Devin White, Senior Research Scientist in the Geographic Information Science and Technology Group at Oak Ridge National Laboratory, shares how his team uses computer vision, photogrammetry and high performance techniques accelerated with GPUs to automatically validate the geopositioning accuracy of satellite imagery.
Devin White, Senior Research Scientist in the Geographic Information Science and Technology Group at Oak Ridge National Laboratory, shares how his team uses computer vision, photogrammetry and high performance techniques accelerated with GPUs to automatically validate the geopositioning accuracy of satellite imagery.
White talked with us about the research at the 2016 GPU Technology Conference.
Brad Nemire: Tell us a bit about your research.
Devin White: The general public, and the vast majority of scientists, assume that when you are given an image collected by a satellite, manned aircraft, or unmanned aerial system, you can trust the information that comes along with it that allows you to place it in the real world via specialized software, usually referred to as a Geographic Information System (GIS). The various online global map services available today, like Google Maps and Bing Maps, inadvertently help to reinforce this assumption: You can go to virtually any location on the Earth’s surface in your web browser and find high spatial resolution aerial or orbital imagery with a network of roads, administrative boundaries, and other points of interest precisely overlaid on top of it—often with the ability to go backwards and forwards in time to see how the landscape has changed. A lot of manual work goes into making that happen, behind the scenes.
The process of collecting and properly placing what we call remotely sensed data is much more complicated than one might think. Every image carries with it some degree of uncertainty about its true location, which is generally small for expensive satellites and large for inexpensive drones. In other words, you get what you pay for.
With the recent explosion in availability of inexpensive systems, more remotely sensed data is being collected than ever before, but when you try to place it in the world, it is often in the wrong location and the difference from ground truth can be quite substantial. Several organizations we work with are dealing with very large volumes of this type of data and cannot afford to have people manually correct each image using traditional techniques. Our research is focused on building an automated solution to the problem that leverages an innovative blend of photogrammetry, image science, computer vision, and high performance computing to rapidly register these problematic images to more trusted sources.
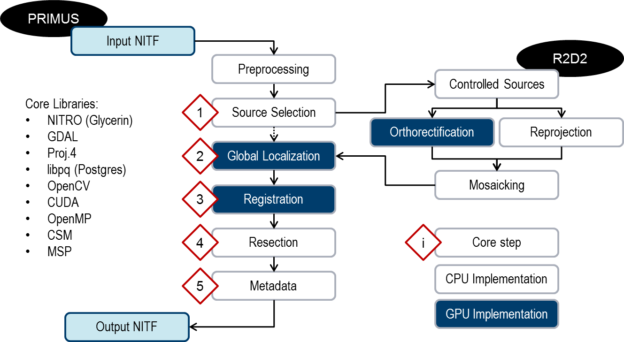
Our image registration solution, known as PRIMUS (Figure 1), involves several core steps and takes advantage of CPU-GPU hybrid parallelism wherever possible. It is constantly evolving as we integrate new algorithms and find new ways to optimize performance.
BN: What are some of the biggest challenges in this project?
DW: We are combining sophisticated processing techniques pulled from a wide variety of imagery-related disciplines to build an automated, robust, scalable, and efficient geolocation improvement solution. Computationally speaking, using methods from any of those disciplines and translating them into something that can run on GPUs is a daunting task. For example, our registration module, which is arguably where the majority of our computing resources should be dedicated while processing an image, is filled with a large number of powerful algorithms we are pulling from OpenCV, of which only a handful have been implemented by others in CUDA (and in those cases, not necessarily well). We spent a great deal of time either modifying or completely rewriting certain algorithms to get the performance we needed. This type of computational challenge exists in every single module, albeit in slightly different forms.
For the majority of our photogrammetric work, though, we had to start from scratch. In addition to the computational challenges, we have several operational ones as well: (1) develop required applications using only open source, in-house, or government-furnished software; (2) leverage well-established techniques to reduce risk; (3) expose all components as services that can communicate with one another; (4) use high performance computing architectures and paradigms wherever possible; (5) strictly adhere to and take full advantage of existing metadata standards to enable interoperability; and (6) keep the system as flexible as possible through extensive use of plugin frameworks. These requirements drove every aspect of the system’s creation.
BN: What NVIDIA technologies are you using to overcome the challenges?
DW: Our image registration solution is currently deployed on a system that contains many high-density HPC nodes with a lot of CPU cores and RAM. Each one contains four NVIDIA Tesla K80 GPUs, giving us a total of eight GPUs per node. We have several challenging computational problems, but I wanted to share one that many reading this might appreciate: quickly calculating normalized mutual information (NMI) to support cross-modal image registration without sacrificing any accuracy. While we do use a wide variety of other metrics for registration, this is a solid one that we wanted to include, but doing so came at a heavy price.
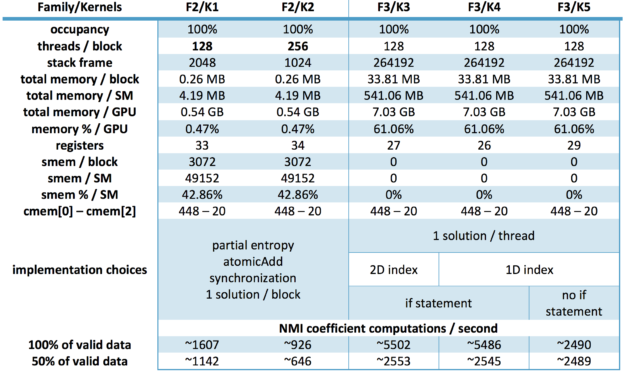
Existing solutions focused on solving a single matching case with small images and a small number of features. We needed a solution that could work with large numbers of large images where tens of thousands of features were being compared simultaneously, so a scientist on my team, Sophie Voisin, built one. The main bottleneck we ran into while implementing our CUDA-based solution was creating large joint histograms. We wanted an exhaustive search of the solution space using the full data range, 256×256, which meant that we would have to work with 65536 bins. That is a very large number of bins.
We experimented with multiple kernels to meet this requirement and they can be placed into three distinct families based on how they were implemented. The first family handled one NMI metric computation at a time, with each tied to a separate kernel launch. This naïve implementation was time consuming, and even if shared memory was used to compute piecewise histograms there were far too many thread synchronizations and atomic operations. On the bright side, it gave us a baseline to work from.
The second family handled individual NMI metric computations at the block level, so several could be run simultaneously. It was faster than the first family, but the kernels still used too many thread synchronizations and atomic operations, resulting in less than ideal execution times. For the third family, each thread handled an individual NMI metric computation at the global level, which we could do because of the large amount of global memory available on the K80. This change resulted in no atomic operations and no intermediate synchronizations, which significantly reduced execution times and brought us within the range of our initial registration requirement, which was thirty seconds. While there are other solutions available that might be able to complete the registration process more quickly, they are definitely not doing so as rigorously or as accurately as we are. (See Figure 2)
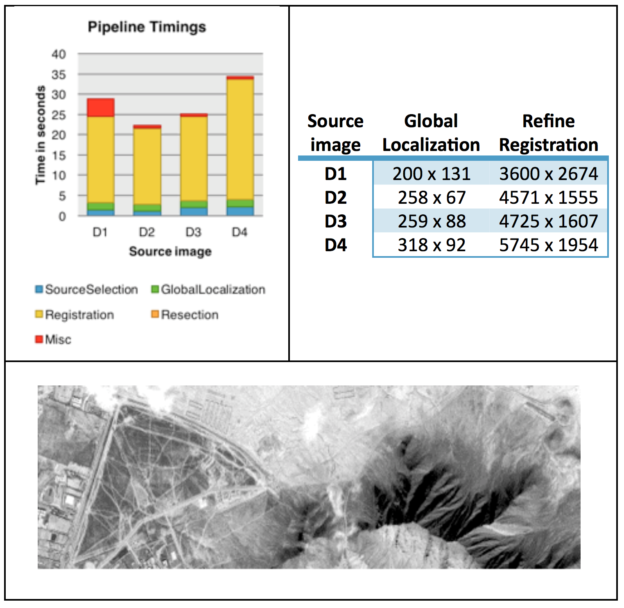
BN: What is the impact of your research to the larger science community?
DW: We are witnessing a revolution with respect to overhead imagery collected by aerial and orbital sensors, one where the Earth will be observed constantly by large constellations of inexpensive unmanned aerial vehicles and satellites. The catch is that the poor geolocation that generally comes along with these systems will limit the usability of collected data unless a process is in place to correct the issue. Ideally that process would be automated, given how much imagery we are talking about, and the solution we have developed is one way to solve the problem.
In addition to the scientific community, which relies heavily on remotely sensed imagery to do its work, one must consider the broader world. Humanitarian assistance and disaster response organizations are increasingly relying on imagery collected in the field, often obtaining it quickly because lives are at risk. Accuracy is usually sacrificed in the process and being able to rapidly restore that without a human in the loop is hugely important.
BN: Why did you start looking at using NVIDIA GPUs?
DW: When we were asked to solve this particular image registration problem, where there are large volumes of images coming in very quickly at multiple locations, we immediately realized that the only way it could possibly be done was by using GPUs. A lot of GPUs. Our biggest question wasn’t if we should use them, but how we could orchestrate processing jobs across a large number of them and, when possible, have them team up to solve a problem more quickly.
BN: What is your GPU Computing experience and how have GPUs impacted your research?
DW: Collectively, my team and I have taken advantage of GPU-based hardware acceleration for many different geospatial analysis and visualization projects over the past nine years, working with CUDA since version 1.0. When I arrived at ORNL four years ago, right when our supercomputer Jaguar was being upgraded with GPUs (now called Titan, the fastest machine in the United States), my perspective on the scale and significance of problems that I could solve with computing changed dramatically. GPUs have given us the freedom to not cut corners in any area, especially when it comes to photogrammetry, thus ensuring that we can rapidly deliver the highest quality solution possible.
BN: What’s next for this research?
DW: The first version of our solution, which is now successfully registering large volumes of imagery, was focused on building a solid technological foundation and solving geolocation issues for one particular sensor at several key processing centers. The goal was to field a solution as quickly as possible so it could do the largest amount of good. The next version will take an agnostic and more flexible approach to hardware-accelerated registration algorithms and sensor support, will include a wide array of hardware-accelerated preprocessing algorithms (e.g., atmospheric correction, cloud detection, pansharpening, artifact mitigation, and terrain extraction from multi-view collections), and will rely on a new class of trusted control data that is much higher fidelity than what we are currently using. All of this will greatly boost geolocation accuracy, but will also greatly increase computational load, so we are working on multiple optimization initiatives simultaneously to ensure that overall processing times will not increase.
There are several more versions of the solution planned after the one I describe above, where we will continue to generalize and optimize. We are also moving into the application of deep learning for the extraction of information from the imagery, and will likely leverage the new Pascal architecture GPUs to do so, and we’re exploring the possibility of having the solution be more mobile by putting it in small field-deployable boxes and running it onboard platforms as they are flying around by leveraging cards like the Jetson TX1. There are some trade-offs involved in the miniaturization process with respect to speed and accuracy, though, so we are proceeding cautiously in that area.
BN: In terms of technology advances, what are you looking forward to in the next five years?
DW: I’m most excited about NVLink and similar efforts, which will allow for much more efficient communication between GPUs as they team up to solve larger and more complex problems, the continued miniaturization of massively parallel processing systems being driven (no pun intended) by advances in autonomous navigation, and the coming ubiquity of small footprint and low power sensors that will be able to collect an unprecedented amount of high quality data about the physical world (e.g., on unmanned aerial vehicles and smallsats). I look forward to working with that data, and doing so quickly.