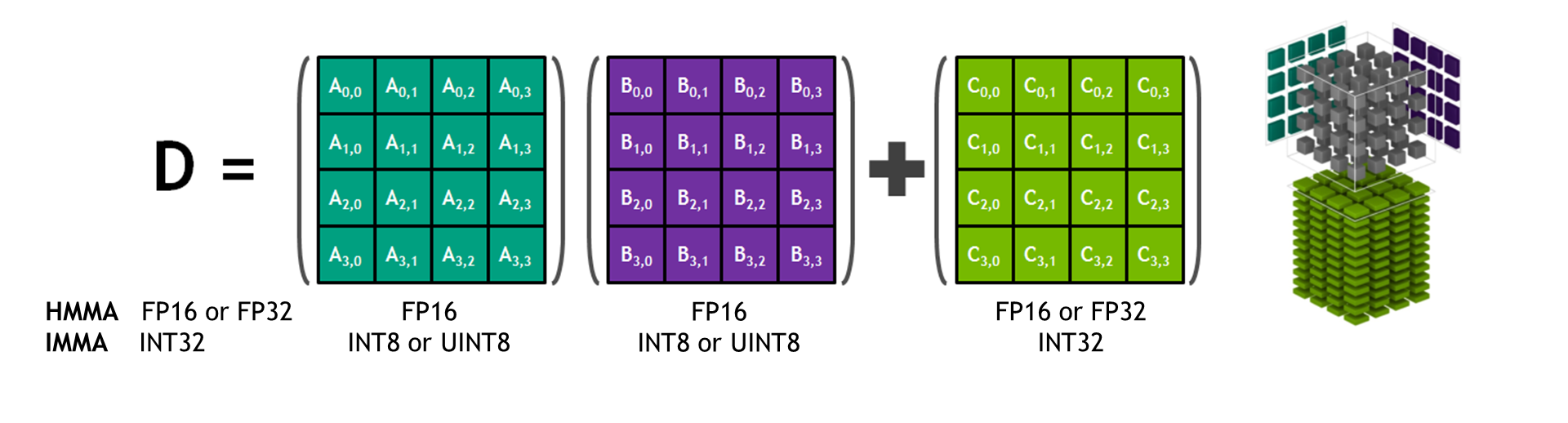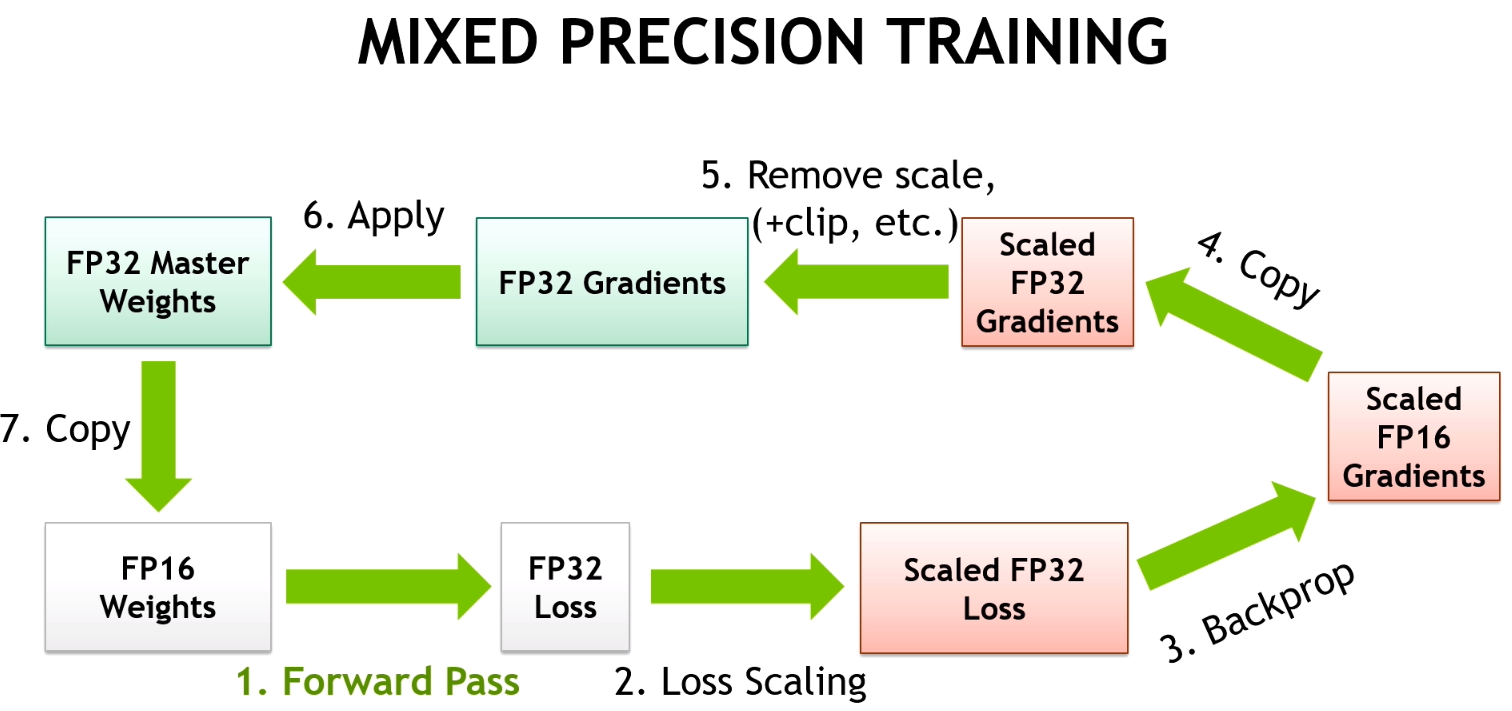
Neural networks with thousands of layers and millions of neurons demand high performance and faster training times. The complexity and size of neural networks continue to grow. Mixed-precision training using Tensor Cores on Volta and Turing architectures enable higher performance while maintaining network accuracy for heavily compute- and memory-intensive Deep Neural Networks (DNNs).
This post will get you started with understanding Tensor Cores, their capabilities for mixed-precision implementation, performance guidelines on how to achieve faster AI performance by using Tensor Cores on Volta GPUs, and training frameworks with video excerpt. Each video is followed by summarized key points. However, it’s highly recommended to watch the following video, which sets up the context for the series.
Part 1: Introduction to Mixed-Precision Training
Paulius Micikevicius gives you an overview of mixed-precision training with Tensor Cores and its benefits in this video.
Key Points:
- Mixed precision training employs a combination of single- and half-precision floating point representations to train a neural network with no loss of accuracy. Example networks capable of training with mixed precision include CNNs, GANs and models for Language Translation and Text to Speech conversion
- Volta and Turing Tensor Cores accelerate key matrix multiplication and convolutional layers
- Accelerating math with Tensor Cores and reducing memory traffic is one benefit of mixed-precision training. Another benefit is lower memory usage which enables larger batch sizes or larger models
Part 2: Using Tensor Cores with PyTorch
Christian Sarofeen walks you through a PyTorch example that demonstrates the steps of mixed-precision training, using Tensor Core-accelerated FP16 arithmetic to maximize speed and minimize memory usage in the bulk of a network, while using FP32 arithmetic at a few carefully chosen points to preserve accuracy and stability.
Key Points:
- We’ve seen the PyTorch community leverage Volta Tensor Cores for mixed-precision training for sentiment analysis, FAIRSeq, GNMT and ResNet-50, delivering end-to-end performance boosts between 2X and 5X versus pure FP32 training with no accuracy loss. We recommend checking the product performance page for the most up-to-date performance data on Tesla GPUs.
- Techniques and tools such as Apex PyTorch extension from NVIDIA assist with resolving half-precision challenges when using PyTorch. Apex utilities simplify and streamline mixed-precision and distributed training in PyTorch. Apex is an open source project and if you’d like more details about Apex, check out NVIDIA Apex developer blog.
Part 3: Using Tensor Cores with TensorFlow
Next up, Ben Barsdell from NVIDIA provides a quick walkthrough detailing mixed-precision benefits leveraged by TensorFlow developers with a CNN model.
Key Points:
- TensorFlow supports mixed precision using tf.float32 and tf.float16 data types
- The benefits of mixed-precision training include reducing memory bandwidth, improving compute performance all while maintaining training accuracy
- The conversions requires less than 10 lines of code for most training scripts. Check out the best practices for mixed-precision using TensorFlow documentation to help you get started with mixed-precision training using Tensor Cores.
Part 4: Considerations for Mixed-Precision Training with Tensor Cores
Next, Paulius Micikevicius provides fundamentals behind implementation decisions for mixed-precision training. This section will interest framework developers, users who want to customize their mixed-precision training to maximize benefits, and researchers working on training numerics.
Key Points:
- Tensor Cores handle convolutions, linear and recurrent layers
- You’ll find guidelines for FP32 master weights and update, reductions, and normalization layers
- Details precision choices for point-wise and loss computations
- The various aspects described in this video can be automated by tools, such as Apex (A PyTorch Extension) for PyTorch.
Part 5: Tensor Cores Performance Guide
Paulius Micikevicius provides information on requirements for triggering Tensor Core operations during neural network training.
Key Points:
- Convolutions: For cuDNN versions earlier than 7.2, number of input channels and number of output channels must be multiples of 8 to trigger Tensor Core usage. Note: For cuDNN versions 7.3 and later, the multiple-of-8 restriction on convolution channel dimensions is lifted, as explained in the Developer Blog.
- Matrix multiplication: M, N, K sizes must be multiples of 8. Larger K sizes make multiplications efficient. Tensor Cores make it practical to have wider neural network layers if needed.
- When designing models to leverage Tensor Cores, ensure that fully-connected layers use multiple-of-8 dimensions. When necessary, pad input/output dictionaries to multiples of 8.
- When developing new cells (LSTMs for instance), concatenating cell matrix operations into a single call can improve performance.
Part 6: How Do I Know if I’m Using Tensor Cores?
Christian Sarofeen highlights a PyTorch code snippet that is running on NVIDIA Visual Profiler
Key Points:
- NVIDIA Visual Profiler reports every single GPU operation and kernels that were executed
- When using Tensor Cores with FP16 accumulation, the string ‘h884’ appears in the kernel name. On Turing, kernels using Tensor Cores may have ‘s1688’ and ‘h1688’ in their names, representing FP32 and FP16 accumulation respectively.
Getting Started
NVIDIA offers developers with a variety of deep learning model scripts with multiple AI frameworks using Tensor Cores. Check out the deep learning model scripts page for more information. You can access these examples via NVIDIA GPU Cloud (NGC) and GitHub. NVIDIA added an automatic mixed precision feature for TensorFlow, PyTorch and MXNet as of March, 2019. Check out the NVIDIA developer page for more information and resources.To get your questions on Tensor Cores or mixed-precision answered, post your questions on NVIDIA Developer Forum, DevTalk. Learn more about Tensor Cores and mixed-precision training by checking out the developer documentation.
Appendix: Additional Useful Mixed-Precision Posts
- Tensor Cores for Developers
- Using Tensor Cores for Mixed-Precision Scientific Computing
- Mixed-Precision training of Neural Networks
- Mixed Precision Training for NLP and Speech Recognition with OpenSeq2Seq
- NVIDIA Apex: Tools for easy mixed precision training with PyTorch
- Inside Volta: The World’s Most Advanced Data Center GPU
- Programming Tensor Cores for Deep Learning