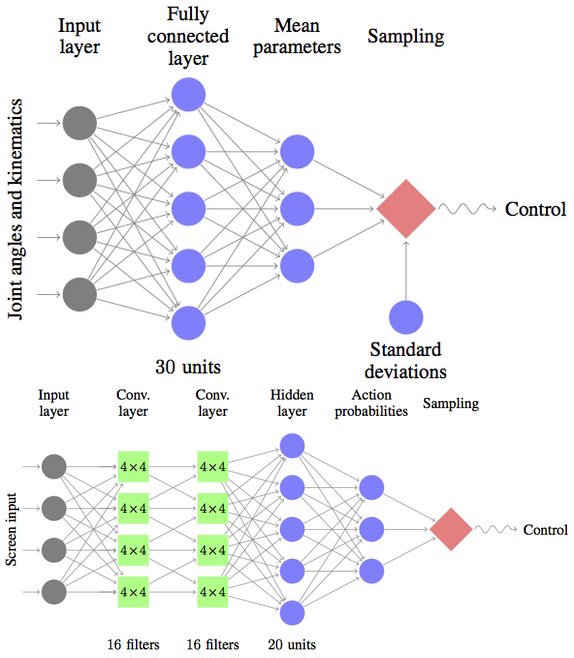
Policy-based algorithms and Q-function-based algorithms are very similar at their core, and we can use neural networks to represent the policies and Q-functions. For example, when playing Atari games, the input to these networks is an image of the screen, and there is a discrete set of actions, e.g. {NOOP, LEFT, RIGHT, FIRE}. As a Q-function for this task, you can use a convolutional neural network that takes the screen image as input and outputs a real number for each of the 4 actions, specifying the goodness of that action (Mnih et al, 2013). As a policy for this task, you can use a convolutional neural network with similar architecture, which instead outputs the probability of each action. (Guo et al., 2014, Schulman et al., 2015).
What makes OpenAI Gym unique? Are there other similar open source environments currently available?
There are various open-source collections of environments, including but not limited to RL-Glue, RLPy, and Arcade Learning Environment. We’ve drawn inspiration and code from these libraries. OpenAI Gym also integrates work done recently by researchers at UC Berkeley on benchmarking deep reinforcement learning algorithms. A paper describing this benchmark is available on the ArXiv and will be presented at ICML this year.
OpenAI Gym goes beyond these previous collections by including a greater diversity of tasks and a greater range of difficulty (including simulated robot tasks that have only become plausibly solvable in the last year or so). Furthermore, OpenAI Gym uniquely includes online scoreboards for making comparisons and sharing code.
Who will use OpenAI Gym? How will AI researchers benefit from RL-Gym?
We hope to make OpenAI Gym accessible to people with different amounts of background. Users with no background in RL can download the codebase and get started experimenting in minutes. They can visit the scoreboards for different environments and download the code linked to solutions. Then they can verify the solutions (an important and useful service!) and tinker with them.
AI researchers will be able to use the included environments for their RL research. Each environment is semantically versioned, making it possible to report results in papers and have them remain meaningful. Researchers will be able to compare their algorithms’ performance with others on the scoreboard, and find code for the leading algorithms.
Do you have plans to accelerate OpenAI Gym with NVIDIA GPUs? How will GPUs benefit your work?
GPUs are becoming indispensable for learning problems that involve large neural networks. We will be using GPUs for training networks on the larger-scale tasks, and we expect many of our users to do the same.
Also, our current environments include robotics simulations, and we expect to include more complicated and realistic 3D environments in the future. GPUs will enable high-quality rendering and physics simulation in these more complicated 3D environments.
Would more realistically rendered environments be useful to transfer learning to the real-world?
Yes, I believe that photorealistic rendering is good enough to allow robots to be trained in simulation, so that the learned policies will transfer to the real world. Lots of exciting possibilities lie ahead.
What’s next for OpenAI and OpenAI Gym?
We’ll soon be publishing results from some of our ongoing research projects in unsupervised learning and reinforcement learning. We’re excited to see what users do with OpenAI Gym, and plan to continue building it into a tool that’s great for the research community as well as newcomers to the field.
To learn more see the OpenAI Gym announcement blog post. For an introduction to Deep Learning, check out the Deep Learning in a Nutshell series.