Modern deep neural networks, such as those used in self-driving vehicles, require a mind boggling amount of computational power. Today a single computer, like NVIDIA DGX-1, can achieve computational performance on par with the world’s biggest supercomputers in the year 2010 (“Top 500”, 2010). Even though this technological advance is unprecedented, it is being dwarfed by the computational hunger of modern neural networks and the dataset sizes they require for training (Figure 1).

This is especially true with safety critical systems, like self-driving cars, where detection accuracy requirements are much higher than in the internet industry. These systems are expected to operate flawlessly irrespective of weather conditions, visibility, or road surface quality.
To achieve this level of performance, neural networks need to be trained on representative datasets that include examples of all possible driving, weather, and situational conditions. In practice this translates into Petabytes of training data. Moreover, the neural networks themselves need to be complex enough (have sufficient number of parameters) to learn from such vast datasets without forgetting past experience (Goodfellow et al., 2016). In this scenario, as you increase the dataset size by a factor of n, the computational requirements increase by a factor of n2, creating a complex engineering challenge. Training on a single GPU could take years—if not decades—to complete, depending on the network architecture. And the challenge extends beyond hardware, to networking, storage and algorithm considerations.
This post investigates the computational complexity associated with the problem of self-driving cars to help new AI teams (and their IT colleagues) to plan the resources required to support the research / engineering process.
How Much Data is Enough?
Every manufacturer has a significantly different approach to the problem of data collection, sampling, compression and storage. The exact details or data volumes they choose are not in the public domain. Some manufacturers do speak openly about their fleet sizes and instrumentation of the cars. With this knowledge, together with four conservative assumptions about the collection process, I can make rough estimates of data volumes. I use these to calculate computational requirements in the examples.
Self-Driving Fleet Size
Companies like Waymo, formerly the Google self-driving car project, report having fleets of tens to hundreds of cars collecting data every day. In December 2016, Waymo announced that it would extend its fleet by 100 cars (“Google’s Waymo adds 100 Chryslers” 2016) and, in May 2017, reported collecting three million miles of data (“Waymo – On the road” 2017). Other manufacturers are building similar fleet sizes. In June 2017, General Motors announced that it had manufactured 130 autonomous vehicles and expected the fleet to quickly grow to 180 (“GM completes production” 2017). In August 2016, Ford announced deployment of a fleet of 100 self-driving cars (“The self-driving Ford is coming.” 2016).
Given these examples, I’ll use a fleet size of 100 cars as a conservative estimate.
Assumption 1: Fleet size = 100 cars
It is important to point out that few people believe that this problem can be solved using data collected by the physical fleet alone. Many companies, such as Waymo, are investing heavily into simulation, and are building virtual data collection fleets orders of magnitude bigger than the numbers discussed above. At the point of writing, Waymo has collected in excess of one billion miles generated through computer simulation, suggesting that their virtual fleet consists of thousands of simulated vehicles.
Duration of Data Collection
Since the technology does not exist yet, it is impossible to give a precise estimate of how much data is needed to train a roadworthy algorithm. The following calculations are based on public information.
At the time of writing, Waymo has reported having:
- 3 milion miles of live test drives
- 1 billion miles of simulated test drives
- A disengagement rate of 0.2 per 1000 miles (on average a human had to intervene every 5000 miles)
This disengagement rate is clearly insufficient for a product, which suggests that 3 million miles for test drives is insufficient as well. I will use this figure as a conservative estimate of the initial dataset required.
Waymo has also reported that its new extended fleet allowed it to collect 1 million miles of data in 7 months; equivalently, 3 million miles in 21 months. Again, to make this number more conservative, I’ll significantly round it down to 12 months and down again to account for 8 hours of driving every day per car and only 260 days a year (length of a working year).
Assumption 2: Duration of data collection = 1 working year = 2080 hours / car
This means that a fleet of 100 cars instrumented with 5 cameras each will generate in excess of one million hours of video recording in a year. This data needs to be captured, transported from the car to the data center, stored, processed and used for training. Importantly, since supervised learning algorithms are used, the data also needs to be annotated by humans. Marking every pedestrian, car, lane, and other details can become a significant bottleneck if the data annotation team is not adequately sized.
Volume of Data Generated by a Single Car
A typical vehicle used for data collection in the self driving car use case is equipped with multiple sensors (“NVIDIA Automotive” 2017; Liu et al., 2017). This includes technologies such as radar, cameras, lidar, ultrasonic sensors, and a wide range of vehicle sensors distributed over the vehicle’s Controller Area Network, Flexray, automotive ethernet and many other networks.
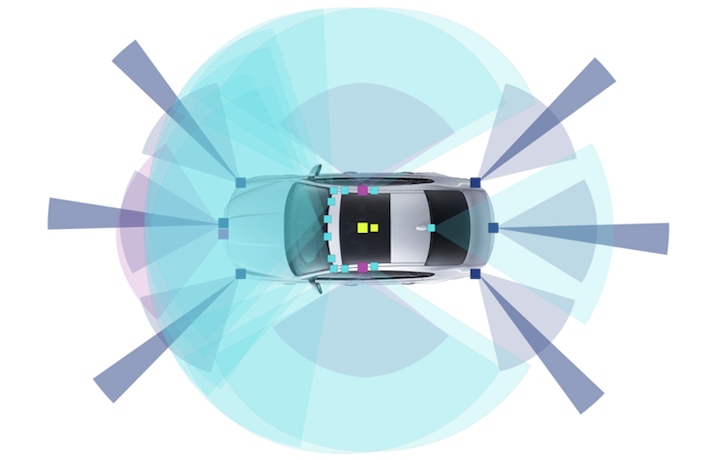
Typical test cars are equipped with multiple cameras, radars and other sensors to provide the computer system with added visibility and redundancy, which protects the car against adverse weather conditions or failure of individual components (Figure 2).

The exact instrumentation details of specific manufacturers or suppliers are not in the public domain, but some Tier 1 suppliers do provide insights into the order of magnitude of the problem. A paper published by Dell EMC and Altran (Radtke, 2017) reveals that just a single forward facing radar operating at 2800 MBits / s generates more than 1.26 TB of data per hour, and a typical data collection car generates in excess of 30TB a day. Similarly, a two megapixel camera (24 bits per pixel) operating at 30 frames per second generates 1440 Mbits of data every second, so a five camera setup can generate in excess of 24 TB per day.
Given that there is little publicly available information about the exact vehicle instrumentation of different self driving vehicles, I must be very conservative with the data volume assumptions. For the sake of simplicity, and in order to ensure the final computational requirements are not exaggerated, I will consider only the data generated by the surround cameras. Moreover, I will assume that the vehicle is equipped with only five cameras, even though in many cases there will be more. This setup typically uses two-megapixel cameras operating at 30 frames per second.
This oversimplified setup generates in excess of 3TB of raw video data every hour, which I will further reduce to just 1TB per hour (to accommodate any variation in the hardware or the sampling rate).
Assumption 3: Volume of data generated by a single car = 1 TB+ / h
Data Preprocessing
The final assumption involves data preprocessing, which is typically carried out on the raw video stream. There are two steps that can be taken to safely reduce the amount of data, without drastically affecting the performance of the neural networks.
- Data sampling: Since individual video frames are highly correlated, at the initial stages of research one could consider resampling the input dataset to help control the computational complexity of the problem. While it might not be done in practice, resampling the data from 30 frames per second to one frame per second reduces the dataset size used for compute estimation by a factor of 30.
- Compression: Similarly, compression is rarely lossless, so it might not be possible to use in practice. In order to reduce the data volumes used for calculation I will assume a very aggressive 70x compression, which in practice is not usable because of the significant degradation of image quality. Once again, I do this just to make sure my final data volume estimate is conservative.
If I now multiply those two figures together, I get data a reduction factor of approximately 0.0005.
Assumption 4: Data reduction due to preprocessing = ~0.0005 of raw data
Total data volume after preprocessing
If I now combine the four assumptions, all of which err on the side of conservative estimates, a single car will produce 1TB+ of data every hour, and 100 vehicles operating for 8h/day * 260 working days / year will generate 204.8PB of data.
Total raw data volume = 204 PB
This data will be heavily processed and probably downsampled to make the training feasible, as discussed in the previous section. This will bring the data volume to a fairly modest 104 TB.
Total data volume after preprocessing = 104 TB
How Long Will Training Really Take?
I’ve calculated that the total data volume after preprocessing is 100TB. So what does this mean for the training process? Since the neural network architectures of automotive detection networks are not in the public domain, I will use a number of state of the art image classification networks for further calculation. These are conceptually very similar to the solutions used for tasks such as pedestrian detection, object classification, path planning, etc.
Running AlexNet (Krizhevsky et al., 2012)—one of the least computationally heavy image classification models —together with a substantially smaller ImageNet dataset (Russakovsky et al., 2014) achieves a throughput of ~150MB/s on a single Pascal GPU. For more complex networks like ResNet 50 (He et al., 2016) this number is closer to ~28 MB/s. For a state of the art network like Inception V3 (Szegedy et al., 2016) it is approximately 19MB/s.
If I now assume that automotive networks will converge within a similar number of epochs as networks used with ImageNet data (let’s use 50 epochs for ease of computation) this means that a single GPU will take:
- 50 epochs * 104 TB of data / 19 MB/s = 9.1 years to train an Inception-v3-like network once.
- 6.2 years for a ResNet-50-like network.
- 1.2 years for an AlexNet-like network.
A state of the art Deep Learning system like NVIDIA DGX-1 is designed to scale nearly linearly, to provide up to eight times the computational capability. However, a single system does not solve the problem. Even with 8 Tesla P100 (Pascal) GPUs, the training time comes to
- 1.13 years for Imagenet V3 or similar;
- 0.77 years for ResNer 50 or similar;
- 0.14years for AlexNet or similar.
The introduction of the new Volta GPU architecture addresses some of those challenges further (at the moment of writing, training of ResNet 50 was 2.5 times faster on Tesla V100) but does not change the order of magnitude of the problem. Especially given that, in practice, much larger networks might be required to accommodate information from the dataset (Goodfellow et al., 2016).
How Much Compute Does the Team Need for Training?
The previous section illustrated how a single system cannot address the vast amount of data and computational capability required for autonomous driving. With the emergence of even denser computing systems, such as DGX-1 with Volta GPUs, it is now possible to build a clustered solution delivering this extraordinary computational resource.
The numerical estimates presented above make it clear that this is a necessity. No one can expect even the largest and most talented team to succeed if they need to wait for results of their experimentation for two years. Even 100 days is too long. In order for the team to work effectively, this iteration time needs to drop to couple of days, if not hours. For the purpose of further calculations I will assume seven days as a target. Moreover, if the team has more than one person working at the same time, everyone (or at least a proportion of the team; I assume 20%) should be able get the results of their experiments in a reasonable time.
To understand just how much compute power is required, let’s do further calculations. Assuming a fairly modest team of 30 people, out of which only six will submit jobs at any given time, a seven-day training time will require:
- 356 DGX-1 Pascal systems for Inception V3 or similar (approximately 10 systems per team member);
- 241 systems for ResNet 50 or similar (8 systems per team member);
- 45 systems for AlexNet or similar (2 systems per team member).
Using the latest Volta benchmarks that show that DGX-1 with Tesla V100 (Volta) GPUs is 2.5 times faster, those numbers become:
- 142 DGX-1 Volta systems for Inception V3 or similar (4-5 systems per team member);
- 97 systems for ResNet 50 or similar (3 systems per team member);
- 18 systems for AlexNet or similar (1 system per team member).
Table 1 summarizes my estimates and assumptions, as well as showing a less conservative estimate.
| Assumptions | Very Conservative estimate | Less Conservative estimate |
|---|---|---|
| Fleet size | 100 | 125 |
| Duration of data collection | 1 working year / 8h | 1.25 working year / 10h |
| Volume of data generated by a single car | 1TB / h | 1.5TB / h |
| Data reduction due to preprocessing | 0.0005 | 0.0008 |
| Research team size | 30 | 40 |
| Proportion of the team submitting jobs | 20% | 30% |
| Target training time | 7 days | 6 days |
| Number of epochs required for convergence | 50 | 50 |
| Calculations | ||
| Total raw data volume | 203.1 PB | 595.1 PB |
| Total data volume after preprocessing | 104 TB | 487.5 TB |
| Training time on a single DGX-1 Volta system (8 GPUs) | 166 days (Inception V3) 113 days (ResNet 50)21 days (AlexNet) |
778 days (Inception V3) 528 days (ResNet 50) 194 days (AlexNet) |
| Number of machines (DGX-1 with Volta GPUs) required to achieve target training time for the team | 142 (Inception V3) 97 (ResNet 50) 18 (AlexNet) |
1556 (Inception V3) 1056 (ResNet 50) 197 (AlexNet) |
The Challenges of Linear Scaling
All of the compute estimates presented above assumed that the cluster can achieve perfect linear scaling. That means that, as you increase the number of GPUs, the training time decreases proportionally. Throughout this article I am referring to data parallelism as described by Dean et al. (2012) as a mechanism to achieve this scaling. So if you double the number of GPUs, the training time reduces to 50%. This is a difficult feat.
One cannot just simply put multiple gaming graphics cards into a cluster and expect to see a perfectly straight line when plotting training time versus number of GPUs. On the contrary, in case of majority of automotive image segmentation networks, if you connect a number of GPUs over the PCI-e bus, you will notice that as you increase the number of cards above 2-3 you see limited increase in performance (this varies depending on the computational complexity of the network and number of parameters).
This section of the post briefly addresses the reasons for this behavior, and lays out key design considerations for infrastructure, while also pointing to the appropriate literature for further information. For even more detailed information see the NVIDIA DGX-1 System Architecture white paper (“NVIDIA DGX-1 System Architecture”, 2017).
Networking
One of the most fundamental reasons for sub-linear scaling (apart from code quality issues) is communication overhead.
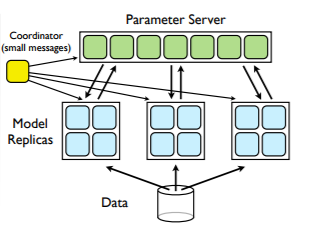
n order to train a neural network on multiple GPUs using data parallelism (Dean et al., 2012), every GPU gets the same copy of a model and a small subset of the data (Figure 3). Once the neural network forward pass is completed, a computation and exchange of data starts. At this stage, the GPUs need to exchange exceptionally large amounts of data within a very limited amount of time.
If the exchange takes more time than it takes for the GPU to do a backward pass through the network, then all of the machines need to wait idle until that communication completes.
It turns out that in the overwhelming majority of cases, the data rate required in order to avoid a communications bottleneck exceeds the capability of the PCIe network. To address this problem, NVIDIA has developed a dedicated GPU interconnect called NVLink, which in its second release provides over 300GB/s bidirectional bandwidth per Tesla V100 GPU.
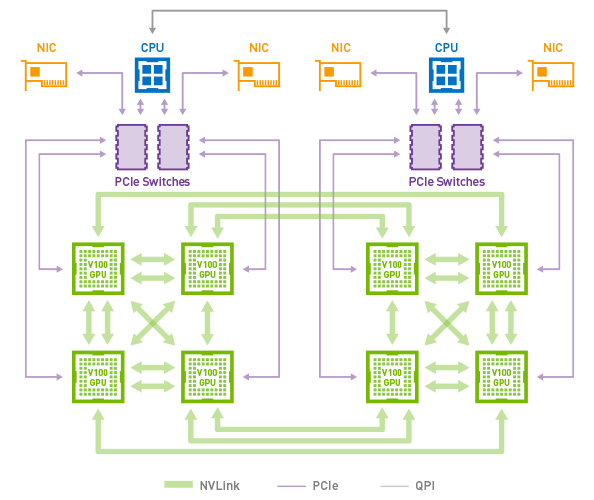
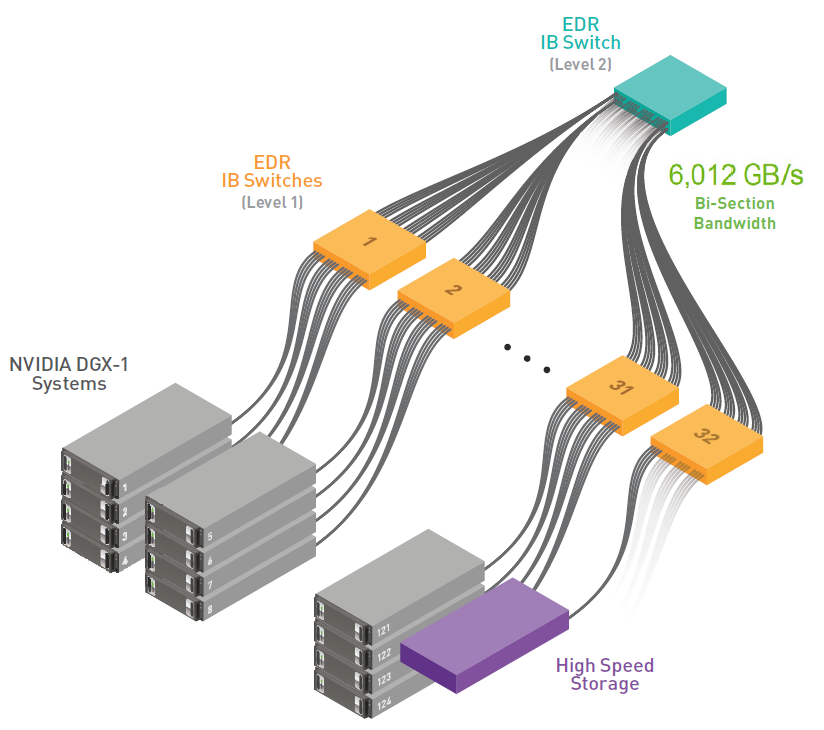
NVLINK addresses the challenges of communication within a single multi-GPU system, allowing applications to scale up to 8 GPUs on DGX-1 (Figure 4) much better than a similar system with only PCI-e interconnect. In order to scale to multiple machines, it is critical to think about multi node communication and the role of Infiniband in your network topology. For the highest multiserver training performance consider a full fat-tree network design to maximise the total available bandwidth, as Figure 5 shows (Capps, 2017).
NVLink and Infiniband are communication mediums, but do not by themselves provide an out-of-the-box mechanism for distributed deep learning. To address this issue, the NVIDIA Collective Communications Library (NCCL) hides the complexity of GPU communication within the cluster and is integrated (to varying extent) with all popular deep learning frameworks.
Algorithms and Software
NCCL is not the only piece of logic that has to be incorporated into your neural network implementation. Even though virtually all of the deep learning frameworks allow for parallelisation of the workload, it is achieved with varying engineering effort. Moreover, different deep learning frameworks offer different implementation quality and evolve at varying rates, making it easier or more complex to keep up with the changes and address bugs. Finally, none of the deep learning frameworks comes out of the box with any level of support.
Engineering resources are required to build and maintain a set of software tools, but these resources are very frequently neglected at the start of the project and then catch people by surprise. Unless you sell this process to a third party, or employ a fair number of software engineers, it will be up to your research staff to build and maintain this toolset. This is neither their core expertise, nor should be their core activity.
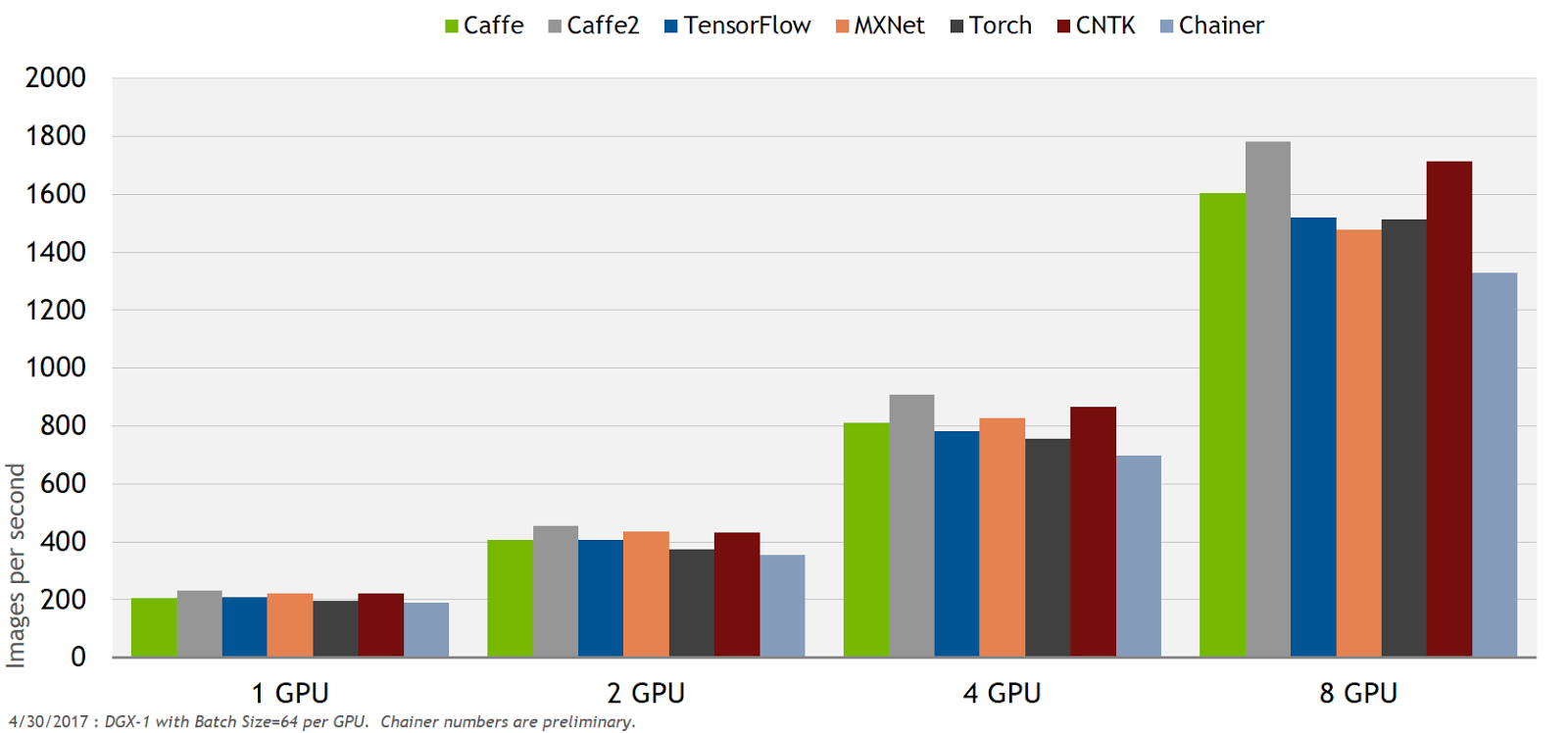
In order to accelerate AI research and allow organisations to focus on self-driving vehicle algorithm development (in contrast to deep learning framework maintenance and optimisation), NVIDIA provides optimized containers for all of the key deep learning frameworks on a monthly release cycle. These containers not only remove the need to manage the complexity of the ever-changing deep learning landscape but also provides exceptional performance. NVIDIA’s optimizations and testing save your team considerable engineering effort (Figure 6).
Storage
Another frequently overlooked element of the solution is storage. In principle, the challenge is simple: you must provide enough data to your GPUs to keep them busy. Any delay in the data loading pipeline will unavoidably lead to idle GPUs, and the entire process will be heavily delayed. The bandwidth of data delivery is nontrivial. It is not uncommon for a single node to process data at more than 3GB/s, especially when processing high-resolution images.
For smaller datasets, the problem is simpler. Since the neural network accesses the same data at each training epoch, the data can be cached locally on high performance SSDs (or even RAM for smaller datasets) and delivered at the speed of the local SSDs to the GPUs (note however that the first epoch will incur the cost of the first access to the network file server). Such solutions are already widely deployed on Deep Learning systems like DGX-1.
In the automotive context, the problem is more complex. As I have estimated, the best case scenario is dealing with 100TB of data. The local cache used in DGX-1 is useful if the data can be transferred to it once, and then systematically reused across multiple epochs. Automotive datasets are far beyond the capability of a training machine’s local storage, therefore the extent to which the local cache can be used is limited. In this case, it is clear that a higher performance storage backend is necessary. What NVIDIA is seeing is more and more deployments of either flash (Robinson, 2017) storage or flash-accelerated storage, frequently with HPC file systems.
CPU and Memory
The CPU plays a vital role in orchestrating the training process as well as data loading, logging, snapshotting and augmentation processes. If the CPUs are unable to keep up with the data hunger of the GPUs, the GPUs will simply sit idle. It is important to note that even for simpler problems like ImageNet, eight Pascal GPUs can easily saturate an entire server-grade CPU socket (Goyal et al., 2017). This became such a significant problem for groups such as Samsung Research that they have started the process of migrating data augmentation pipelines to the GPU, even though it reduces available GPU resources for the neural network itself (Gale et al., 2017).
When benchmarking different CPU configurations, we have observed a nontrivial impact on the end-to-end training performance. The same balance needs to be maintained for RAM (2x to 3x of the GPU memory attached).
Compute for Other Stages of the Engineering Workflow
An AI engineering workflow is much broader than just the large-scale training of deep learning models. The team needs to be provided with tools to allow them to effectively prototype, test, optimise and deploy their candidate models (Figure 8). All of those steps require significant computational resources. There is little sense to establishing a large research team if they are not supported by the right tools.
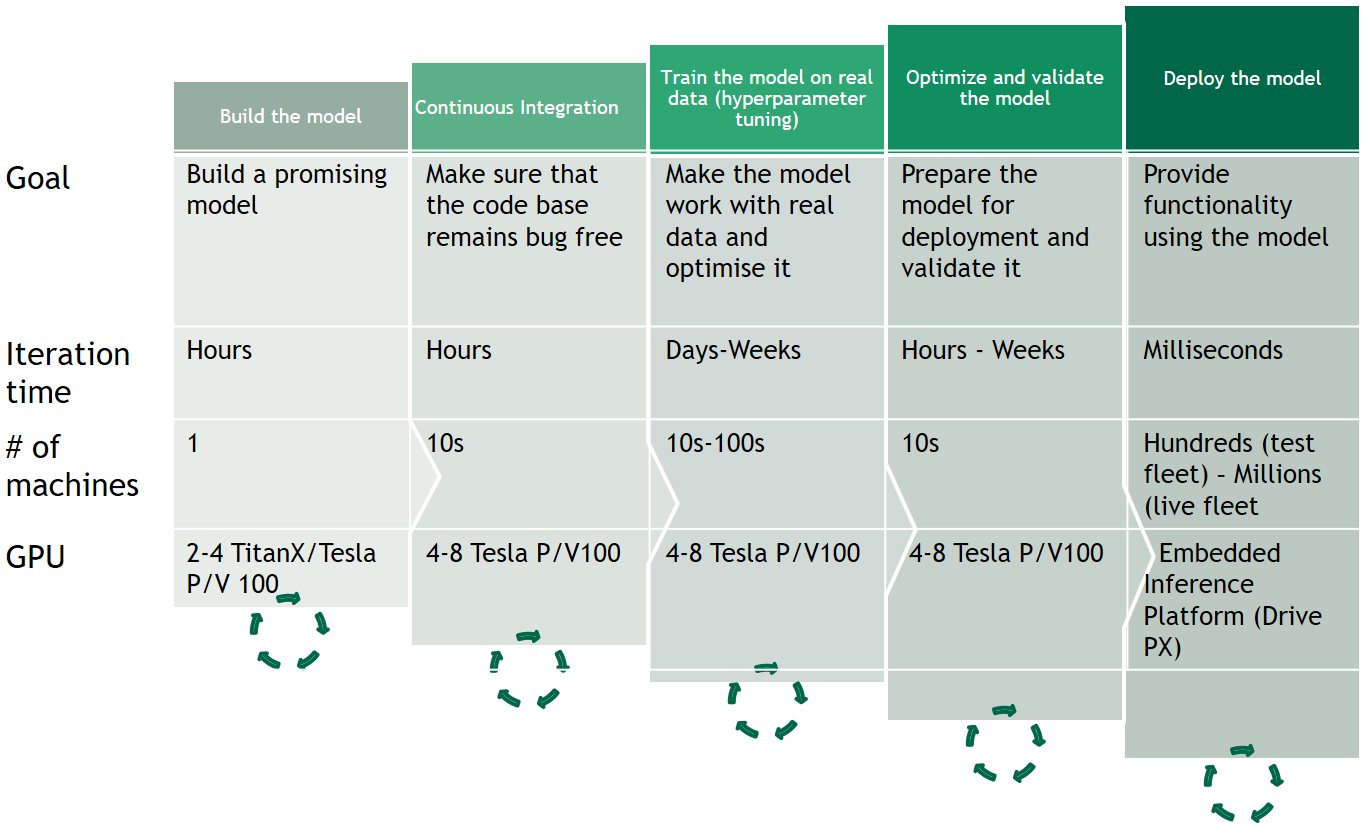
But the challenge is wider than that. Data engineering and operations, data transport and storage, data annotation (a large task given three million miles of driving data), prototyping, testing and optimisation infrastructure need to grow proportionally with the team.
Plan for Scale
The computational requirements of deep neural networks used to enable self-driving vehicles are enormous. At every stage of the calculations in this article, I have significantly rounded down the data volumes (sometimes by an order of magnitude or more), and still the resulting calculations clearly show that self-driving car research cannot be carried out successfully on a small number of GPUs. Even with a device as powerful as DGX-1 with Tesla V100 GPUs, a single training iteration would take months when dealing with a 100TB dataset. There is no way of escaping large-scale distributed training. Building this infrastructure, as well as the software to support it, is non-trivial, but not beyond reach.
For the first time in human history, we have enough computational power for the complexity of autonomous vehicle training. Obviously, the computational resource is not everything you need. You need to establish a research and data engineering teams and a systems team to manage your operations. You need to create and deploy a fleet of vehicles to collect the data and validate the results, and then integrate the results of your work with the vehicle. You have many logistical and financial challenges, but finding the solution to this very important problem is just a matter of engineering/research effort (so a function of budget and time).
For help evaluating the complexity of your problem, discussing the challenges of distributed training and large-scale model validation, or support in organizing your own artificial intelligence team, please contact us.
Please review the NVIDIA DGX-1 System Architecture whitepaper for more details on the key requirements for the AI training workflow.
Finally, if you are interested in experimenting with the calculations I used in this post, you can copy this spreadsheet, change the assumptions used to reflect your own use case, and use it estimate your AI team’s computational requirements.
References
Capps, L., (2017). The Making of DGX SATURN V: Breaking the Barriers to AI Scale. GPU Technology Conference 2017. Retrieved from http://on-demand.gputechconf.com/gtc/2017/presentation/s7750-louis-capps-making-of-dgx-saturnv.pdf
Chintala, S. (2017). Deep Learning Systems at Scale. GPU Technology Conference. Retrieved from http://on-demand.gputechconf.com/gtc/2016/presentation/s6227-soumith-chintala-deep-learning-at-scale.pdf
Dean, J., Corrado, G., Monga, R., Chen, K., Devin, M., Mao, M., … & Ng, A. Y. (2012). Large scale distributed deep networks. In Advances in neural information processing systems (pp. 1223-1231).
Gale, T., Eliuk, S., Upright, C. (2017). High-Performance Data Loading and Augmentation for Deep Neural Network Training, GPU Technology Conference 2017, Retrieved from http://on-demand.gputechconf.com/gtc/2017/presentation/s7569-trevor-gale-high-performance-data-loading-and-augmentation-for-deep-neural-network-training.pdf
GM completes production of 130 Bolt self-driving cars. (2017, June 13). Retrieved from http://in.reuters.com/article/gm-autonomous/gm-completes-production-of-130-bolt-self-driving-cars-idINKBN1941P2
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press.
Google’s Waymo adds 100 Chryslers to self-driving fleet. (2016, December 19). Retrieved from http://www.dailymail.co.uk/wires/afp/article-4048484/Googles-Waymo-adds-100-Chryslers-self-driving-fleet.html
Goyal, P., Dollár, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., … & He, K. (2017). Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv preprint arXiv:1706.02677.
He, K., Zhang, X., Ren, S., & Sun, J. (2016, October). Identity mappings in deep residual networks. In European Conference on Computer Vision (pp. 630-645). Springer International Publishing.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105).
Liu, S., Tang, J., Zhang, Z., & Gaudiot, J. L. (2017). CAAD: Computer Architecture for Autonomous Driving. arXiv preprint arXiv:1702.01894.
NVIDIA Automotive. (2017, October 1). Retrieved from http://www.nvidia.com/object/drive-automotive-technology.html
NVIDIA DGX-1 System Architecture – The Fastest Integrated System for Deep Learning. (2017). Retrieved from http://www.nvidia.com/object/dgx-1-system-architecture-whitepaper.html
Radtke, S. (2017, February 6). Addressing the Data growth challenges in ADAS /AD for simulation and Development. Retrieved from: http://stefanradtke.blogspot.de/2017/02/how-isilon-addresses-multi-petabyte.html
Robinson, J., Real World AI: Deep Learning Pipeline Powered by FlashBlade. (2017, September 29). Retrieved from https://www.purestorage.com/resources/type-a/real-world-ai.html
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., … & Berg, A. C. (2015). Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3), 211-252.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2818-2826).
The self-driving Ford is coming. (2016, August 16). Retrieved from http://uk.businessinsider.com/fords-self-driving-cars-2021-2016-8?r=US&IR=T
Top 500, The List. (2010, June). Retrieved from https://www.top500.org/lists/2010/06








