To me, photography is the simultaneous recognition, in a fraction of a second, of the significance of an event. — Henri larartier Bresson
As a child I waited anxiously for the arrival of each new issue of National Geographic Magazine. The magazine had amazing stories from around the world, but the stunningly beautiful photographs were more important to me. The colors, shadows and composition intrigued and wowed me, and there was a cohesion of visual arrangement and storytelling.
This childhood fascination with photographs aroused in me a curiosity to understand the behavior, nuances and semantics embedded inside them. Ultimately, this curiosity drove me to study computer vision, which is empowering me to develop systems for understanding images from a computational and scientific perspective. Further, my job at EyeEm allows me to interact with technologists, designers, photo curators, photographers and product managers who are busy building the photography of the future!
EyeEm is a community and marketplace for passionate photographers. More than 15 million photographers use EyeEm to share their photos, connect with other photographers, improve their skills, get recognition through our photography missions and exhibitions, and earn money by licensing their photos. The following video shows the impact of our deep-learning-based automatic aesthetic curation on the EyeEm search experience—read on to learn more about how it is done.
At EyeEm we develop technology that helps photographers tell their stories and get discovered. We believe there are two ingredients that contribute to the success of a photograph: 1) the story behind the photograph, and 2) the way that story is told. Automatic image tagging technologies from companies like EyeEm, Google Cloud Vision, Flickr, and Clarifai are quickly approaching maturity and helping to tell the stories behind photographs by indexing or tagging them to make them discoverable. Visual aesthetics addresses the way each story is told; specifically, how the visual style and composition create an emotional connection with the viewer by using structure and cues that draw attention toward (and away) from the constituent story elements of the photographer’s choice.

The expression of beauty has been fundamental to the photographic process ever since its invention. For example, Louis Daguerre’s “The Boulevard du Temple,” one of the very first known photographs, is a study of perspective traced by architectural forms. In the period following the first photographs, spanning from before the industrial revolution to the digital age, endless creative, spiritual and technological innovations and techniques for conveying aesthetics have been explored by master photographers.
Our Idea
There are no rules for good photographs, there are only good photographs. — Ansel Adams
To learn about aesthetics, we turned to the masters and their creations. The left and central photos below were taken by EyeEm photographers @aufzehengehen (Jonas Hafner) and @duzochukwu (David Uzochukwu), both pro photographers. In contrast, the image on the right was taken by me, an amateur. Although each image features the same basic content, the difference in visual charm and coherence in the left two pictures versus the right is apparent.

Here’s a similar example for architectural facades.

The question then to ask is what do the master photographers’ images have in common, and what separates them from the amateur images? While it’s difficult for a computer to answer a philosophical question, if we express the question in mathematical terms we can attempt to solve it computationally. In our case, we aim to find a mathematical space in which the distance between the two images that are aesthetically pleasing is less than the distance between an aesthetically pleasing one and a mediocre one, as Figure 1 shows.

However, for any given mathematical formulation, there is no guarantee that a solution exists. Even if a solution exists, for a large class of problems, there often is not an algorithm that can compute the solution exactly in a reasonable amount of time.
In our case, we would have to iterate over all possible photographs ever taken and all possible mathematical spaces to verify if the above stated condition is true. Machine learning solutions, on the other hand, try to model a problem using a finite dataset, with the hope that the model can accurately predict the outcome for not-yet-seen data. In our case, we use supervised machine learning, with a dataset of photographs pre-categorized as aesthetically pleasing or not. Further, we split the dataset into two mutually exclusive parts: a training set used to train our model, and a test set used to evaluate the accuracy and generality of our model.
Even with our reduction of scope to a finite set of data points, there is an infinite number of mathematical spaces we can construct, and an exhaustive search to find the optimal space is intractable. A popular technique in machine learning solutions is to pose this search as a mathematical optimization problem. We quantify the deviation from our expected result as a loss function, and at each iteration we make educated guesses so as to minimize our defined loss function.
Photographs can remain perceptually and conceptually unperturbed by small changes in their dimensions, colors and intensity patterns, and it’s often not clear what changes contribute to a change in the actual information contained a photo. Often our understanding of a picture is influenced heavily by our previous visual stimuli. A much stronger strategy is to transform the image via various mathematical operators into a set of measurements called image features that summarize the visual information that is relevant to our solution, and disregard irrelevant information. Finding a good feature representation manually is hard, but in the recent past Convolutional Neural Networks (CNN) have exhibited tremendous success at automatically determining relevant features directly from training data. For an introduction to deep learning and CNNs, I recommend “Deep Learning in a Nutshell: Core Concepts” by Tim Dettmers, or this online Deep Learning textbook for an in-depth mathematical treatment.
To summarize, to understand aesthetics in photographs we need the following things:
- A feature space that is strong enough to capture the subtleties photographers exploit during the image making process.
- A training dataset, that is as exhaustive as possible, curated by experts with strong understanding of the underlying photos.
- A machine learning framework that can optimize our loss function using the large scale training dataset.
Our Algorithm
Our first reaction in seeing a visual is often instinctive. There is evidence from the field of neuroesthetics that long-range interaction and correlation between spatially separated pixel regions in photographs plays an important role in the underlying aesthetics of a photo [Ramachandran 1999].
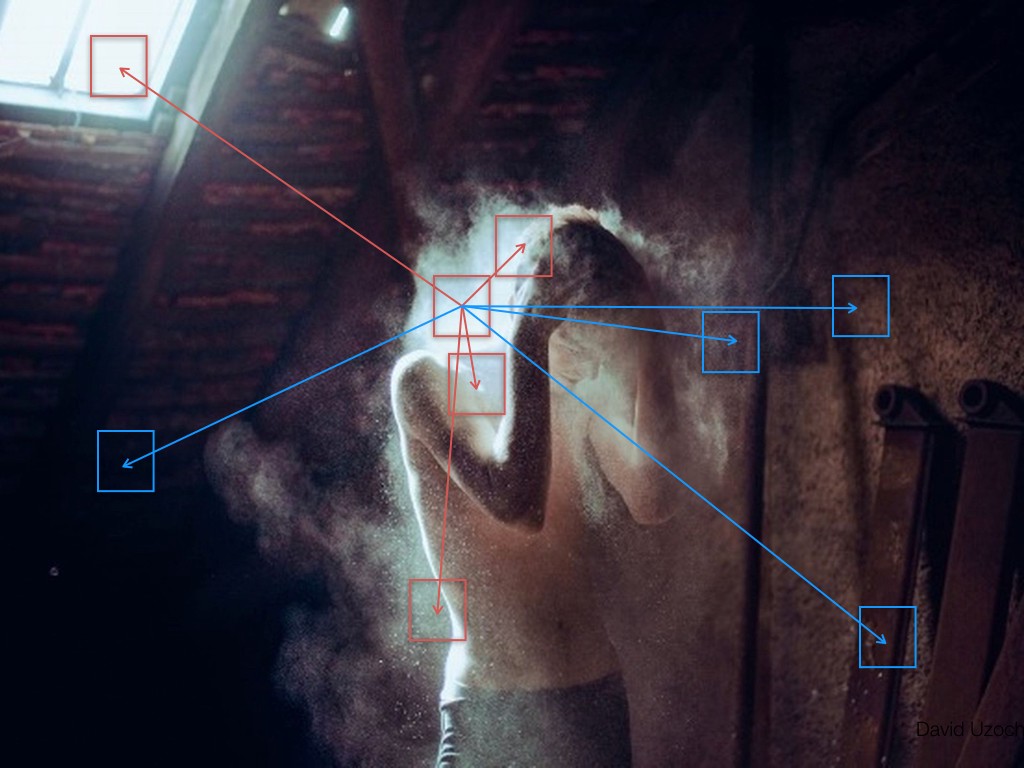
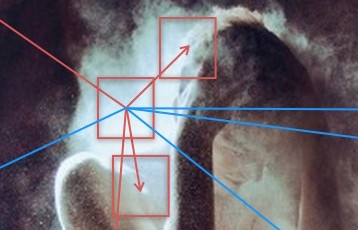
In the photograph by David Uzochukwu in Figure 2 the central patch with red border is similar in appearance to other red-bordered patches within the image, and contrasts itself the most to the blue-bordered patches. Such positive and negative correlations in visual content play an important role in making particular regions stand out. Multiple such interactions at multiple scales contribute toward the final visual appeal of the photograph.
Convolutional neural networks are arranged in layers, and each different layer captures information of a different kind. The first layers, which are close to the input, usually detect low-level information like the presence of edges. But deeper layers can detect much richer forms of information, including the long-range interactions we are trying to capture. Thus, CNNs are an excellent candidate for a feature representation. (You may want to check out this visualization of representations captured in various layers of a convolutional neural network trained as an object detector.)
Our objective is to compare images and learn the commonalities between well-crafted photographs, and the differences between well-crafted and mediocre photos. Thus, for a given triplet of two well-crafted images (

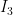





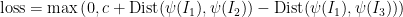
Researchers have explored such loss functions in image similarity, metric learning and face identification settings with great success in the past (Chechik2010 , Norouzi2011, Schroff2015). In a larger context, such energy functions fall into the class of implicit regression (LeCun06), where the loss function penalizes the constraint that input variables must satisfy.
During training, we pass each image of the triplet through a separate convolutional neural network (see Figure 3). We experimented with various CNN architectures. An 11 layer Oxford model was sufficient for good convergence and performance. Though there is no direct theoretical motivation, we enforced the weights of the three networks to be the same, since we found this made the networks converge easier. Further, at run time, this allowed us to use a single convolutional network, thus keeping our run time cost low.
Our Training Dataset
One of the key factors contributing to our understanding of aesthetics in photographs is our dataset. Unlike in image classification, understanding and appreciating aesthetics is quite an expert-level task. Our researchers and curators, who are award winning photographers, collaborated deeply to create our training data.
When collecting the positive classes of our training set we set very high standards. We selected only pictures that communicate strong stories with strong composition, and that were shot with technical mastery.
In our earlier works we observed overwhelming evidence that interpreting photography in terms of low-level visual features like color, contrast and composition leads to both a subpar performance and severe overfitting to training data. In an artistic medium like photography, photographers constantly explore and innovate. Photographs that exhibit subtle and controlled deviation from the established rules often evoke strong aesthetics. Thus, we purposely dissuaded the curators from deconstructing the technical aspects, and encouraged them to use their innate visual sense and judgement.
However, before the data collection process various candidate visual examples were split into categories and collected as guidelines, so that curators had a shared understanding of the task. The advantage of convolutional neural networks is that they’re purely data-driven and give us the luxury of not having to hand-specify features, which allows us to work in a non-reductionist framework.
Over 100,000 images were categorized. Since the input to our networks is in the form of triplets, we had around 4 billion triplets. This is a prohibitively large number of triplets, and for the effective convergence of the network we needed to sample our data. Further, not every triplet contributes equally to either the convergence or the final expressibility of our models. The connection of aesthetics with the story being told is often subtle and hard to define, but nevertheless plays an important role. A similarity measure based on keyword detections gives us a good prior in sampling our triplets. We use more than 60 million such triplets for training the final model over 20,000 iterations. We trained our networks using a single NVIDIA Tesla K40 card, which converged in 2 to 3 days.
As a computer vision researcher, the ability to process, learn and iterate quickly on massive datasets is a key in this process. We use the Torch framework to train our networks and the Theano/Keras framework in our production setup. Speed and ease of experimentation were the primary motivations for using Torch for our training setup; whereas ease of integration into our existing infrastructure was the motivation for using Theano/Keras. These libraries build on top of the NVIDIA cuDNN library, which helped us leverage the massive parallel processing capability of GPUs and allowed us to get initial results within a day. Fast results allowed our researchers and curators to constantly interact and help refine and iterate our model architecture and the sampling scheme. This was unimaginable just a few years ago. Without GPUs, training our networks would have taken more than 25 times longer, and iterating to refine the system would have been very difficult.
Applications
One of the largest problems regarding digital images is the sheer volume of photos we produce individually and as a community. A major problem is that genuine artistic content often doesn’t get noticed in the sea of photographs on the Internet. At EyeEm, we use a ranking system based on our trained aesthetic model to promote photographers in our discover feed and to prioritize aesthetically pleasing content in search. The video at the start of the post shows the impact of aesthetics on EyeEm’s internal search product.
As a photography-first company, we validate our assumptions with our internal curators and reviewers, who spend the major part of their working day curating photographs. We track the time they spend on curation tasks where the image list is prioritized via the aesthetic rank vs. the default sort order. Using deep learning, we have been able to reduce curation time by 80%.
Using deep learning rather than pure computer vision enables us to supplement the photographic data with other external signals such as sales data or business and marketing insights, and to provide recommendations and priorities to product, project and business KPI owners so they can abstract data and make easier decisions in complex domains.
Final Words
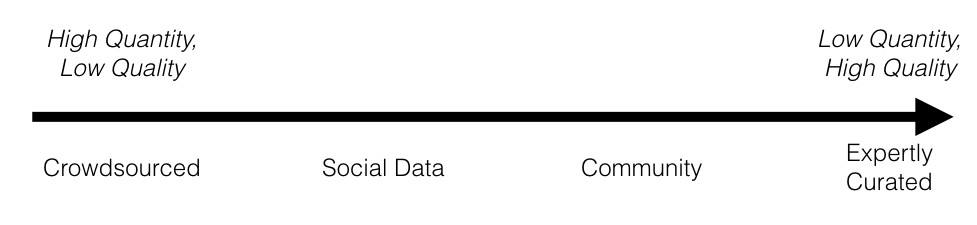
Our goal is to leverage expert opinions over a much larger scale, using more easily available data for tasks like visual aesthetics that require an enormous amount of human intellectual and emotional judgement like visual aesthetics (Figure 4 shows the spectrum of data available to us). Our initial deep learning model using the triple hinge loss function enables a first step in capturing some of the intricacies of these tasks.
At EyeEm we learn constantly from our community, who produce astonishing imagery over and over again; we learn from our photographers and curators, who have a strong innate understanding of visual sense, and we use technology to capture these intellect constructs. We are entering a fascinating nascent stage in which technology can power curation at a large scale, enabling human stories to be discovered within the firehose of photographic data.
As a parting thought, I am including a video about Porter Yates, EyeEm’s 2015 Photographer of the Year. The amount of work and thought Porter puts into creating his images is inspiring to me. For me, a photograph exists in the past, present & future and magic can happen in any of these times. It sure is magical to see what our deep learning models have learned!
References
[Chechik 2010] G. Chechik, V. Sharma, U. Shalit, S. Bengio, Large Scale Online Learnings of Image Similarity Through Ranking, Journal of Machine Learing Research 11, 2010
[Norouzi 2011] M. Norouzi, D. Fleet, Minimal Loss Hashing for Compact Binary Codes, International Conference in Machine Learning (ICML), 2011.
[Schroff 2015] F. Schroff, D. Kalenichenko, J. Philbin , FaceNet: A Unified Embedding for Face Recognition and Clustering, ArXiV : 1503.03832, 2015
[LeCun 2006] Y. LeCun, S. Chopra, R. Hadsell, M. Ranazato, F. J. Huang, A Tutorial on Energy-Based Learning, Predicting Structured Data, 2006
[Ramachandran 1999] V.S. Ramachandra, W. Hirstein , The science of art: a neurological theory of aesthetics experience, Journal of Consciousness Studies, 1999
Acknowledgments
This is joint work with Gökhan Yildirim , Caterina Gilli and Fulya Lisa Neubert.