By Kenneth A. Lloyd (GTC 2012 Guest Blogger)
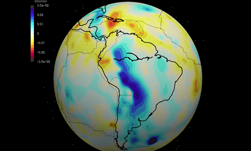
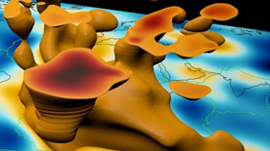
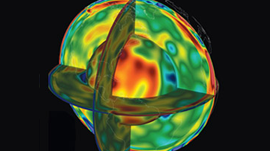
Geophysical wave propagation is really interesting because you can’t actually see the phenomenon, and you can only feel a small part of it (that is, unless you are unlucky and find yourself in the path of an earthquake). The only way we have of understanding the causes and effects of seismic activity is to model it, compare it with a lot of data, and visualize the mathematical model in a computer.
The problem, of course, is that the models, the data and the translation into some type of visualization are “computationally expensive”, meaning that it requires substantial computing power to crunch the numbers. Since seismic activity is not a planned event, we simply can’t wait for hours and weeks for the simulation to run to predict the far-reaching and potentially disastrous global effects.
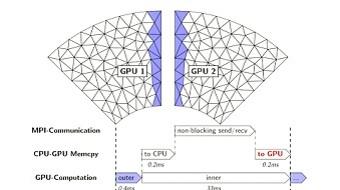
In his GTC session on Thursday, May 17, Max Reitmann of the Institute for Computational Science in Lugano, Switzerland, showed us how seismic simulations are being done more quickly and accurately using CUDA and massively parallel processing. Reitmann detailed a Fortran, C/CUDA and MPI approach to a finite element implementation of wave propagation in geophysics. Specifically, the seismic propagation of earthquake perturbation. Reitmann employed an MPP CUDA graph coloring refinement of an existing, open source, seismic finite element analysis application—reducing the computational time from 75 hours to one hour.
There are two available approaches, depending upon the phenomena to be modeled: a seismic approach for earthquakes (which are non-experimental) and a tomographic approach (small perturbation models). The model and simulation yields a coarse-grained understanding of either global or local seismic phenomena in an economically reasonable time.
You can see Max’s slides here.
 About our Guest Blogger:
About our Guest Blogger:
Kenneth Lloyd is the Director of System Sciences at Watt Systems and a co-organizer of the New Mexico GPU Meetup Group.