Visual aesthetics are very personal, often subconscious, and hard to express. In a world with an overload of photographic content, a lot of time and effort is spent manually curating photographs, and it’s often hard to separate the good images from the visual noise. The question we put forward at EyeEm is: can a machine learn personalized aesthetics embodied in a set of chosen photos, and recreate them in a different set?
The incapacity to name is a good symptom of disturbance.
― Roland Barthes, Camera Lucida: Reflections on Photography

Does this photograph draw your attention? If so, what about it draws you in? Is it the expression of the mother? Is it the mood and visual path created by the pose, light, and setting of the scene; by the pure visual aesthetics? Does it recall a similar situation or sentiment? This photo was taken by Pantea Naghavi Anaraki, winner of The Photojournalist category at The 2016 EyeEm Awards. It depicts a mother in Tehran, Iran who had to sell her possessions to pay for cancer treatment. What is undeniable is that this photograph communicates directly to its admirers, creating both a visceral and intellectual experience that is often very hard to describe.
Your tastes are constantly evolving. For example, a photograph that appealed to you years ago may suddenly lose its magic, or, conversely, you may grow fond of another one. This raises an important question: is appreciation of a photo a natural function of the visual system, or is it nurtured and shaped over time by life experiences? It’s probably both, but often it’s difficult to pinpoint the exact source of our emotional reactions.
Capturing Individual Tastes
We usually say that one must first understand simpler things. But what if feelings and viewpoints are the simpler things?
— Marvin Minsky
Appreciation of photography is a strangely bipolar phenomenon. Beauty and impact in photography are part cultural “common sense”, and part expression of unique identity and personality.
At EyeEm, for the past few years we have been working on identifying the core aesthetics of what our audience of passionate photographers deems appealing, and transferring those aesthetics into a deep learning model, as explained in detail in our previous blog post on Parallel Forall. In this post we refer to our model as the base model.
A critical component of our work is curation of a strong training set. Our dataset is curated by expert photographers and photo editors, who try to span as much variety and subtlety as possible (See Fig.2). Curation of this dataset is an ongoing process; we constantly add photos and review the existing photos in our dataset.

The base model, though effective in modeling the general notion of aesthetics, was not designed to capture individual nuances and preferences of individuals or of a collective such as a brand or an organization. For example, at EyeEm we work with various brands to provide photographs that fit the visual language of their narrative. Figures 3 and 4 show two examples of manually curated sets selected to fit the styles of two different organizations: Boston Consulting Group (BCG ) and KAYAK.


Each of these sets has strong, distinct aesthetic traits that convey the brand’s identity and target it to a distinct audience with a specific function in mind.
The output of the last neural network layer of the base model is a ranker that learns to assign higher scores to more aesthetically pleasing photographs compared to less aesthetically pleasing photographs. The role of the preceding layers is to provide an effective representation that can maximize the success of the ranker. Typically in a deep convolutional neural network, the bottom layers learn to represent low-level properties like edges and contrast whereas the later layers learn to represent complex combinations of these low-level representations. The output values from the penultimate layer of the base model (henceforth called features) can serve as effective representations, summarizing different properties pertaining to visual aesthetics.
t-SNE is a popular tool used by machine learning researchers and practitioners to visualize high dimensional feature spaces. t-SNE embeds high-dimensional points in two or three dimensions, and explicitly tries to preserve in the embedding the similarity of points in the original high-dimensional space. In other words, two features that appear nearby in a 2D visualization are usually also close together in the original feature space.
The left-hand side of Figure 5 shows a plot of base model features in 2D t-SNE space. The plot includes photographs from three different datasets: the positive training set used to train our base model, and two independent sets of photographs curated by EyeEm’s photo editors while working with BCG and KAYAK. The middle and rightmost figures plot the photographs corresponding to features from BCG and KAYAK samples, respectively.
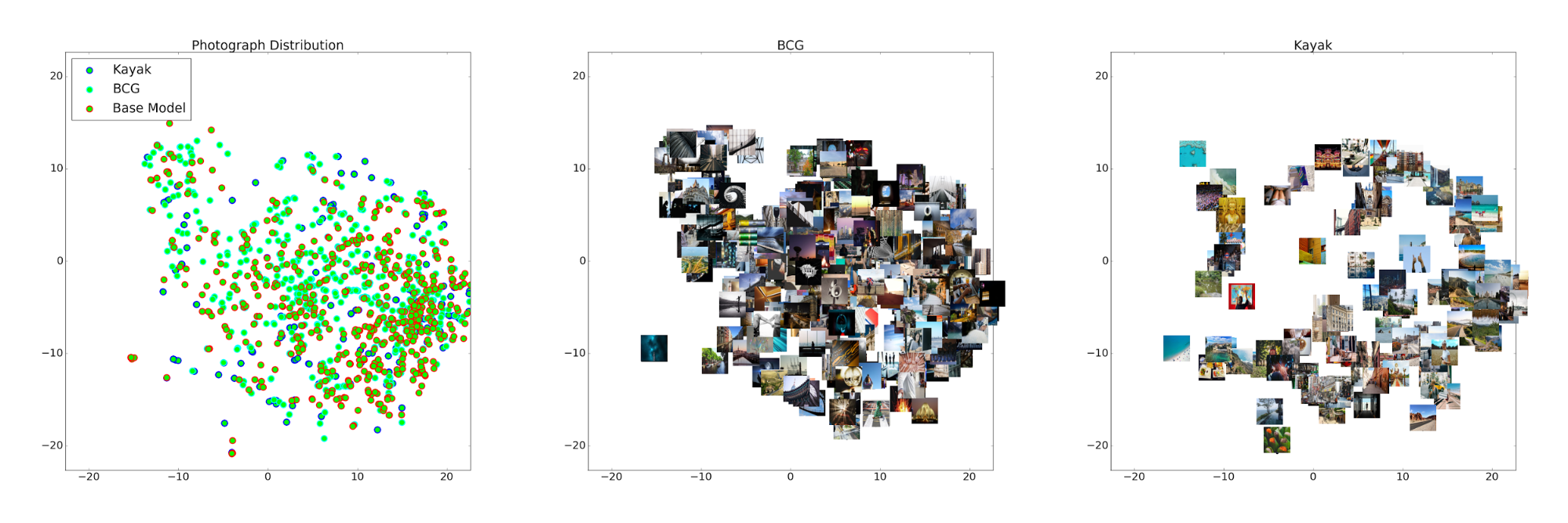
The plots make it clear that the distributions of feature representations of these three datasets vary considerably. However, courtesy of the large volume and highly distinct nature of our training data, the base model features span most of the representation space, with a sufficient number of samples near both the KAYAK and BCG models.
To capture personality, we need to account for this shift in distribution specific to a user’s choices versus the original training set. We can leverage the feature representation of the base model, build on top of it to accentuate the subtleties and variations found in the user’s input distribution, and attenuate the characteristics missing from it.
In practice, we achieve this by training a new ranker that uses the base model features as input, and learns to prioritize the photographs which adhere to the aesthetic qualities of the user’s training set. At the same time, the ranker should not adversely affect the generalization property of the previously trained model. In other words, a low-aesthetic photograph should be rated low unless explicitly overruled by candidate photographs in the user’s training set.
We chose a three-layer multilayer perceptron (MLP) network as a good ranker, since it is able to capture the inherent non-linear shift in distribution between the user’s choices and the original training set. Notably, an MLP can be trained rapidly by leveraging GPU computation to obtain near-real-time results. This is important because it enables us to build interactive interface, as we’ll explain. We typically precompute a set of negative features (about 40,000 negative samples) and extract the positive features from the user-provided input.
The three contour plots in Figure 6 represent the ranking scores of three different models: the base model, the personalized model trained with the BCG photographs, and the personalized model trained with the KAYAK photographs. The darker green a region, the higher rank the model assigns for photographs whose features fall within that particular region. Similarly, the model assigns low ranks for photographs whose features fall in the purple regions. Notice that the MLPs morphed the decision contours (non-linearly) to best fit the distribution of the respective training set.
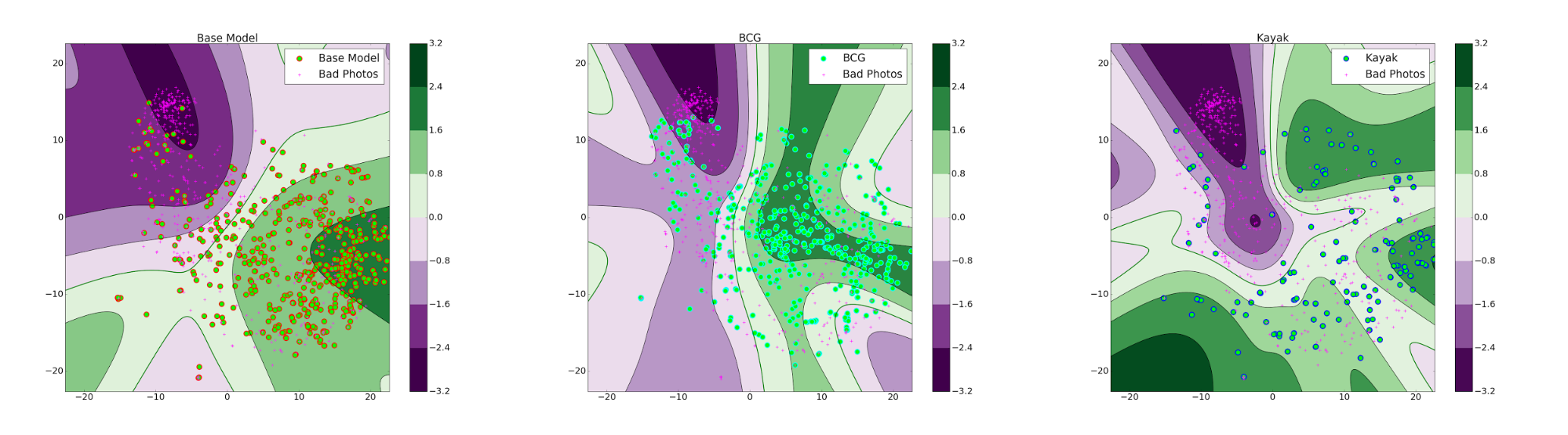
One natural question that arises is how to specify the training set for a personalized model. The training sample should be representative of aesthetics a curator wants to capture. That is, we need to be able to collect enough samples to model the subtleties the curator has in mind, and the training sample set should have a sufficient number of samples for the ranker to converge effectively. In our experience so far, MLPs converge with as few as 10 to 20 samples, but identifying a representative sample is a harder task.
It can be nearly impossible to translate thoughts about photographs and aesthetics into language. “I know it when I see it” is a classical sentiment among photographers and photo editors. Our base model coupled with MLPs generalizes well with a few samples, and can be trained in near real time using GPUs. These capabilities enable EyeEm Vision to help curators interactively specify representative photographs that she or he deems appropriate for a particular aesthetic, and photographs that are contrary to the aesthetic. To enable an efficient, interactively guided data collection, in every update EyeEm Vision picks candidate photographs that are visually similar to the choices the curator has made so far. The video below shows one of our curators interacting with this tool (the video shows interaction at 4x actual speed).
The ability to rapidly train models is crucial to providing this interface. It allows the curator to augment the model with additional images if he or she finds the model deficient in a particular facet, and correct any unwanted biases the model might have learned. We train our models using the Theano framework, leveraging CUDA 8.0 and the cuDNN 5.0 library. On average, we can train new models in three to four seconds, and our MLP converges in about 100 iterations. Scoring a new photograph using an NVIDIA Titan Z GPU takes about 3.8 microseconds (in other words, we can score a library of 100,000 images in half a second). Similar tasks using only CPU computation are approximately forty times slower.
GPU computation also aids in research and development work at EyeEm, specifically in the ongoing improvement of our base model algorithms. Base model training on a single K40 GPU takes a day or two to converge. We are constantly iterating on the architecture of our base model network, our choice of loss functions, and the way we sample our training data. GPUs allow our researchers to validate our models quantitatively and curators to evaluate the models qualitatively on an almost daily basis.
Sculpting with Data
It is the sculptor’s power, so often alluded to, of finding the perfect form and features of a goddess, in the shapeless block of marble; and his ability to chip off all extraneous matter.
— The Methodist Quarterly Review, 1858
Everyone strives to find subject matter and ideas that appeal to their desired audience. The motivation for this work is to enable the creative community to “sculpt with data”. A well-curated dataset captures the form and features, and the algorithms are the chisels and hammers that aid in carving out the fine details. The personalized component of our algorithm allows photographers to gain access to the necessary tools to discover, define and share his or her artistic identity, or even taste, with a larger audience.

The Week on EyeEm (TWOE) is an example of how we’ve used personalized aesthetics. Each Sunday, our curatorial and content teams publish a list of 20 photographs they liked this week , out of the tens of thousands uploaded in the last seven days. We get thousands of views on these photos, which in turn generate thousands of likes and follows. The author of this list rotates on a weekly basis to represent a different aesthetic for each TWOE set of photographs (see Figure 7 for curation examples by four of our curators).
With more photos being uploaded to our platform than ever before, curating TWOE might soon become an impossible task for one person—especially if we aim to be fair in giving everyone the chance for maximum exposure. So we tried an automatic curation exercise. Gathering data from each curator’s last six curations of TWOE, we trained EyeEm Vision on the curator’s preferences and asked it to curate a new set of photographs. The panel in Figure 8 shows the top four results from the automatic curation for the taste of four of our curators. It is interesting to note the distinctiveness that the four curation styles produce.

Each of our curators has a distinct style. For example, Jonny (Figure 7 shows his selection and Figure 8 shows the automatic curation) has a strong affinity for photographs that adhere to a cinematic style with emphasis on expressing a strong narrative, while Brada prefers photographs that convey a mood of intimacy and emotional connection expressed using close-ups of people or objects. An interesting exercise we often use is to cross check automatic curation based on a model trained on a peer’s previous collection. This allows the lead curator of the week to add a different perspective and variety to the final list they publish in the blog.
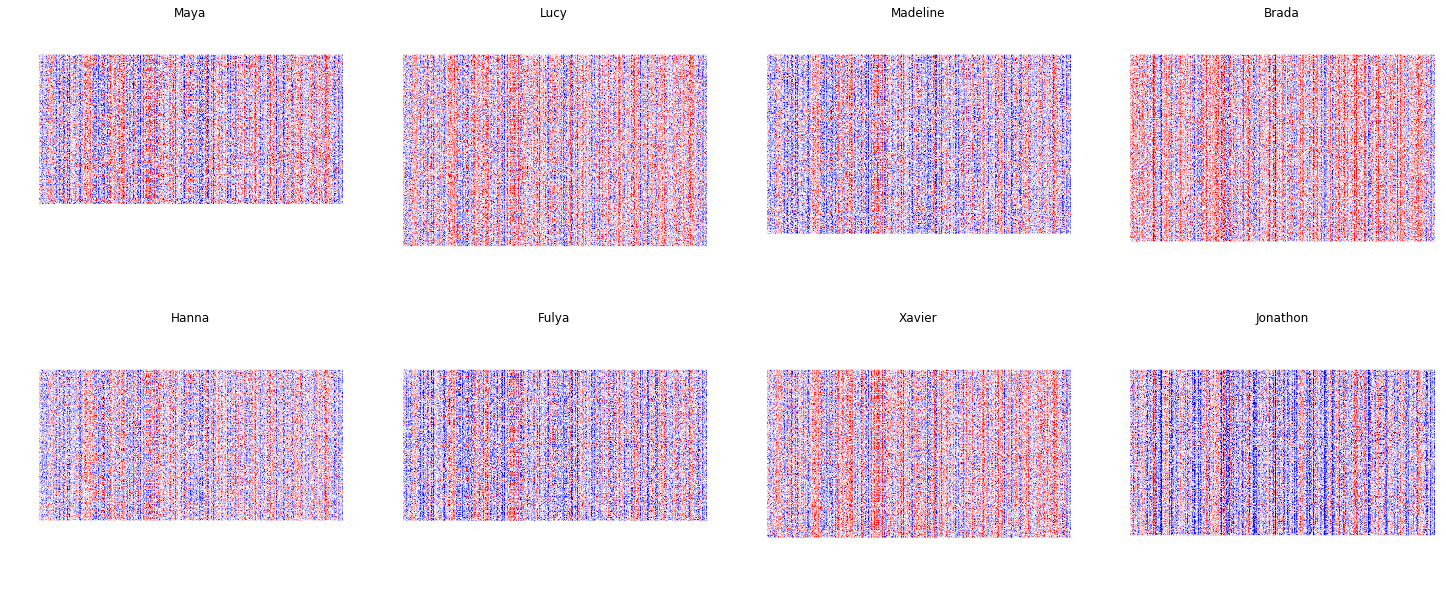
We are able to translate, to a certain extent, visual preferences of a curator into a machine learning model. Figure 9 shows visualizations of model weights in the final personalization layer of eight of our curators. Aspects of their different styles are encoded in these models, but they are not a complete representation of the human thought process. They are a mechanism to capture and recreate recurring judgements she or he makes for a particular curation. It is difficult to translate into language concepts like cinematic style, social realism, or intimacy. A metaphor we use inside EyeEm is to view the personalized models as equivalent to written notes, but purely defined and specified in terms of visuals that can be shared among curators. It provides avenues for interesting dialogue on photography, and augments the curators in their exploration and delineation of aspects relating to aesthetics.
The Future
If photography is permitted to supplement some of art’s functions, they will forthwith be usurped and corrupted by it, thanks to photography’s natural alliance with the mob. It must therefore revert to its proper duty, which is to serve as the handmaiden of science and the arts.
— Charles Baudelaire, On Photography, from The Salon of 1859
The fate of technology and photography have long been intertwined. Photography is a creation of technology. For a brief period of time after the invention of photography, its role beyond the scientific and documentation realm was criticized. However, it quickly became an essential expressive medium for the artistic community; it helped push forward various cultural movements like modernism, postmodernism, and globalization. As technology facilitated a digitized, networked and connected society, visual language—driven by photographs— elevated itself into one of the most effective communication channels available. We live in a world now where most people own a camera and take photographs. An imminent problem is how to organize, search and re-use our photographs. Deep learning methods are successful in such tasks.
It’s important to be mindful that a machine learning model (summarizing patterns within a dataset) does not posses any latent creativity or originality. These models are a modern form of journal that is showing promise in recording the visual mind, a task which humanity is struggling continuously to express via text and language. However, we must constantly scrutinize a trained model and always use it to solve problems for photography and photographers.
We embarked on this journey with great excitement, a hint of trepidation, and the hope that we can make a positive impact on the wonderful medium of photography.
Join EyeEm at GTC!
Appu will be presenting about our work using GPUs for machine learning and personalized aesthetics at the 2017 GPU Technology Conference, May 8-11 in San Jose, CA. Come see his talk, session S7683, “Recording the Visual Mind: Understanding Aesthetics with Deep Learning”
GTC is the largest and most important event of the year for GPU developers. Register by April 5th to get the early bird discount rate, and use code CMDLIPF to receive an additional 20% off!
Acknowledgements
We would like to thank the creative service and photography teams at EyeEm, with whom we conversed and interacted heavily for this work.