By Michael Wang, The University Of Melbourne, Australia (GTC ’12 Guest Blogger)
 It’s 9 am, the first morning session of the pre-conference Tutorial Day. The atmosphere in the room is one of quiet anticipation. NVIDIA’s Will Ramey takes the stage and says: “this is going to be a great week.”
It’s 9 am, the first morning session of the pre-conference Tutorial Day. The atmosphere in the room is one of quiet anticipation. NVIDIA’s Will Ramey takes the stage and says: “this is going to be a great week.”
I couldn’t agree more. A quick show of hands reveals that more than 90% of the 200-strong audience had used CUDA in the past week. The prophetic words of Jack Dongarra aptly sum up why we are all here:
GPUs have evolved to the point where many real-world applications are easily implemented on them and run significantly faster than on multi-core systems. Future computing architectures will be hybrid systems with parallel-core GPUs working in tandem with multi-core CPUs.
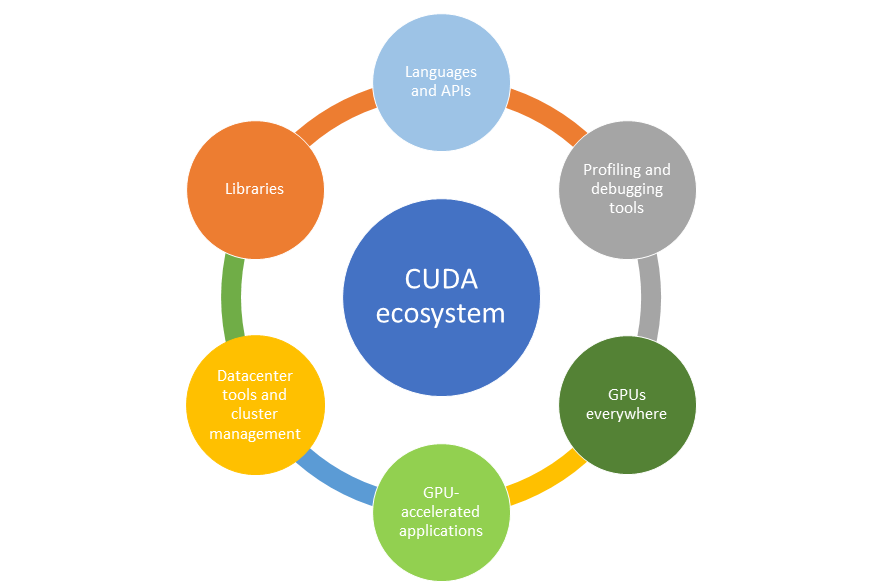
And things couldn’t be easier if you consider the three broad categories of tools available to you today:
- CUDA-accelerated libraries (e.g. cuFFT, cuBLAS, NPP, Thrust, etc);
- OpenACC directives (for C and Fortran);
- CUDA-enabled programming languages (e.g. CUDA C/C++, CUDA Fortran, PyCUDA, etc).
Dealing with these aspects in turn, Will first outlined the clear advantages in terms of both performance and usability of the CUDA libraries. NVIDIA-developed libraries such as CuFFT, CuBLAS and CuSPARSE saw consistent speed-ups of around 6x to more than 10x over Intel MKL using current generation hardware (see https://developer.nvidia.com/gpu-accelerated-libraries).
Users can take advantage of CUDA-accelerated libraries in a “drop-in” fashion by simply calling the appropriate GPU library functions when there is an NVIDIA GPU present. With only a few extra lines of code, the programmer can instantly access these order-of-magnitude performance boosts provided by the GPU, truly “in tandem” with their existing CPU codebase.
In many applications where nested loops are a bottleneck, OpenACC comes to the rescue. A familiar #Pragmadirective in your C or a !$Acc in Fortran code (see https://developer.nvidia.com/openacc) tells the compiler to spawn thousands of threads to concurrently process those loop iterations rather than a single thread running serially. Early users have reported astounding productivity gains in the order of 2x in just 4 hours (for a Monte Carlo-based finance algorithm). OpenACC will not only target GPUs but also multicore CPUs, Intel MIC and FPGAs.
For maximum flexibility, we of course have recourse to the CUDA programming languages. Both C/C++ and Fortran are currently supported. Writing CUDA code allows you to really get your parallel performance juices flowing—with control over everything the CUDA API offers, from managing individual threads to highly optimized memory operations—you can squeeze that last FLOP out of your kernel if you so choose.
To assist the programmer in this endeavor, Will revealed a sneak peek of the newly-announced Nsight Eclipse Edition IDE for Linux and Mac. Together with Nsight for Visual Studio, these round out the suite of development, profiling and debugging tools for all major OSes. Along with 3rd party cluster-class job management tools, parallel jobs scaling out to 10s and 100s of thousands of nodes can be debugged on a per-thread basis.
Visit https://developer.nvidia.com/ to get started.
Be sure to watch the streamcast of this presentation.
About our Guest Blogger
 Michael Wang is a Ph.D. candidate at The University of Melbourne, Australia, and an organizer of the Melbourne GPU Users Meetup.
Michael Wang is a Ph.D. candidate at The University of Melbourne, Australia, and an organizer of the Melbourne GPU Users Meetup.