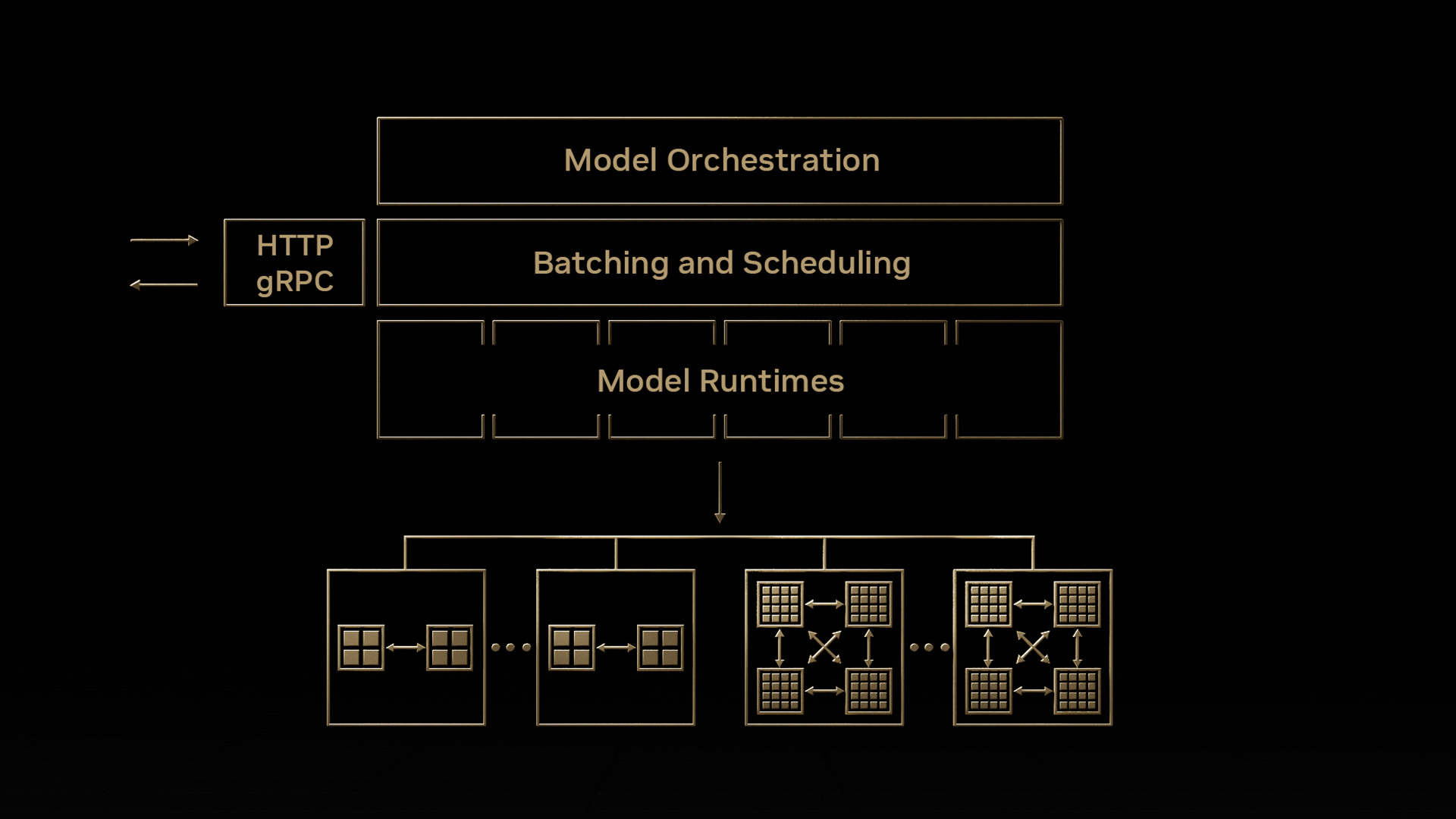
You’ve built, trained, tweaked and tuned your model. You finally create a TensorRT, TensorFlow, or ONNX model that meets your requirements. Now you need an inference solution, deployable to a datacenter or to the cloud. Your solution should make optimal use of the available GPUs to get the maximum possible performance. Perhaps other requirements also exist, such as needing A/B testing capabilities or the ability to support servers that have multiple homogeneous or heterogeneous GPUs. Enter NVIDIA Triton Inference Server.
Triton Server (formerly NVIDIA TensorRT Inference Server) simplifies the deployment of AI models at scale in production. Triton Server is open-source inference server software that lets teams deploy trained AI models from many frameworks, including TensorFlow, TensorRT, PyTorch, and ONNX. Triton Server runs models concurrently to maximize GPU utilization, supports CPU-based inferencing, offers advanced features like model ensembling and streaming inferencing, and provides a number of other features that help you bring models to production rapidly. Also available as a Docker container, Triton Server integrates with Kubernetes for orchestration and scaling and exports Prometheus metrics for monitoring, thus helping IT/DevOps streamline model deployment in production.
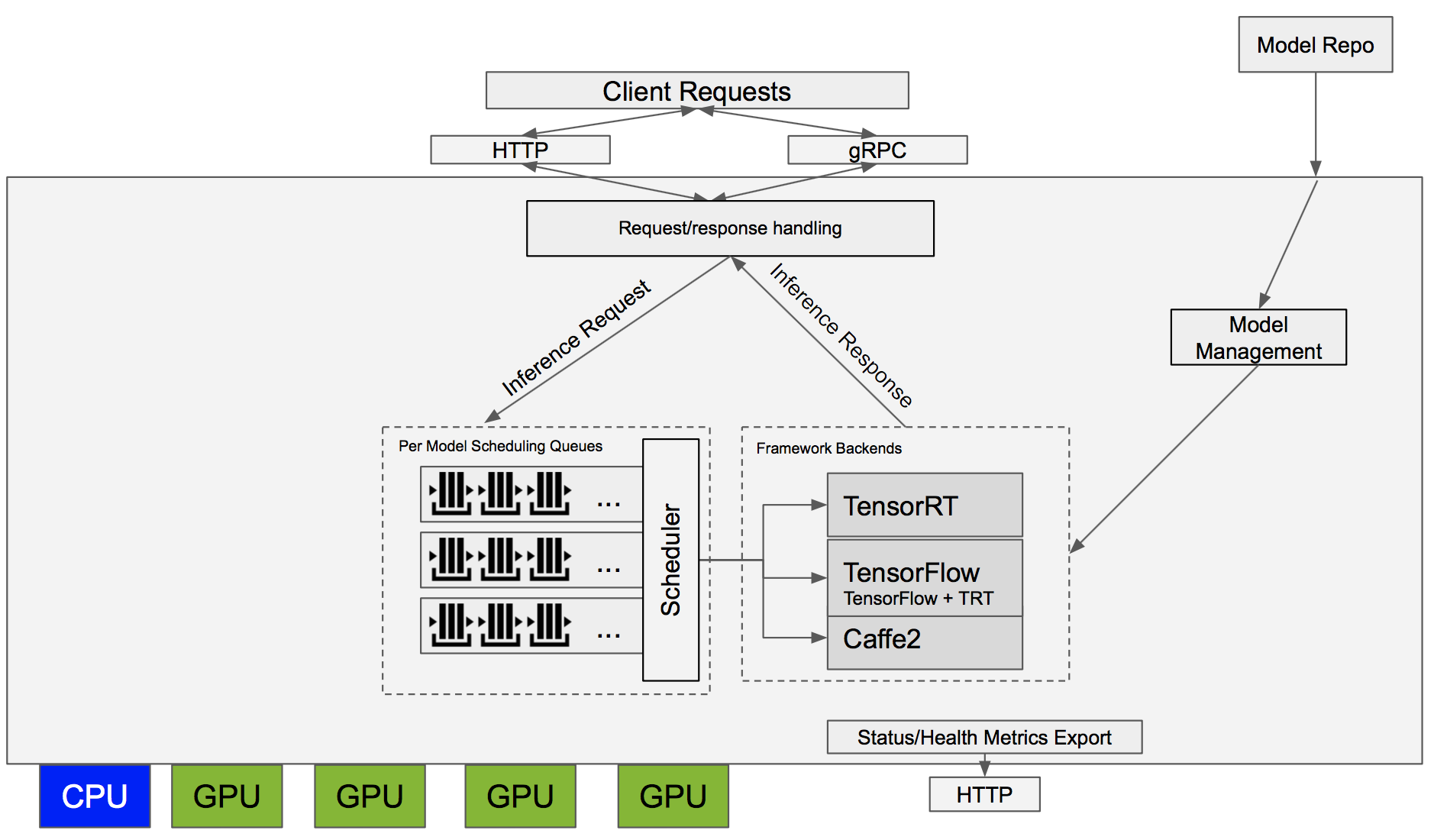
Let’s take a look at the inference server and see how it can be the basis for a high-performance, GPU-accelerated production inference solution.
Getting the Triton Server Container
You need to install some software such as Docker before using the inference server container. You’ll find details on this in the Installing Docker and NVIDIA Docker section from the NVIDIA Docker blog post.
The container is available from the NVIDIA GPU Cloud (NGC) container registry. The inference server updates monthly, so be sure to pull the most recent version of the container. You can pull the container to your local system or use any of the supported platforms for NGC containers.
$ docker pull nvcr.io/nvidia/tensorrtserver:18.09-py3
Once you’ve downloaded the container, it’s time to take a quick look at its contents. Let’s fire up a bash shell within the container.
$ nvidia-docker run -it --rm nvcr.io/nvidia/tensorrtserver:18.09-py3
The /opt/tensorrtserver directory contains the inference server executable — /opt/tensorrtserver/bin/trtserver — plus shared libraries. You can see the available options by running:
$ trtserver --help
If you are using the 18.08.1 version use the nvcr.io/nvidia/inferenceserver:18.08.1-py3 container and find the trtserver in /opt/inference_server/bin/inference_server.
To run trtserver, you’ll need to set up a model repository. Let’s look at how to do that.
Triton Server Model Repository
The set of models that Triton Server makes available for inferencing is in the model repository. You create a model repository and populate it with any mix of TensorRT, TensorFlow and Caffe2 models. Each model can include one or more versions. You can’t change which models live in your model repository while trtserver is running but you can replace older versions of those models with newer ones. Trtserver automatically recognizes those changes.
Let’s begin with the simplest case, then enhance it to show additional functionality. First, take a look at the general format of the model repository. The model repository lives in a directory on your file system; let’s assume that directory is /tmp/models. You’ll find a subdirectory for each model within the parent directory in which the subdirectory name matches the model name. Each model subdirectory contains a configuration file, config.pbtxt, and one or more numeric subdirectories each holding a version of the model.
For example, if you have one TensorRT model called “mymodel” that has only a single version, version 3, your model repository looks like:
/tmp/models
mymodel/
config.pbtxt
3/
model.plan
This is a minimal model repository. The model configuration, config.pbtxt, provides model metadata to trtserver and model.plan is the actual TensorRT model definition. Let’s talk about both of these in more detail.
Model Configuration
Each model in the model repository must include a config.pbtxt file that contains the configuration information for the model. The model configuration must be specified as protobuf text using the ModelConfig schema. You can look at that file to find a description of all the possible values; for now let’s use the following example to explore the most important features. This example configuration is for the Caffe2 ResNet 50 model.
name: "resnet50_netdef" platform: "caffe2_netdef" max_batch_size: 128 input [ { name: "gpu_0/data" data_type: TYPE_FP32 format: FORMAT_NCHW dims: [ 3, 224, 224 ] } ] output [ { name: "gpu_0/softmax" data_type: TYPE_FP32 dims: [ 1000 ] } ]
The name field defines the name of the model. You can give your model any name you like but it must be unique within the model repository. The name must match the name of the model subdirectory containing this configuration. This is the name that you will use to refer to the model when making an inference request to trtserver.
The platform field tells trtserver the type of this model. In this case, this is a Caffe2 model using the NetDef format.
The max_batch_size field controls the maximum batch size that trtserver allows for inferencing. The model definition may support larger batch sizes but any inference requests will be limited to this value.
The input field is a list of the inputs required to perform inference. In this case you can see only a single input called gpu_0/data. The data_type and dims field indicate how to interpret the input tensors. The optional format field helps trtserver and clients understand what the input represents. In this case FORMAT_NCHW indicates that the input tensor represents an image in CHW (channel, height, width) format.
The output field is similar to input except that the format field is currently unavailable. You must specify at least one output but you should only list the model outputs that you want to be exposed by trtserver. The server will allow only these outputs to be requested when performing an inference.
You will also see model instances, model version policy and model compute capability in the ModelConfig schema. These are more advanced configuration options that I’ll touch on below.
TensorFlow Models
TensorFlow saves trained models in one of two ways: GraphDef and SavedModel. Triton Server supports both these formats. Once you have a trained model in TensorFlow you can save it as a GraphDef directly or convert it to a GraphDef by using a script like freeze_graph.py, or save it as a SavedModel using a SavedModelBuilder or tf.saved_model.save.
TensorFlow 1.7 and later integrates TensorRT to enable TensorFlow models to benefit from the inference optimizations provided by TensorRT. Because trtserver supports TensorFlow models that have been optimized with TensorRT, those models can be served just like any other TensorFlow model.
The model has a configuration file in the model repository and the model definition file is the GraphDef file or the SavedModel directory.
/tmp/models
graphdef_model/
config.pbtxt
1/
model.graphdef
You set the platform field to tensorflow_graphdef or tensorflow_savedmodel in the configuration file to indicate that the model definition format is TensorFlow GraphDef or SavedModel, respectively.
Caffe2 Models
The inference server supports Caffe2 models in the NetDef format. NetDef model definitions split across two files: the initialization network and the predict network. Both these files must be stored in the version directory of the model repository. For example:
/tmp/models
netdef_model/
config.pbtxt
1/
init_model.netdef
model.netdef
You set the platform field to caffe2_netdef in the configuration file to indicate that the model definition format is Caffe2 NetDef.
TensorRT Models
The inference server supports the TensorRT model format, called a TensorRT PLAN. A TensorRT PLAN differs from the other supported model formats because it is GPU-specific. A generated TensorRT PLAN is valid for a specific GPU — more precisely, a specific CUDA Compute Capability. For example, if you generate a PLAN for an NVIDIA P4 (compute capability 6.1) you can’t use that PLAN on an NVIDIA Tesla V100 (compute capability 7.0).
What if you have both P4s and Tesla V100s in your data center and want to use them both for inference? How do you provide multiple PLANs for a single model? Although the previous model repository examples didn’t show it, you can provide multiple model definition files for any model version and associate each with a different compute capability. For example, if you have both compute capability 6.1 and 7.0 versions of a TensorRT model you can place them both in the version subdirectory for that model.
/tmp/models
plan_model/
config.pbtxt
1/
model_6_1.plan
model_7_0.plan
You then use the model configuration to indicate which model definition is associated with which compute capability, and trtserver chooses the version of the model that matches the compute capability of the GPU at runtime.
name: "plan_model" platform: "tensorrt_plan" max_batch_size: 16 input [ { name: "input" data_type: TYPE_FP32 dims: [ 3, 224, 224 ] } ] output [ { name: "output" data_type: TYPE_FP32 dims: [ 10 ] } ] cc_model_filenames [ { key: "6.1" value: "model_6_1.plan" } { key: "7.0" value: "model_7_0.plan" } ]
ONNX Models
Currently, trtserver cannot directly perform inferencing using ONNX models. However, since trtserver supports both TensorRT and Caffe2 models, you can take one of two paths to convert your ONNX model into a supported format.
You can convert your ONNX model to a TensorRT PLAN using either the ONNX Parser included in TensorRT or the open-source TensorRT backend for ONNX. Once you have a TensorRT PLAN you can add that PLAN to the model repository as described above. Another option is converting your ONNX model to Caffe2 NetDef, which yields a NetDef model that you can add to the model repository.
Classification Labels
When you send an inference request to trtserver, it runs the model with the provided input tensors and by default returns the requested output tensors. Alternatively, you can instead request that the output be interpreted as classification probabilities for models performing a classification and return the top-K classification results. Labels can be associated in the model repository for that model with each such output to allow trtserver to return labels with the top-K classification results. You simply give the name of the labels file in that output’s configuration to associate labels with an output :
output [
{
name: "gpu_0/softmax"
data_type: TYPE_FP32
dims: [ 1000 ]
label_filename: "resnet50_labels.txt"
}
]
Next, include the labels file in the model repository. The labels file has one line for each classification.
/tmp/models
netdef_model/
config.pbtxt
resnet50_labels.txt
1/
init_model.netdef
model.netdef
Versioning
Triton Server supports model versioning, allowing multiple versions of your models in the model repository. Allowing multiple versions enables many interesting use-cases, including rolling updates and A/B testing.
Each model can have one or more versions available in the model repository. Each version is stored in its own numerically named subdirectory. The name of the subdirectory corresponds to the version number of the model. You can add and remove version subdirectories while trtserver is running to make a new model version available for inferencing or to remove an existing version. The server makes sure that any inflight inferences are allowed to complete when you remove a model version so you don’t have to worry about coordinating inference requests with changes to the model repository.
Each model specifies a version policy as part of the model configuration. The version policy controls which versions in the model repository are made available by trtserver at any given time. The ModelVersionPolicy schema specifies one of the following policies.
- All: All versions of the model specified in the model repository are available for inferencing.
- Latest: Only the latest ‘n’ versions of the model specified in the model repository are available for inference. The numerically larger version numbers specify the latest versions of the model.
- Specific: The specifically listed versions of the model are available for inference.
By default, trtserver only makes the single latest version of the model available for inference. Below you’ll see an example of versioning in action.
Running Triton Server
Once you’ve set up a model repository, trtserver is ready to run and make those models available for inference. To demonstrate trtserver, let’s use the example model repository included in the public repo. Follow the instructions to run the fetch_models.sh script which initializes the model repository in the examples/model directory.
If you followed the set-up instruction above you already have nvidia-docker installed, so all you need to do is:
$ nvidia-docker run --rm -p8000:8000 -p8001:8001 -v/path/to/examples/models:/models nvcr.io/nvidia/tensorrtserver:18.09-py3 trtserver --model-store=/models
However, if you use the 18.08.1 version of the inference server, execute the following command instead of the above.
$ nvidia-docker run --rm -p8000:8000 -p8001:8001 -v/path/to/examples/models:/models nvcr.io/nvidia/inferenceserver:18.08.1-py3 inference_server --model-store=/models
Replace /path/to/examples/models with the path to the examples/models directory in your local clone of the repo. The first -p flag tells nvidia-docker to link host port 8000 with container port 8000. Trtserver listens for HTTP requests on port 8000 by default, but you can change that with the --http-port flag. The second -p flag tells nvidia-docker to link host port 8001 with container port 8001. Trtserver listens for GRPC requests on port 8001 by default, but you can change that with the --grpc-port flag. The -v flag maps your model repository into the container so that it appears at /models. The --model-store flag then points to /models to pick up your model repository within the container.
Trtserver will log output to the console as it starts so you can see it loading up the different models in your model repository. When the logging output stops, trtserver is ready to accept requests. The server provides both HTTP and gRPC interfaces but you can disable one or the other with the –allow-http and –allow-grpc flags. For the examples below let’s use HTTP but the gRPC equivalents are defined in grpc_service.proto.
You can ask it for a status by doing an HTTP GET request to the /api/status endpoint. You would should see something like this:
$ curl localhost:8000/api/status/resnet50_netdef id: "inference:0" version: "0.6.0" uptime_ns: 725971115438 model_status { key: "resnet50_netdef" value { config { name: "resnet50_netdef" platform: "caffe2_netdef" version_policy { latest { num_versions: 1 } } max_batch_size: 128 input { name: "gpu_0/data" data_type: TYPE_FP32 format: FORMAT_NCHW dims: 3 dims: 224 dims: 224 } output { name: "gpu_0/softmax" data_type: TYPE_FP32 dims: 1000 label_filename: "resnet50_labels.txt" } instance_group { name: "resnet50_netdef" count: 1 gpus: 0 gpus: 1 kind: KIND_GPU } default_model_filename: "model.netdef" } version_status { key: 1 value { ready_state: MODEL_READY } } } } ready_state: SERVER_READY
You can see the model’s configuration information from the status as well as data indicating that version 1 of the model is ready (MODEL_READY). You can now send inference requests to that model and trtserver will be able to handle them. A model version will show up as unavailable (MODEL_UNAVAILABLE) if it failed to load for some reason or if it was unloaded due to the model version policy that was discussed above.
Triton Server Client Libraries
Now that you’ve gotten trtserver serving models from your model repository, you can send inference requests. To send an inference request you must perform an HTTP POST request with HTTP headers describing the input and output tensors; the request body also must contain the raw input tensor values. The Triton Server User Guide has a section describing this inference API. A much easier way to make inference requests is to use the C++ or Python client libraries provided in the open-source repo. The client libraries support both HTTP and gRPC interfaces. For gRPC you can also use gRPC-generated libraries (which support many more languages than just C++ and Python) as describe on the public repo. You can easily incorporate inferencing into your C++ or Python application using these libraries.
Image Classification Example
Trtserver works with models of all kinds: image classification, object detection, MLP, language processing, and more. Models may have any number of inputs and outputs. As an example of how to use the client libraries, the repo includes example C++ and Python applications that work with image classification style networks like ResNet, Inception and VGG. You can use the example application to send an image to the network and get back the top classifications.
The documentation available in the GitHub repo describes how to use the Image Classification example, called image_client for the C++ version, image_client.py for the Python version, and grpc_image_client.py for the Python version that uses gRPC generated client library. Let’s try it using Caffe2 ResNet50 model from your model repository. If you followed the steps above you already have trtserver running so now you just need to run the image client and provide a image for classification.

Let’s see what happens when you run inference using ResNet50 on a coffee mug.
$ image_client.py -m resnet50_netdef -s INCEPTION -c 3 mug.jpg
Output probabilities:
batch 0: 504 (COFFEE MUG) = 0.777365267277
batch 0: 968 (CUP) = 0.213909029961
batch 0: 967 (ESPRESSO) = 0.00294389552437
Prediction totals:
cnt=1 (504) COFFEE MUG
That’s pretty good! By using the -c flag you asked trtserver to send back the top 3 classification results. The image_client example can perform most pre-processing (that is, image resize, data-type conversion, channel ordering) automatically based on information queried from trtserver about the model. But it cannot determine what type of scaling was done on the image pixel values during model training. So you need to tell image_client explicitly, using the -s INCEPTION flag in this case, that the model is expecting INCEPTION style scaling of the input image.
The image_client example can also send batched input to trtserver. The image_client example just concatenates the same image multiple times to create an input batch. Use the -b flag to control the amount of batching.
$ image_client.py -m resnet50_netdef -s INCEPTION -b 16 mug.jpg
Prediction totals:
cnt=16 (504) COFFEE MUG
As expected, you see that all 16 images in the batch were found to be coffee mugs. Let’s ask trtserver for the model status again and see what has changed.
$ curl localhost:8000/api/status/resnet50_netdef
...
version_status {
key: 1
value {
ready_state: MODEL_READY
infer_stats {
key: 1
value {
success {
count: 1
total_time_ns: 4545866828
}
run {
count: 1
total_time_ns: 4545470313
}
run_wait {
count: 1
total_time_ns: 410
}
}
}
infer_stats {
key: 16
value {
success {
count: 1
total_time_ns: 1536601770
}
run {
count: 1
total_time_ns: 1536025131
}
run_wait {
count: 1
total_time_ns: 463
}
}
}
}
You can now see the version_status for version 1 of the resnet50_netdef model now has additional infer_stats information. The schema for these stats notes that the infer_stats key is the batch size and the value is various statistics collected for inferences of the model. In this case, two inferences have been performed, one at batch size 1 and another at batch size 16.
Version Update Example
Let’s leave trtserver running and try adding a new version to see how trtserver handles that. From the status above you see that resnet50_model has the default version policy which makes available only the most recent (highest numbered) version of the model.
version_policy {
latest {
num_versions: 1
}
}
Let’s create a new version by copying the existing one. This is not what you’d do with your own model versions but offers an easy way for you to see the version policy in action.
$ cp -r /path/to/examples/models/resnet50_netdef/1 /path/to/examples/models/resnet50_netdef/2
Because the policy dictates that only the most recent version should be available, logging in the trtserver console shows the server loading version 2 and unloading version 1. (You may need to wait a short time to see the logging because trtserver only checks for file-system changes periodically). Checking the status again after the logging appears shows that version 1 is no longer available and the new version 2 is available.
$ curl localhost:8000/api/status/resnet50_netdef
...
version_status {
key: 1
value {
ready_state: MODEL_UNAVAILABLE
...
}
}
version_status {
key: 2
value {
ready_state: MODEL_READY
}
}
Performance
The open-source repo also includes a perf_client example that measures inferences-per-second vs. latency for models running on trtserver. The perf_client is measuring performance so it sends random values for all input tensors and reads all output tensors but ignores their value. The perf_client is an easy way to demonstrate some of the Triton Server performance features. Let’s look at some results running the 18.09 container on an Ubuntu 16.04 workstation with an Intel® Xeon® Gold 6140 CPU (Skylake) and an NVIDIA V100 GPU. All results are gathered with the perf_client running on the same system as trtserver.That means that client/server overheads are included in the results but network latencies are not.
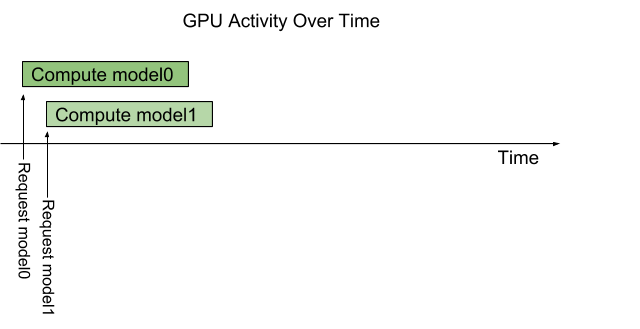
A primary feature of trtserver is that it allows you to serve different types of models from the same model repository and have those models execute in parallel on a GPU. Trtserver uses CUDA streams to exploit the GPU’s hardware scheduling capabilities to simultaneously execute multiple models. For example, assume your model repository has 2 models; model0 and model1. By default, trtserver loads both models onto the GPU so that simultaneous inference requests for those models will be processed in parallel, as shown figure 3.
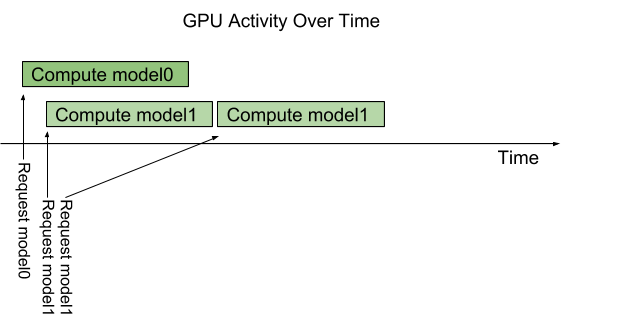
But what if multiple requests for the same model arrive at the inference server at the same time? In that case, by default, trtserver will serialize their execution on the GPU so that only one request is handled at a time as we see in figure 4.
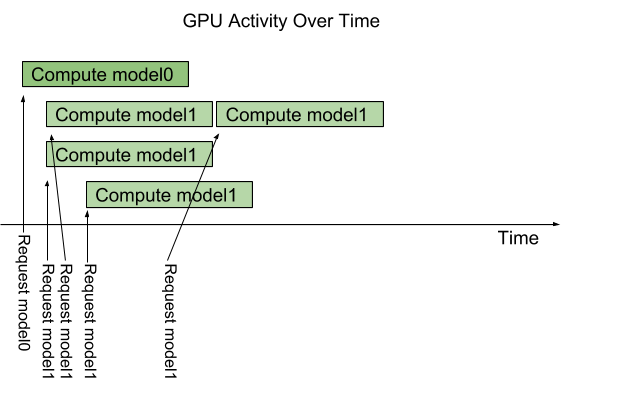
But what if model1 is a popular model? You’d like to exploit the GPU’s compute capabilities to handle multiple model1 inference requests in parallel. Using a feature called instance-group, you can do just that. With instance-group trtserver can execute multiple instances of the same model in parallel. A model’s configuration can include one or more instance-group settings to control how many instances of the model trtserver should run and where those instances should run. For example,
instance_group {
kind: KIND_GPU
count: 3
}
Adding this instance-group setting to model1’s configuration will instruct trtserver to allow up to 3 model1 inference requests to be handled in parallel on the GPU. As figure 5 highlights, multiple model1 inference requests are immediately executed in parallel on the GPU. The forth model1 inference requests must wait until one of the first 3 completes before beginning execution.
You can also use the instance-group feature to instruct trtserver to execute a model on the CPU as long as the model supports it (for example, TensorRT does not support execution on the CPU). Let’s use the instance-group feature to get baseline performance for a TensorFlow ResNet-50 model running on the CPU, and since we are interested in maximizing performance let’s instruct trtserver to handle up to 8 inference requests in parallel.
instance_group {
kind: KIND_CPU
count: 8
}
Now start trtserver with a model repository containing the TensorFlow ResNet-50 model. Use perf_client to see the latency vs. inferences per second results for batch size 1. Use perf_client’s -d flag to increase the concurrency of requests to get different latency and inferences per second values. The -c flag indicates the maximum concurrency to explore and the -l flag indicates the maximum latency in milliseconds.
$ perf_client perf_client -m <resnet-model-name> -d -c8 -l200 -p5000 -b1 Inferences/Second vs. Client Average Batch Latency Concurrency: 1, 10 infer/sec, latency 95602 usec Concurrency: 2, 42 infer/sec, latency 47028 usec Concurrency: 3, 55 infer/sec, latency 54059 usec Concurrency: 4, 63 infer/sec, latency 63288 usec Concurrency: 5, 71 infer/sec, latency 69934 usec Concurrency: 6, 72 infer/sec, latency 82187 usec Concurrency: 7, 76 infer/sec, latency 91463 usec Concurrency: 8, 79 infer/sec, latency 100547 usec
These results demonstrate that trtserver can provide nearly 80 inferences per second for a TensorFlow ResNet-50 model running on the CPU. Now lets run the same TensorFlow ResNet-50 model using the V100 GPU. First we stop the inference server, change the instance-group to indicate that trtserver should allow up to 8 parallel requests to run on the GPU, and then start trtserver again.
instance_group {
kind: KIND_GPU
count: 8
}
Run perf_client again:
$ perf_client -m <resnet-model-name> -d -c8 -l200 -p5000 -b8 Inferences/Second vs. Client Average Batch Latency Concurrency: 1, 267 infer/sec, latency 30008 usec Concurrency: 2, 510 infer/sec, latency 31331 usec Concurrency: 3, 520 infer/sec, latency 46237 usec Concurrency: 4, 635 infer/sec, latency 50439 usec Concurrency: 5, 580 infer/sec, latency 68990 usec Concurrency: 6, 588 infer/sec, latency 82739 usec Concurrency: 7, 587 infer/sec, latency 94802 usec Concurrency: 8, 617 infer/sec, latency 104981 usec
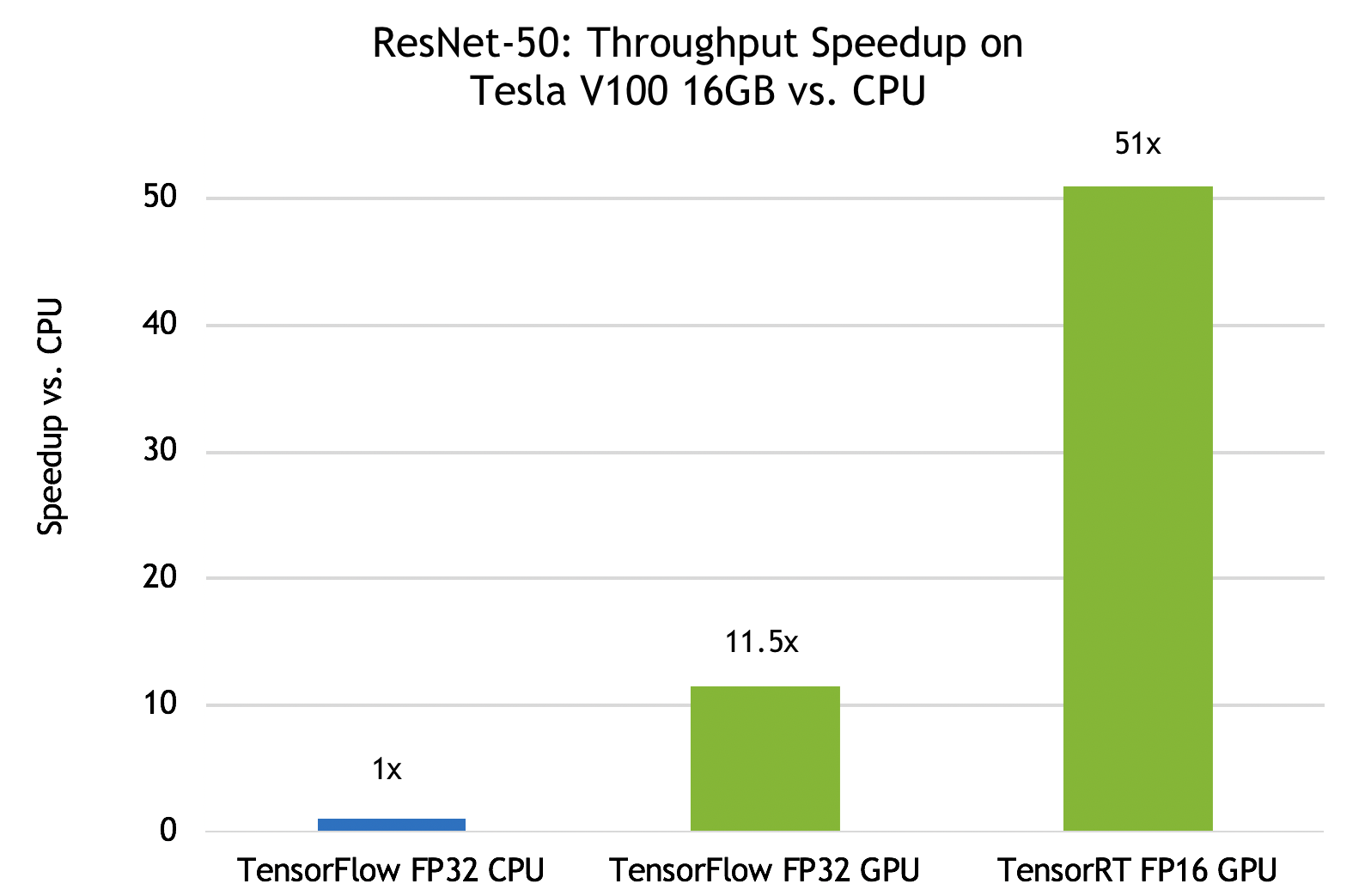
If we choose a latency limit of about 50 milliseconds the results shows that the V100 GPU allows trtserver to deliver over 11x speedup in inferences using a TensorFlow model TF_NEED_CUDA compared to CPU.
Trtserver also supports TensorRT models optimized to use FP16 precision to take advantage of Tensor Cores in V100. Let’s run an FP16 version of the TensorRT ResNet-50 model and compare it to the FP32 TensorFlow versions. The V100 Tensor Cores are so efficient that trtserver needs to run 12 simultaneous inferences to fully utilize the GPU. With FP16, trtserver delivers an inference per second speedup of over 50x compared to a TensorFlow CPU execution with an average latency of only 34 milliseconds compared to 54 milliseconds for the CPU. Trtserver delivers an inferences per second speedup of 4.5x compared to a TensorFlow GPU execution and still delivers much lower average latency.
$ perf_client -m <resnet-model-name> -d -c12 -l200 -p5000 -b8 Inferences/Second vs. Client Average Batch Latency Concurrency: 1, 616 infer/sec, latency 12984 usec Concurrency: 2, 1138 infer/sec, latency 14052 usec Concurrency: 3, 1509 infer/sec, latency 15901 usec Concurrency: 4, 1872 infer/sec, latency 17087 usec Concurrency: 5, 1941 infer/sec, latency 20635 usec Concurrency: 6, 2205 infer/sec, latency 21725 usec Concurrency: 7, 2224 infer/sec, latency 25155 usec Concurrency: 8, 2413 infer/sec, latency 26473 usec Concurrency: 9, 2626 infer/sec, latency 27510 usec Concurrency: 10, 2709 infer/sec, latency 29481 usec Concurrency: 11, 2802 infer/sec, latency 31389 usec Concurrency: 12, 2832 infer/sec, latency 33940 usec
Figure 7 graphically summarizes the above speedup results. The results show the impressive inferencing speedups possible using both TensorFlow and TensorRT models when you exploit trtserver to fully utilize the V100 GPU. Going beyond a single GPU, trtserver can manage multiple heterogeneous GPUs on a single server. Triton Server is also designed to work well with orchestration platforms such as Kubernetes on NVIDIA GPUs to maximize inference performance in your production data center and cloud environments. We will cover those workflows and capabilities in a future blog.
Try Triton Server Today
Triton Server provides an easy-to-use, production-ready inference solution for your data center or cloud. You can experiment with the beta release now by downloading it from the NVIDIA GPU Cloud container registry. Learn more about Triton Server in the Release Notes and the User Guide. Don’t forget to check out the client libraries and example on the GitHub repo.
Use the comment section below to let us know about interesting ways you plan to leverage trtserver for your inference solution. Head over to the DevTalk forum to ask questions and engage with the NVIDIA developer community on this topic.
Update:
The release version of Triton Server is now available as a ready-to-deploy container with monthly updates from the NGC container registry.
TRITON Server is also available as an open source project on GitHub, allowing you to customize, extend, and integrate it into your specific workflows. You can learn more and find links to the developer documentation in this NVIDIA Developer News post.