The Nsight suite of profiling tools now supersedes the NVIDIA Visual Profiler (NVVP) and nvprof. Let’s look at what this means for NVIDIA Visual Profiler or nvprof users. Before diving in, let’s first review what is not changing. The Assess, Parallelize, Optimize, Deploy (“APOD”) methodology is the same. When profiling a workload you will continue to look for unnecessary synchronization events, opportunities to overlap compute with data movement, etc. The data you are already familiar with are still available, including kernel statistics and the timeline view.
So why change tools? Nsight Systems and Nsight Compute split system-level application analysis and individual CUDA kernel-level profiling into separate tools. This allows each to focus on its particular domain without compromise. The Nsight Systems GUI provides dramatic increases in responsiveness and scalability with the size of the profile. You can visualize significantly more information at a glance from the timeline. Nsight Systems also enables a holistic view of the entire system, CPU, GPU, OS, runtime, and the workload itself, reflecting that real world performance is multifaceted and not just a matter of making a single kernel go fast. This is all done with low overhead profile collection and minimal perturbation.
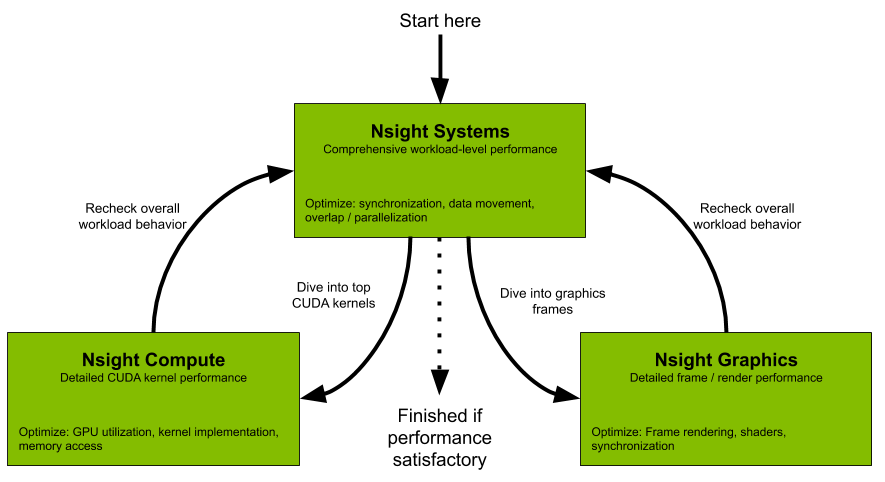
Your profiling workflow will change to reflect the individual Nsight tools, as figure 1 shows. Start with Nsight Systems to get a system-level overview of the workload and eliminate any system level bottlenecks, such as unnecessary thread synchronization or data movement, and improve the system level parallelism of your algorithms. Once you have done that, then proceed to Nsight Compute or Nsight Graphics to optimize the most significant CUDA kernels or graphics workloads, respectively. Periodically return to Nsight Systems to ensure that you remain focused on the largest bottleneck. Otherwise the bottleneck may have shifted and your kernel level optimizations may not achieve as high of an improvement as expected.
This article describes how to get the same system-wide actionable insights that you know how to get from the NVIDIA Visual Profiler and nvprof with Nsight Systems. Check the NVIDIA Developer Blog for future posts on how to transition your kernel-level profiling to Nsight Compute from the Visual Profiler or nvprof.
Some of the Nsight Systems features used in this article require version 2019.3.6 or later. The section “How to Get Nsight Systems” at the end of this article describes how to install and setup Nsight Systems.
Sample Code
Nsight Systems enables many types of performance analyses. This article focuses on a particular case, unified memory data movement. Let’s use the vector addition code from the Even Easier Introduction to CUDA article as the starting point. A related article uses nvprof to understand why the vector addition code does not perform as expected on Pascal and later GPUs. To briefly recap, the data is initialized on the CPU, so the Page Migration Engine in Pascal and later GPUs stalls the kernel when the data is first accessed on the GPU. The data movement time is thus accounted as part of the kernel execution time.
The article describes several solutions. Let’s use cudaMemPrefetchAsync() to move the data to the GPU after initializing it. Prefetching is controlled by an environment variable in the sample code, so we can easily toggle the behavior at runtime.
#include <iostream>
#include <math.h>
#include <stdlib.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Prefetch the data to the GPU
char *prefetch = getenv("__PREFETCH");
if (prefetch == NULL || strcmp(prefetch, "off") != 0) {
int device = -1;
cudaGetDevice(&device);
cudaMemPrefetchAsync(x, N*sizeof(float), device, NULL);
cudaMemPrefetchAsync(y, N*sizeof(float), device, NULL);
}
// Run kernel on 1M elements on the GPU
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
We already know what the problem is in this case. We’ll focus on showing how you would use Nsight Systems to identify the issue and compare that to the Visual Profiler and nvprof.
Begin by compiling the sample code:
$ nvcc -o add_cuda add.cu
Command Line
nvprof
First, let’s profile the code with nvprof. To disable the prefetching, set the environment variable __PREFETCH=off.
$ __PREFETCH=off nvprof ./add_cuda
======== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 100.00% 2.6865ms 1 2.6865ms 2.6865ms 2.6865ms add(int, float*, float*)
API calls: 95.47% 273.61ms 2 136.81ms 23.876us 273.59ms cudaMallocManaged
1.59% 4.5653ms 4 1.1413ms 1.1273ms 1.1573ms cuDeviceTotalMem
1.58% 4.5279ms 388 11.669us 109ns 1.4688ms cuDeviceGetAttribute
0.94% 2.6913ms 1 2.6913ms 2.6913ms 2.6913ms cudaDeviceSynchronize
0.29% 842.31us 2 421.16us 344.15us 498.16us cudaFree
0.10% 288.73us 4 72.182us 69.703us 76.404us cuDeviceGetName
0.02% 45.233us 1 45.233us 45.233us 45.233us cudaLaunchKernel
0.00% 10.036us 4 2.5090us 1.2670us 5.6930us cuDeviceGetPCIBusId
0.00% 2.8900us 8 361ns 143ns 977ns cuDeviceGet
0.00% 1.5220us 3 507ns 144ns 752ns cuDeviceGetCount
0.00% 802ns 4 200ns 169ns 241ns cuDeviceGetUuid
======== Unified Memory profiling result:
Device "Tesla V100-PCIE-32GB (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
138 59.362KB 4.0000KB 980.00KB 8.000000MB 988.4800us Host To Device
24 170.67KB 4.0000KB 0.9961MB 4.000000MB 347.1680us Device To Host
9 - - - - 2.670272ms Gpu page fault groups
Total CPU Page faults: 36
As you can see, the time spent in the add kernel is much greater than expected and there are many small and irregularly sized host to device data transfers. This is the same result reported in the previous article.
The add kernel time is significantly less (17.7 microseconds versus 2.68 milliseconds) after enabling prefetching. The data is transferred from the host to the device in four 2MB chunks (versus 138 memory copies ranging from 4 to 980 KB).
$ nvprof ./add_cuda
======== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 100.00% 17.728us 1 17.728us 17.728us 17.728us add(int, float*, float*)
API calls: 95.91% 269.71ms 2 134.86ms 32.276us 269.68ms cudaMallocManaged
1.68% 4.7258ms 4 1.1814ms 1.1511ms 1.2284ms cuDeviceTotalMem
1.53% 4.3109ms 388 11.110us 110ns 1.2183ms cuDeviceGetAttribute
0.26% 722.86us 1 722.86us 722.86us 722.86us cudaDeviceSynchronize
0.25% 716.55us 2 358.27us 284.21us 432.34us cudaFree
0.23% 657.90us 2 328.95us 159.43us 498.47us cudaMemPrefetchAsync
0.10% 289.95us 4 72.487us 68.495us 81.224us cuDeviceGetName
0.02% 45.400us 1 45.400us 45.400us 45.400us cudaLaunchKernel
0.00% 9.9210us 4 2.4800us 1.3870us 4.6180us cuDeviceGetPCIBusId
0.00% 3.6270us 1 3.6270us 3.6270us 3.6270us cudaGetDevice
0.00% 2.7870us 8 348ns 137ns 685ns cuDeviceGet
0.00% 1.5030us 3 501ns 255ns 707ns cuDeviceGetCount
0.00% 794ns 4 198ns 165ns 258ns cuDeviceGetUuid
======== Unified Memory profiling result:
Device "Tesla V100-PCIE-32GB (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
4 2.0000MB 2.0000MB 2.0000MB 8.000000MB 704.8960us Host To Device
24 170.67KB 4.0000KB 0.9961MB 4.000000MB 347.3600us Device To Host
Total CPU Page faults: 36
Nsight Systems
Nsight Systems can also generate the information needed to diagnose the issue.
The --stats=true command line option outputs profiling information similar to nvprof.
$ __PREFETCH=off nsys profile -o noprefetch --stats=true ./add_cuda ... Generating cuda API Statistics... cuda API Statistics Time(%) Time (ns) Calls Avg (ns) Min (ns) Max (ns) Name ---------- ------------ ---------- -------------- ------------ ------------ --------------------------------- 98.7 258039072 2 129019536.0 31645 258007427 cudaMallocManaged 0.9 2451177 1 2451177.0 2451177 2451177 cudaDeviceSynchronize 0.3 822298 2 411149.0 397325 424973 cudaFree 0.0 46178 1 46178.0 46178 46178 cudaLaunchKernel Generating cuda Kernel and Memory Operation Statistics... cuda Kernel Statistics Time(%) Time (ns) Instances Avg (ns) Min (ns) Max (ns) Name ---------- ------------ ---------- -------------- ------------ ------------ --------------------------------- 100.0 2600399 1 2600399.0 2600399 2600399 add cuda Memory Operation Statistics (time) Time(%) Time (ns) Operations Avg (ns) Min (ns) Max (ns) Name ---------- ------------ ---------- -------------- ------------ ------------ --------------------------------- 75.8 1089824 179 6088.4 2304 82432 [CUDA Unified Memory memcpy HtoD] 24.2 348192 24 14508.0 1632 80608 [CUDA Unified Memory memcpy DtoH] cuda Memory Operation Statistics (bytes) Total Bytes (KB) Operations Avg (KB) Min (bytes) Max (KB) Name ---------------- -------------- ---------------- ---------------- ---------------- --------------------------- 8192.0 179 45.7654 4096 968.0 [CUDA Unified Memory memcpy HtoD] 4096.0 24 170.6667 4096 1020.0 [CUDA Unified Memory memcpy DtoH] ...
The CUDA kernel and memory operation statistics are the same as we got from nvprof with prefetching disabled. The add kernel time is 2.6 milliseconds and we see many (179) small host to device data transfers. When prefetching is disabled, the number and size distribution of the host to device memory copies varies from run to run, so the difference between the run profiled with nvprof (138 with average size of 59 KB) and the run profiled with Nsight Systems (179 with average size of 46 KB) is expected.
Nsight Systems reduces profiling overhead and keeps focus on the workload itself by only reporting the CUDA functions directly invoked by the workload. The CUDA API table does not include the unactionable CUDA driver APIs called from inside the CUDA library, such as cuDeviceGetUuid(). Driver APIs called in the workload itself would be traced by Nsight Systems, but that is not the case here.
Repeating the same Nsight Systems workflow for the case with prefetching enabled reveals a similar reduction in the add kernel time and change in the host to device data transfer behavior.
$ nsys profile -o prefetch --stats=true ./add_cuda Generating cuda API Statistics... cuda API Statistics Time(%) Time (ns) Calls Avg (ns) Min (ns) Max (ns) Name ---------- ------------ ---------- -------------- ------------ ------------ --------------------------------- 98.9 266741347 2 133370673.5 58932 266682415 cudaMallocManaged 0.4 1019086 2 509543.0 420979 598107 cudaFree 0.4 978835 1 978835.0 978835 978835 cudaDeviceSynchronize 0.3 827827 2 413913.5 249549 578278 cudaMemPrefetchAsync 0.0 48073 1 48073.0 48073 48073 cudaLaunchKernel Generating cuda Kernel and Memory Operation Statistics... cuda Kernel Statistics Time(%) Time (ns) Instances Avg (ns) Min (ns) Max (ns) Name ---------- ------------ ---------- -------------- ------------ ------------ --------------------------------- 100.0 17504 1 17504.0 17504 17504 add cuda Memory Operation Statistics (time) Time(%) Time (ns) Operations Avg (ns) Min (ns) Max (ns) Name ---------- ------------ ---------- -------------- ------------ ------------ --------------------------------- 67.2 709280 4 177320.0 172256 180416 [CUDA Unified Memory memcpy HtoD] 32.8 346560 24 14440.0 1632 80192 [CUDA Unified Memory memcpy DtoH] cuda Memory Operation Statistics (bytes) Total Bytes (KB) Operations Avg (KB) Min (bytes) Max (KB) Name ---------------- -------------- ---------------- ---------------- ---------------- --------------------------- 8192.0 4 2048.0 2097152 2048.0 [CUDA Unified Memory memcpy HtoD] 4096.0 24 170.6667 4096 1020.0 [CUDA Unified Memory memcpy DtoH]
Extending the Summary Statistics
The ability to generate custom summary reports is a very useful feature of Nsight Systems. An SQLite database with all the profiling information can be generated using the --export=sqlite command line option. You can query the database to extract additional insights. For example, a histogram of the host to device data transfers could be useful.
The following SQL query sets up a few useful views based on the tables containing the raw memcpy and memset results (refer to the documentation folder in your Nsight Systems installation for a description of the database schema) and then outputs the histogram, including the number of instances, total time, and average bandwidth.
# Lookup table for description of memory operation by copyKind index
# /Documentation/nsys-exporter/exported_data.html#cuda-copykind-enum
DROP TABLE IF EXISTS MemcpyOperationStrings;
CREATE TABLE MemcpyOperationStrings (id INTEGER PRIMARY KEY, name TEXT);
INSERT INTO MemcpyOperationStrings (id, name) VALUES
(0, '[CUDA memcpy Unknown]'), (1, '[CUDA memcpy HtoD]'),
(2, '[CUDA memcpy DtoH]'), (3, '[CUDA memcpy HtoA]'),
(4, '[CUDA memcpy AtoH]'), (5, '[CUDA memcpy AtoA]'),
(6, '[CUDA memcpy AtoD]'), (7, '[CUDA memcpy DtoA]'),
(8, '[CUDA memcpy DtoD]'), (9, '[CUDA memcpy HtoH]'),
(10, '[CUDA memcpy PtoP]'), (11, '[CUDA Unified Memory memcpy HtoD]'),
(12, '[CUDA Unified Memory memcpy DtoH]'),
(13, '[CUDA Unified Memory memcpy DtoD]');
-- type 0=memcpy, 1=memset
CREATE VIEW IF NOT EXISTS _cudaMemcpyStats AS
SELECT 0 AS type, count(copyKind) AS num, min(end-start) AS min,
max(end-start) AS max, avg(end-start) AS avg,
sum(end-start) AS total, name as Name, bytes
FROM CUPTI_ACTIVITY_KIND_MEMCPY
INNER JOIN MemcpyOperationStrings ON
MemcpyOperationStrings.id = CUPTI_ACTIVITY_KIND_MEMCPY.copyKind
GROUP BY copyKind, bytes;
CREATE VIEW IF NOT EXISTS _cudaMemsetStats AS
SELECT 1 AS type, count(*) AS num, min(end-start) AS min,
max(end-start) AS max, avg(end-start) AS avg,
sum(end-start) AS total, '[CUDA memset]' as Name, bytes
FROM CUPTI_ACTIVITY_KIND_MEMSET
GROUP BY bytes;
-- combined memory operations
CREATE VIEW IF NOT EXISTS _cudaMemoryOperationStats AS
SELECT * FROM _cudaMemcpyStats UNION ALL SELECT * from _cudaMemsetStats;
.mode column
.headers on
SELECT bytes, num AS 'Count', total AS 'Total Time (ns)',
ROUND(CAST(bytes AS float)/CAST(total AS float)*(1e9/1024/1024),1)
AS 'Bandwidth (MB/s)'
FROM _cudaMemoryOperationStats WHERE Name LIKE '%HtoD%' ORDER BY bytes;
The output for the case where prefetching is disabled is:
$ sqlite3 noprefetch.sqlite < histogram.sql bytes Count Total Time (ns) Bandwidth (MB/s) ---------- ---------- --------------- ---------------- 4096 86 228448 17.1 8192 22 65856 118.6 12288 17 54048 216.8 16384 5 18176 859.7 20480 3 11552 1690.7 24576 4 17088 1371.6 28672 1 4512 6060.2 32768 2 9664 3233.7 36864 4 21056 1669.7 40960 2 11200 3487.7 45056 4 23296 1844.5 49152 5 31584 1484.1 53248 2 12992 3908.7 57344 1 6816 8023.4 61440 1 7168 8174.4 65536 4 30144 2073.4 69632 2 15680 4235.1 77824 1 8416 8818.8 86016 1 9952 8242.7 110592 1 11104 9498.3 114688 1 11456 9547.4 122880 1 12064 9713.8 196608 1 18112 10352.3 380928 1 33312 10905.4 405504 1 35552 10877.6 409600 1 35552 10987.4 458752 1 39136 11179.0 856064 1 71424 11430.4 860160 1 72192 11362.9 958464 1 79840 11448.7 991232 1 82432 11467.8
The histogram for the case when prefetching is enabled shows a single data size:
$ sqlite3 prefetch.sqlite < histogram.sql bytes Count Total Time (ns) Bandwidth (MB/s) ---------- ---------- --------------- ---------------- 2097152 4 709280 2819.8
The Nsight Systems statistics produced by --stats=true can be regenerated by running the statistics scripts bundled with Nsight Systems on the SQLite database. For example, the cudaGPUSummary script produces the CUDA kernel and memory operation tables.
Graphical User Interface
Both the NVIDIA Visual Profiler and Nsight Systems can profile a workload directly from the graphical user interface (GUI). However, here we collect the profile on the command line and import it into the GUI. This workflow is common when the workload is run on a shared, remote system and the profile is to be visualized locally.
Visual Profiler
First, collect the profile with nvprof with prefetching disabled.
$ __PREFETCH=off nvprof -o noprefetch.prof ./add_cuda ==29770== NVPROF is profiling process 29770, command: ./add_cuda Max error: 0 ==29770== Generated result file: noprefetch.prof
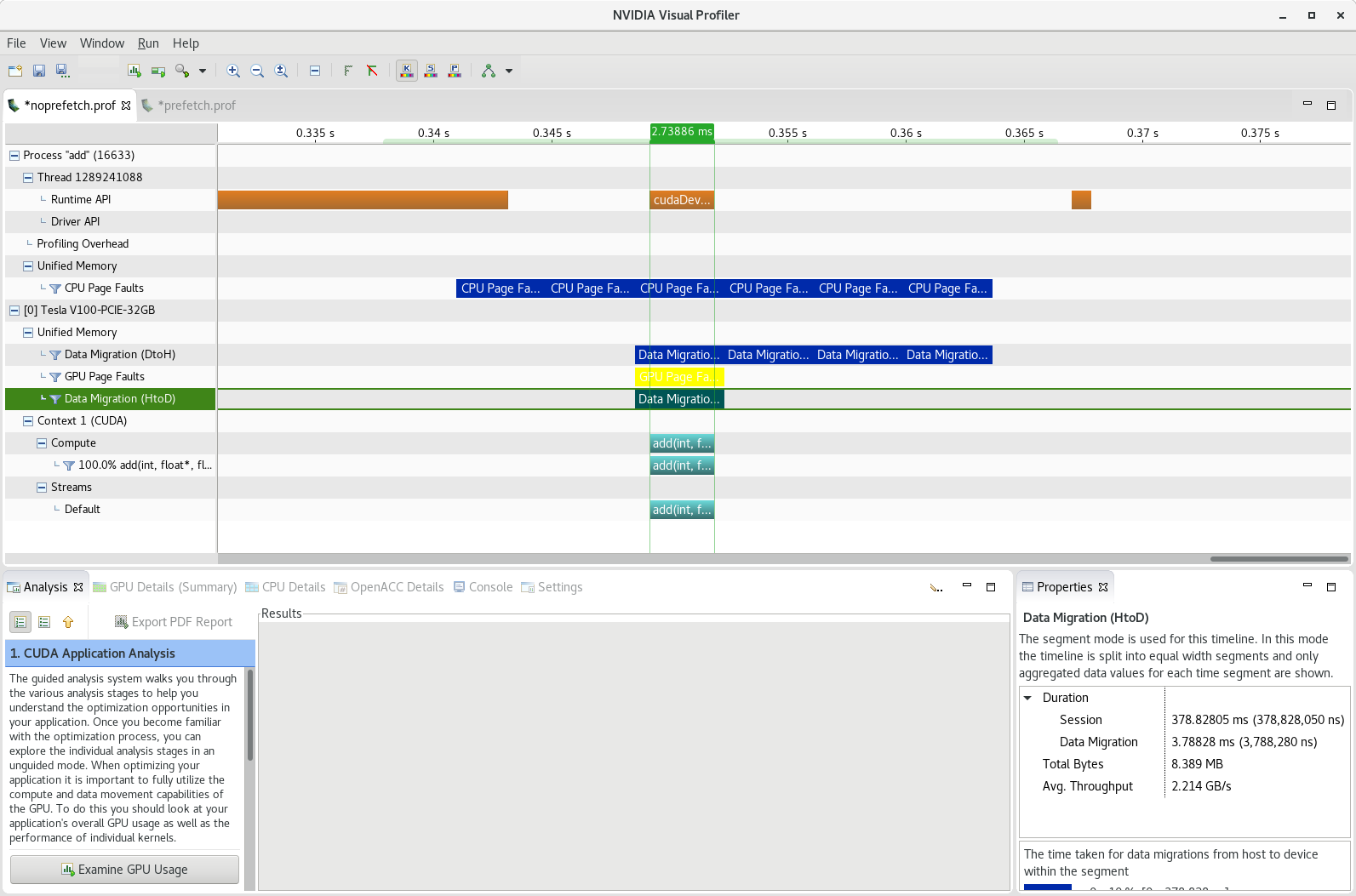
Transfer the file to your local system and import the nvprof profile into the NVIDIA Visual Profiler. The timeline in figure 2 shows the overlap of the host to device data movement with the add kernel, i.e., the data is being migrated as it is being accessed on the GPU.
Nsight Systems
The qdrep file collected in the Command Line section can be directly loaded in the Nsight Systems GUI. (Unlike nvprof, Nsight Systems generates a profile data file, or qdrep file, by default.) The timeline view is very similar to the NVIDIA Visual Profiler. Additional information about the runtime OS libraries is also available, but is not relevant to this particular example.
The row labeled “CUDA (Tesla V100-PCI3-32GB)” shows a high level summary of the data movement (red) and compute kernel (blue) activity. The height of the bars is an indicator of the relative intensity. The areas of particular interest are highlighted in an orange rectangle.
As we saw in the NVIDIA Visual Profiler, the host to device data movement overlaps with the add kernel. Normally overlapping data movement and compute is highly desirable. However, in this case, the compute kernel stalls while it waits for the data to be moved to the GPU, which is why the compute kernel time is much larger when prefetching is disabled. If the sample code was extended to run multiple kernels then overlapping data movement and compute would be effective, e.g., the data for the next kernel could be prefetched while the current kernel is executing. Figure 3 shows that each of the 179 memory copies is reported individually rather than as a single Data Migration transaction as shown in the Visual Profiler.
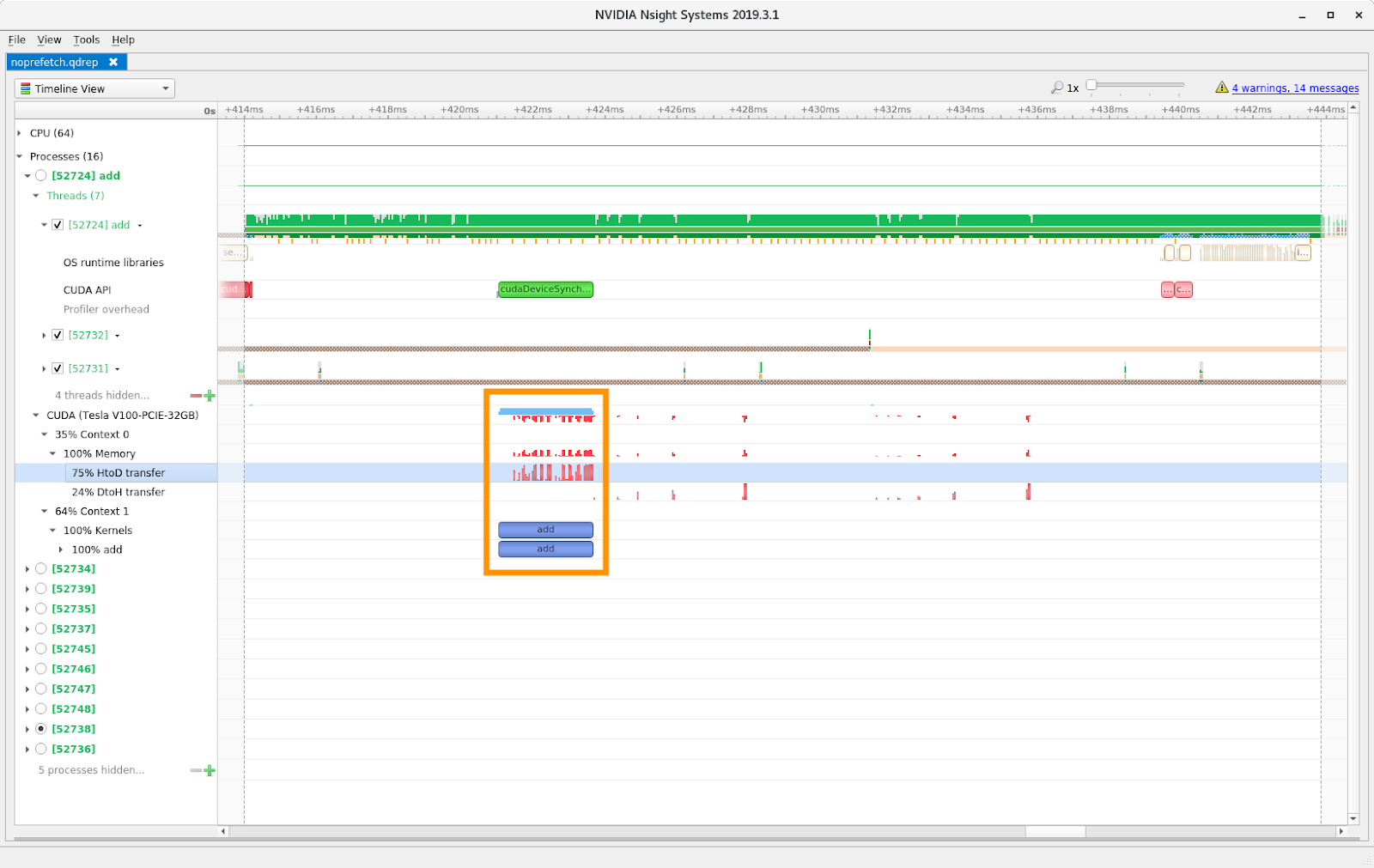
The host to device data transfer occurs before the add compute kernel with prefetch enabled, greatly reducing the compute kernel time, as shown in figure 4. No overlap exists any longer between the data movement and the compute kernel. The unified memory pages now reside on the GPU and any subsequent kernels could re-use the pages without any additional data movement.

Conclusion
This simple sample code shows that the basic information obtained from NVIDIA Visual Profiler and nvprof can also be found in Nsight Systems. Despite the procedural differences, the key data used to understand the performance of a workload is the same, namely the kernel time and data transfer statistics on the command line and the timeline GUI view.
Additional features of Nsight Systems not covered here include:
- OS runtime library tracing
- Tracing of cuBLAS, cuDNN, TensorRT, and other CUDA accelerated libraries
- OpenACC tracing
- OpenGL and Vulkan tracing (DirectX 12/DXR on Windows)
- User specified annotations using NVTX
- Supports any workload programming language or Deep Learning framework, including C/C++, Fortran, Python, Caffe, PyTorch, and TensorFlow.
- Usable with MPI workloads
- Low overhead profiling with minimum workload perturbation
- Highly responsive GUI that scales with the profile size
How to Get Nsight Systems
Nsight Systems is included with the CUDA toolkit version 10.1 or later. You can also download the latest version of Nsight Systems from the NVIDIA Developer portal.
Refer to the User Guide for installation and setup information; in particular, you may want to add the directory containing the nsys command line tool to your PATH to most easily use Nsight Systems.