Artificial intelligence powered by deep learning now solves challenges once thought impossible, such as computers understanding and conversing in natural speech and autonomous driving. Inspired by the effectiveness of deep learning to solve a great many challenges, the exponentially growing complexity of algorithms has resulted in a voracious appetite for faster computing. NVIDIA designed the Volta Tensor Core architecture to meet these needs.
NVIDIA and many other companies and researchers have been developing both computing hardware and software platforms to address this need. For instance, Google created their TPU (tensor processing unit) accelerators which have generated good performance on the limited number of neural networks that can run on TPUs.
In this blog, we share some of our recent advancements which deliver dramatic performance gains on GPUs to the AI community. We have achieved record-setting ResNet-50 performance for a single chip and single server with these improvements. Recently, fast.ai also announced their record-setting performance on a single cloud instance.
Our results demonstrate that:
- A single V100 Tensor Core GPU achieves 1,075 images/second when training ResNet-50, a 4x performance increase compared to the previous generation Pascal GPU.
- A single DGX-1 server powered by eight Tensor Core V100s achieves 7,850 images/second, almost 2x the 4,200 images/second from a year ago on the same system.
- A single AWS P3 cloud instance powered by eight Tensor Core V100s can train ResNet-50 in less than three hours, 3x faster than a TPU instance.

Massive parallel processing performance on a diversity of algorithms makes NVIDIA GPUs naturally great for deep learning. We didn’t stop there. Tapping our years of experience and close collaboration with AI researchers all over the world, we created a new architecture optimized for the many models of deep learning – the NVIDIA Tensor Core GPU.
Combined with high-speed NVLink interconnect plus deep optimizations within all current frameworks, we achieve state-of-the-art performance. NVIDIA CUDA GPU programmability ensures performance for the large diversity of modern networks, as well as provides a platform to bring up emerging frameworks and tomorrow’s deep network inventions.
V100 Tensor Core Delivers Fastest Single Processor Speed Record
NVIDIA’s Tensor Core GPU architecture built into Volta GPUs represents a huge advancement in the NVIDIA deep learning platform. This new hardware accelerates computation of matrix multiples and convolutions, which account for most of the computational operations when training a neural network.
NVIDIA Tensor Core GPU architecture allows us to simultaneously provide greater performance than single-function ASICs, yet be programmable for diverse workloads. For instance, each Tesla V100 Tensor Core GPU delivers 125 teraflops of performance for deep learning compared to 45 teraflops by a Google TPU chip. Four TPU chips in a ‘Cloud TPU’ deliver 180 teraflops of performance; by comparison, four V100 chips deliver 500 teraflops of performance.
Our CUDA platform enables every deep learning framework to harness the full power of our Tensor Core GPUs to accelerate the rapidly-expanding universe of neural network types such as CNN, RNN, GAN, RL, and the thousands of variants emerging each year.
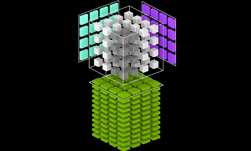
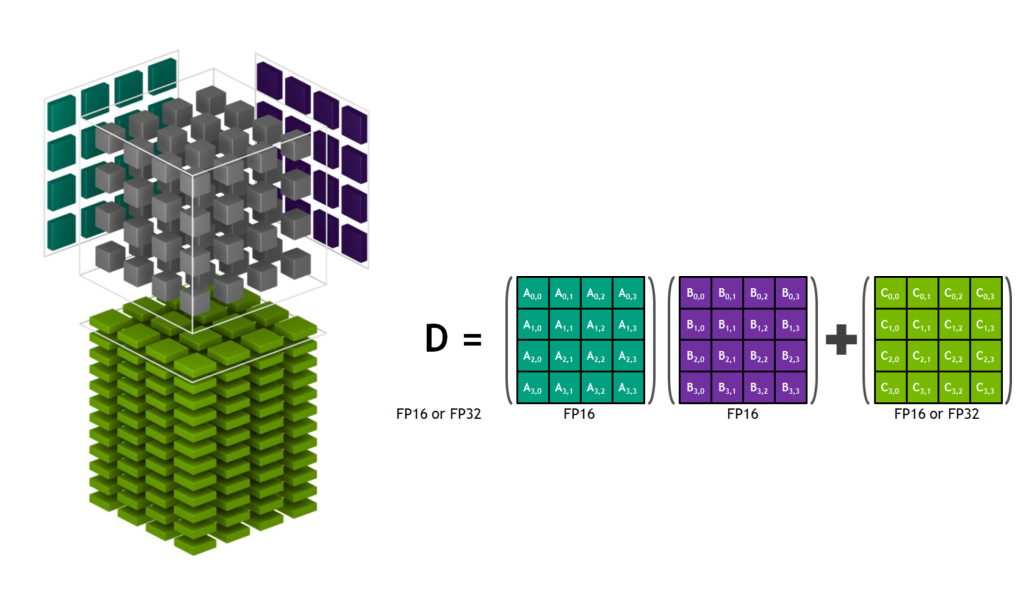
Let’s dive a little deeper into the Tensor Core architecture in order to highlight its unique capabilities. Figure 2 shows Tensor Cores operating on tensors stored in lower-precision FP16 while computing with higher-precision FP32, maximizing throughput while still maintaining necessary precision.
ResNet-50 training now achieves an impressive 1,360 images per second on a single V100 in standalone tests with recent software improvements. We’re now working to integrate this training software into popular frameworks as described below.
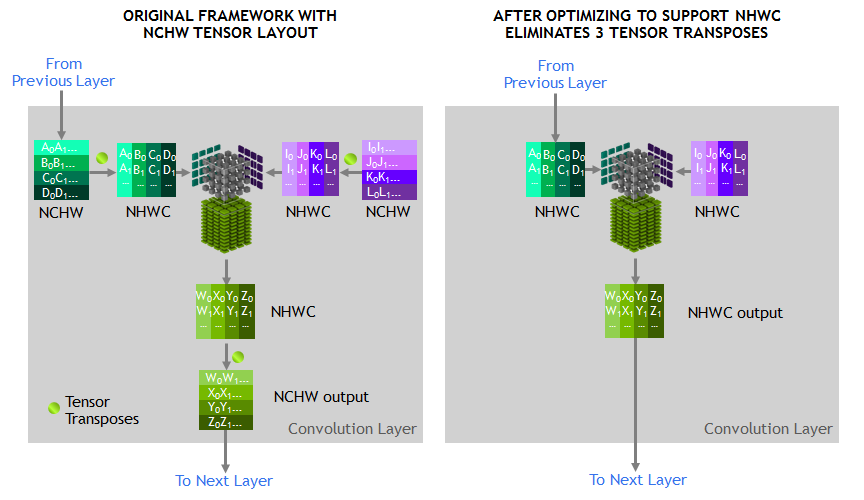
The tensors operated on by Tensor Cores should be in a channel-interleaved data layout in memory (Number-Height-Width-Channel, often called NHWC) in order to get the best performance. The layout expected in memory by the training framework is channel-major data layout (Number-Channel-Width-Height, often called NCHW). So the cuDNN library executes tensor transpose operations between NCHW and NHWC, as shown in figure 3. As previously mentioned, since the convolutions themselves are now so fast, these transposes accounted for a noticeable fraction of the runtime.
To eliminate these transposes, we eliminate these transposes by instead representing every tensor in the RN-50 model graph in NHWC format directly, a feature supported by the MXNet framework. Furthermore, we added optimized NHWC implementations to MXNet and cuDNN for all other non-convolution layers, eliminating the need for any tensor transposes during training.
Another optimization opportunity arose as a consequence of Amdahl’s Law, which predicts the theoretical speedup with parallel processing. Since Tensor Cores significantly speed up matrix multiplication and convolution layers, other layers in the training workload became a larger fraction of the runtime. So we identified these new performance bottlenecks and optimized them.
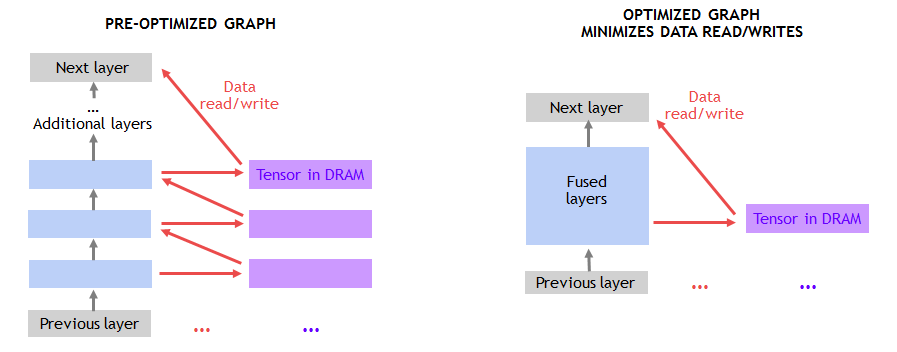
The performance of many of the non-convolution layers is limited by moving data to and from DRAM, shown in figure 4. Fusing consecutive layers together makes use of on-chip memory and avoids DRAM traffic. For example, we created a graph optimization pass in MXNet to detect consecutive ADD and ReLu layers, replacing them with a fused implementation whenever possible. It’s straightforward to implement these types of optimizations in MXNet using NNVM (Neural Network Virtual Machine).
Finally, we continued to optimize individual convolutions by creating additional specialized kernels for commonly-occurring convolution types.
We’re currently contributing many of these optimizations into multiple deep learning frameworks, including TensorFlow, PyTorch, and MXNet. We achieved 1,075 images/second on a single Tensor Core V100 with our contributions to MXNet using a standard 90-epoch training schedule while hitting the same Top-1 classification accuracy (over 75%) as single-precision training. This leaves us with significant headroom for further improvements, since we can post 1,360 images/second in standalone testing. These performance improvements will be available in NVIDIA-optimized deep learning framework containers on NGC.
The Fastest Single-Node Speed Record
Multiple GPUs can operate as a single node to enable substantially higher throughput. However, scaling to multiple GPUs working together in a single server node requires high-bandwidth / low-latency communication paths between GPUs. Our NVLink high-speed interconnect fabric allows us to scale our performance to eight GPUs in a single server. These massively-accelerated servers provide one full petaflop of deep learning performance and are widely available in the cloud as well as for on-premise deployments.
However, scaling to eight GPUs increases training performance substantially enough that other work performed by the host CPU in the framework becomes the performance limiter. Specifically, the data pipeline feeding GPUs in frameworks needed a substantial performance boost.
The data pipeline reads encoded JPEG samples from disk, decodes them, performs a resize and augments the image (see Figure 5). These augmentation operations improve the learning ability of the neural network, resulting in higher-accuracy prediction of the trained model. With eight GPUs processing the training portion of the framework, these important operations limit the overall performance.

To address this issue, we developed DALI (Data Augmentation Library), a framework-agnostic library to offload work from the CPU onto the GPU. DALI, shown in Figure 6, moves parts of the JPEG decode to the GPU, along with the resize and all other augmentations. These operations execute much faster on the GPU than the CPU, so offload the CPU. DALI highlights the power of CUDA’s general parallel performance. Eliminating the CPU bottleneck lets us sustain 7,850 images/second on a single node.
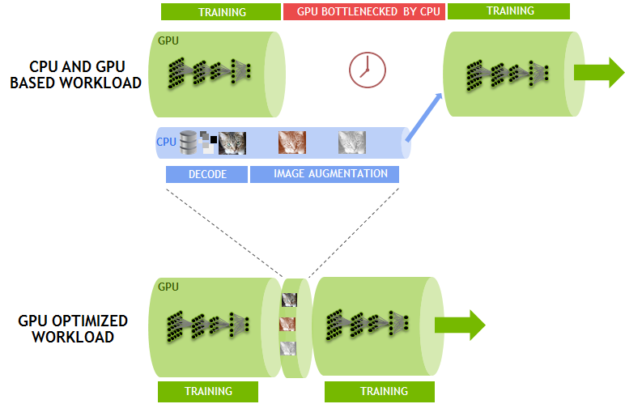
NVIDIA is helping integrate DALI into all the major AI frameworks. This solution also allows us to scale up performance beyond eight GPUs, for systems such as the recently-announced NVIDIA DGX-2 with 16 Tesla V100 GPUs.
The Fastest Single Cloud Instance Speed Record
For our single GPU and single node runs we used the de facto standard of 90 epochs to train ResNet-50 to over 75% accuracy for our single-GPU and single-node runs. Training time can, however, be further reduced through algorithmic innovation and hyperparameter tuning to achieve accuracy with a smaller number of epochs. GPUs provide AI researchers programmability and support all DL frameworks to enable them to explore new algorithmic approaches and take advantage of existing ones.
The fast.ai team recently shared their excellent results, reaching high accuracy in much less than 90 epochs using PyTorch. Jeremy Howard and researchers at fast.ai incorporated key algorithmic innovations and tuning techniques to train ResNet-50 on ImageNet in just three hours on a single AWS P3 instance, powered by eight V100 Tensor Core GPUs. ResNet-50 ran three times faster than a TPU based cloud instance which takes close to nine hours to train ResNet-50.
We further expect the methods described in this blog to improve throughput will be applicable to other approaches such as fast.ai’s and will help them converge even faster.
Delivering Exponential Performance Improvements
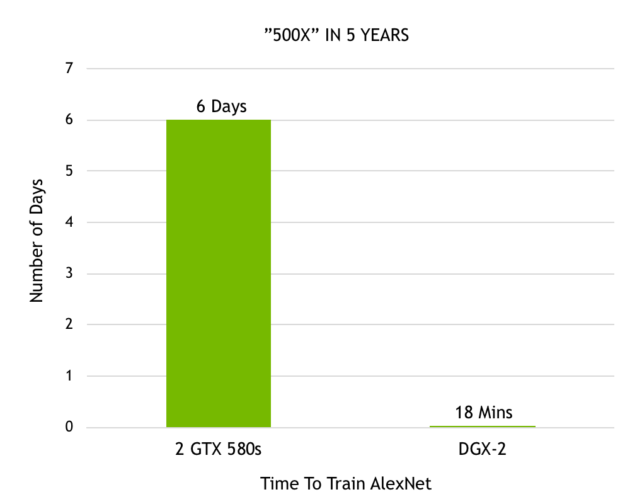
Since the time Alex Krizhevsky won the first Imagenet competition powered by 2 GTX 580 GPUs, the progress we have made in accelerating deep learning has been incredible. Krizhevsky took six days to train his brilliant neural network, called AlexNet, which outperformed all other image recognition approaches at the time, kicking off the deep learning revolution. Now with our recently announced DGX-2 we are able to train AlexNet in just 18 minutes. Figure 7 demonstrates this 500x performance boost in just over 5 years.
Facebook AI Research (FAIR) has shared their language translation model called Fairseq. We demonstrated a 10x higher performance gain on Fairseq in less than a year with our recently-announced DGX-2 plus our numerous software stack improvements (see figure 8).
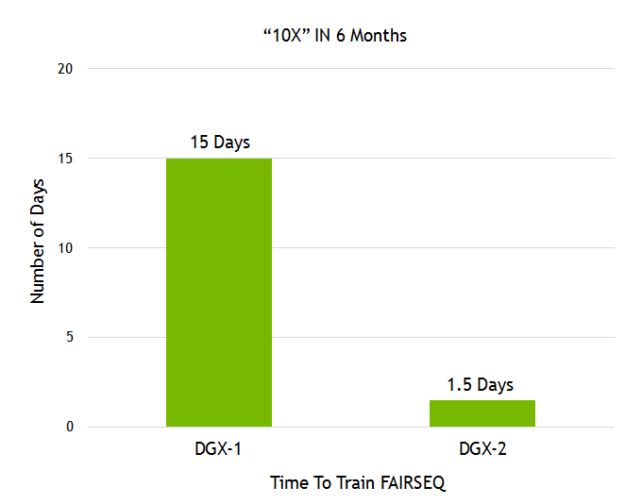
Image recognition and language translation represent just a couple of the countless use-cases that researchers solve with the power of AI. Over 60,000 neural network projects using GPU-accelerated frameworks have been posted to Github. The programmability of our GPUs provides acceleration to all kinds of neural networks that the AI community is building. The rapid pace of improvement ensures that AI researchers can imagine even more complex neural networks to address grand challenges using AI.
These consistent gains result from our full stack optimization approach to GPU-accelerated computing. From building the most advanced deep learning accelerators to complex systems (HBM, COWOS, SXM, NVSwitch, DGX), from advanced numerics libraries and a deep software stack (cuDNN, NCCL, NGC), to accelerating all DL frameworks, NVIDIA’s commitment to AI offers unparalleled flexibility for AI developers.
We will continue to optimize through the entire stack and continue to deliver exponential performance gains to equip the AI community with the tools for driving deep learning innovation forward.
Summary
AI continues to transform every industry, driving countless use-cases. The ideal AI computing platform needs to provide excellent performance, scale to support giant and growing model sizes, and include programmability to address the ever-growing diversity of model architectures.
NVIDIA’s Volta Tensor Core GPU is the world’s fastest processor for AI, delivering 125 teraflops of deep learning performance with just a single chip. We’ll soon be combining 16 Tesla V100s into a single server node to create the world’s fastest computing server, offering 2 petaflops of performance.
Beyond performance, the programmability and broad access of GPUs available on every cloud, and from every server maker, to the entire AI community is enabling the next generation of AI.
No matter what the framework choice, we accelerate them all: Caffe2, Chainer, Cognitive Toolkit, Kaldi, Keras, Matlab, MXNET, PaddlePaddle, Pytorch, and TensorFlow. In addition, NVIDIA GPUs work with the rapidly-expanding universe of CNN, RNN, GAN, RL, and hybrid network architectures, as well as thousands of variants invented each year. AI community has generated amazing applications and we look forward to powering what AI can do next.